
‘Meet the Researcher’ is a series in which we spotlight different researchers in academia who use NVIDIA technologies to accelerate their work.
This month we spotlight Marco Aldinucci, Full Professor at the University of Torino, Italy, whose research focuses on parallel programming models, language, and tools.
Since March 2021, Marco Aldinucci has been the Director of the brand new “HPC Key Technologies and Tools” national lab at the Italian National Interuniversity Consortium for Informatics (CINI), which affiliates researchers interested in HPC and cloud from 35 Italian universities.
He is the recipient of the HPC Advisory Council University Award in 2011, the NVIDIA Research Award in 2013, and the IBM Faculty Award in 2015. He has participated in over 30 EU and national research projects on parallel computing, attracting over 6M€ of research funds to the University of Torino. He is also the founder of HPC4AI, the competence center on HPC-AI convergence that federates four labs in the two universities of Torino.
What are your research areas of focus?
I like to define myself as a pure computer scientist with a natural inclination for multi-disciplinarity. Parallel and High-Performance Computing is useful when applied to other scientific domains, such as chemistry, geology, physics, mathematics, medicine. It is, therefore, crucial for me to work with domain experts, and do so while maintaining my ability to delve into performance issues regardless of a particular application. To me, Artificial Intelligence is also a class of applications.
When did you know that you wanted to be a researcher and wanted to pursue this field?
I was a curious child and I would say that discovering new things is simply the condition that makes me feel most satisfied. I got my MSc and Ph.D. at the University of Pisa, Italy’s first Computer Science department, established in the late 1960s. The research group on Parallel Computing was strong. As a Ph.D. student, I have deeply appreciated their approach to distilling and abstracting computational paradigms independent of the specific domain and, therefore, somehow universal. That is mesmerizing.
What motivated you to pursue your recent research area of focus in supercomputing and the fight against COVID?
People remember the importance of research only in times of need, but sometimes it’s too late. When COVID arrived, all of us researchers felt the moral duty to be the front-runners in investing our energy and our time well beyond regular working hours. When CLAIRE (“Confederation of Laboratories for Artificial Intelligence Research in Europe”) proposed I lead a task force of volunteer scientists to help develop tools to fight against COVID, I immediately accepted. It was the task force on the HPC plus AI-based classification of interstitial pneumonia. I presented the results in my talk at GTC ’21; they are pretty interesting.
** Click here to watch the presentation from GTC ’21, “The Universal Cloud-HPC Pipeline for the AI-Assisted Explainable Diagnosis of of COVID-19 Pneumonia“.
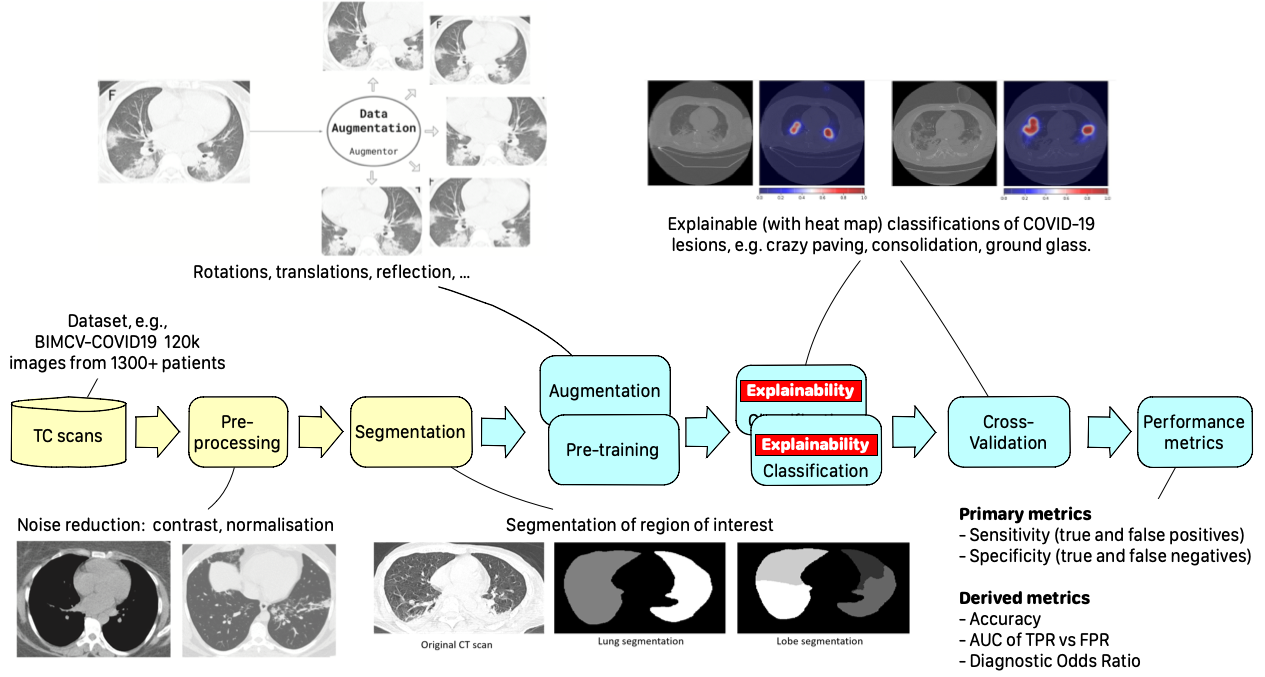
What problems or challenges does your research address?
I am specifically interested in what I like to call “the modernization of HPC applications,” which is the convergence of HPC and AI, but also all the methodologies needed to build portable HPC applications running on the compute continuum, from HPC to cloud to edge. The portability of applications and performances is a severe issue for traditional HPC programming models.
In the long term, writing scalable parallel programs that are efficient, portable, and correct must be no more onerous than writing sequential programs. To date, parallel programming has not embraced much more than low-level libraries, which often require the application’s architectural redesign. In the hierarchy of abstractions, they are only slightly above toggling absolute binary in the machine’s front panel. This approach cannot effectively scale to support the mainstream of software development where human productivity, total cost, and time to the solution are equally, if not more, important aspects. Modern AI toolkits and their cloud interfaces represent a tremendous modernization opportunity because they contaminate the small world of MPI and the batch jobs with new concepts: modular design, the composition of services, segregation of effects and data, multi-tenancy, rapid prototyping, massive GPU exploitation, interactive interfaces. After the integration with AI, HPC will not be what it used to be.
What challenges did you face during the research process, and how did you overcome them?
Technology is rapidly evolving, and keeping up with the new paradigms and innovative products that appear almost daily is the real challenge. Having a solid grounding in computer science and math is essential to being an HPC and AI researcher in this ever-changing world. Technology evolves every day, but revolutions are rare events. I happen to say to my students: it doesn’t matter how many programming languages you know; the problem is how much effort is needed to learn the next.
How is your work impacting the community?
I have always imagined the HPC realm as organized around three pillars: 1) infrastructures, 2) enabling technologies for computing, and 3) applications. We were strong on infrastructures and applications in Italy, but excellencies in technologies for computing were spread around different universities as leopard spots.
For this, we recently started a new national laboratory called “HPC Key technologies and Tools” (HPC-KTT). I am the founding Director. HPC-KTT co-affiliates hundreds of researchers from 35 Italian universities to reach the critical mass to impact international research with our methods and tools. In the first year of activity, we gathered EU research projects in competitive calls for a total cost 95M€ (ADMIRE, ACROSS, TEXTAROSSA, EUPEX, The European Pilot). We have just started, more information can be found in:
M. Aldinucci et al, “The Italian research on HPC key technologies across EuroHPC,” in ACM Computing Frontiers, Virtual Conference, Italy, 2021. doi:10.1145/3457388.3458508
What are some of your most proudest breakthroughs?
I routinely use both NVIDIA hardware and software. Most of the important research results I recently achieved in multi-disciplinary teams have been achieved thanks to NVIDIA technologies that are capable to accelerate machine learning tasks. Among recent results, I can mention a couple of important papers that appeared on “the Lancet” and “Medical image analysis“, but also HPC4AI (High-Performance Computing for Artificial Intelligence), a new data center I started at my university. HPC4AI runs an OpenStack cloud with almost 5000 cores, 100 GPUs (V100/T4), and six different storage systems. HPC4AI is the living laboratory where researchers and students of the University of Torino understand how to build performant data-centric applications across the entire HPC-cloud stack, from bare metal configuration to algorithms to services.
What’s next for your research?
We are working on two new pieces of software: a next-generation Workflow Management System called StreamFlow and CAPIO (Cross-Application Programmable I/O), a system for fast data transfer between parallel applications with support for parallel in-transit data filtering. We can sue them separately, but together, they express the most significant potential.
StreamFlow enables the design of workflows and pipelines portable across the cloud (on Kubernetes), HPC systems (via SLURM/PBS), or across them. It adopts an open standard interface (CWL) to describe the data dependencies among workflow steps but separate deployment instructions, making it possible to re-deploy the same containerized code onto different platforms. Using StreamFlow, we make the CLAIRE COVID universal pipeline” and QuantumESPRESSO almost everywhere, from a single NVIDIA DGX Station to the CINECA MARCONI100 supercomputer (11th in the TOP500 List — NVIDIA GPUs, and dual-rail Mellanox EDR InfiniBand), and across them. And they are quite different systems.
CAPIO, which is still under development, aims at efficiently (in parallel, in memory) moving data across different steps of the pipelines. The nice design feature of CAPIO is that it turns files into streams across applications without requiring code changes. It supports parallel and programmable in-transit data filtering. The essence of many AI pipelines is moving a lot of data around the system; we are embracing the file system interface to get compositionality and segregation. We do believe we will get performance as well.
Any advice for new researchers, especially to those who are inspired and motivated by your work?
Contact us, we are hiring.
