To improve the speed of video recognition applications on edge devices such as NVIDIA’s Jetson Nano and Jetson TX2, MIT researchers developed a new deep learning model that outperforms previous state-of-the-art models in video recognition tasks.
Trained using 1,536 NVIDIA V100 GPUs at Oak Ridge National Laboratory’s Summit supercomputer, the model earned the top spot in the Something-Something video dataset public challenge, winning first place in version 1 and version 2.
Detailed in a research paper set to be presented at the International Conference on Computer Vision in Seoul, Korea, the proposed approach makes use of a Temporal Shift Module framework to achieve the performance of a 3D convolutional neural network, but with the complexity of a 2D CNN.
“Conventional 2D CNNs are computationally cheap but cannot capture temporal relationships; 3D CNN based methods can achieve good performance but are computationally intensive, making it expensive to deploy. In this paper, we propose a generic and effective Temporal Shift Module (TSM) that enjoys both high efficiency and high performance,” the researchers stated in their paper.
According to the team, this approach makes it possible to reduce the model to one-sixth the size by reducing the 150 million parameters in a state-of-the-art model to 25 million parameters.
“Our goal is to make AI accessible to anyone with a low-power device,” says Song Han, an assistant professor at MIT and the paper’s co-author. “To do that, we need to design efficient AI models that use less energy and can run smoothly on edge devices, where so much of AI is moving.”
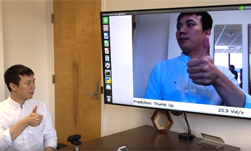
In the video above, Ji Lin, the lead author of this research, shows how a single NVIDIA Jetson Nano, rigged to a video camera, can instantly classify hand gestures with just 12.4 ms latency.
To train this algorithm, the team secured the help of the world’s fastest supercomputer, Summit, at the Oak Ridge National Laboratory. There, Lin and his team trained their model in just 14 minutes using NVIDIA V100 GPUs and the cuDNN-accelerated PyTorch deep learning framework.
“Compute requirements for large AI training jobs are doubling every 3.5 months,” the researchers said. “Our ability to continue pushing the limits of the technology will depend on strategies like this that match hyper-efficient algorithms with powerful machines.”
The researchers have also released a PyTorch implementation of their code on GitHub.