
Today NVIDIA introduced the new GM204 GPU, based on the Maxwell architecture. GM204 is the first GPU based on second-generation Maxwell, the full realization of the Maxwell architecture. The GeForce GTX 980 and 970 GPUs introduced today are the most advanced gaming and graphics GPUs ever made. But of course they also make fantastic CUDA development GPUs, with full support for CUDA 6.5 and all of the latest features of the CUDA platform, including Unified Memory and Dynamic Parallelism.
GM204’s 16 SMs make it over 3 times faster than the first-generation GM107 GPU that I introduced earlier this year on Parallel Forall, and additional architectural improvements help GM204 pack an even bigger punch.
SMM: The Maxwell Multiprocessor
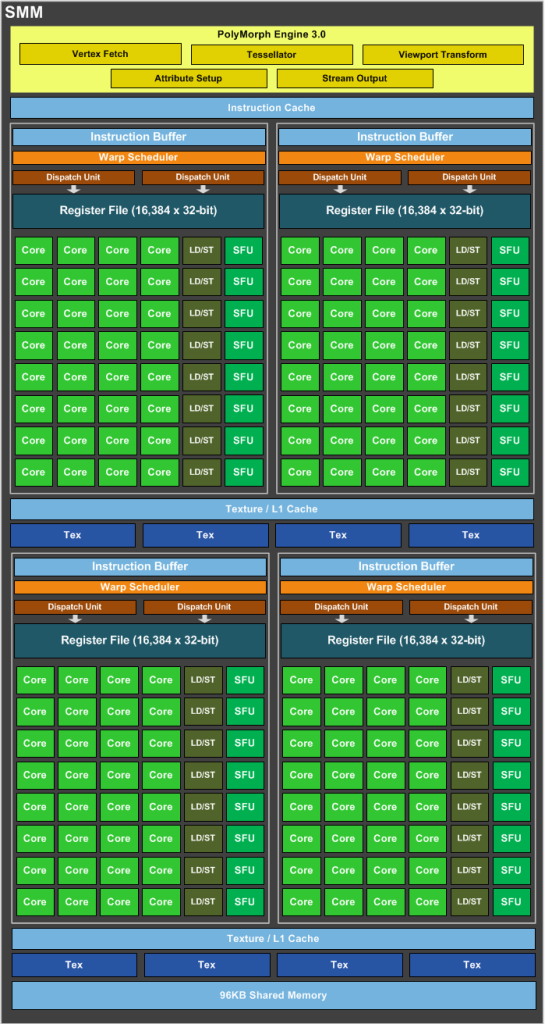
As I discussed in my earlier Maxwell post, the heart of Maxwell’s power-efficient performance is it’s Streaming Multiprocessor, known as SMM. Maxwell’s new datapath organization and improved instruction scheduler provide more than 40% higher delivered performance per CUDA core, and overall twice the efficiency of Kepler GK104. The new SMM, shown in Figure 1, includes all of the architectural benefits of its first-generation Maxwell predecessor, including improvements to control logic partitioning, workload balancing, clock-gating granularity, instruction scheduling, number of instructions issued per clock cycle, and more.
SMM uses a quadrant-based design with four 32-core processing blocks each with a dedicated warp scheduler capable of dispatching two instructions per clock. Each SMM provides eight texture units, one polymorph engine (geometry processing for graphics), and dedicated register file and shared memory.
The table shows a comparison of speeds and feeds between GeForce GTX 680 (Kepler GK104) and the new GeForce GTX 980 (Maxwell GM204).
| GPU | GeForce GTX 680 (Kepler GK104) | GeForce GTX 980 (Maxwell GM204) |
| CUDA Cores | 1536 | 2048 |
| Base Clock | 1006 MHz | 1126 MHz |
| GPU Boost Clock | 1058 MHz | 1216 MHz |
| GFLOPs | 3090 | 4612 |
| Compute Capability | 3.0 | 5.2 |
| SMs | 8 | 16 |
| Shared Memory / SM | 48KB | 96KB |
| Register File Size / SM | 256KB | 256KB |
| Active Blocks / SM | 16 | 32 |
| Texture Units | 128 | 128 |
| Texel fill-rate | 128.8 Gigatexels/s | 144.1 Gigatexels/s |
| Memory | 2048MB | 4096MB |
| Memory Clock | 6008 MHz | 7010 MHz |
| Memory Bandwidth | 192.3 GB/sec | 224.3 GB/sec |
| ROPs | 32 | 64 |
| L2 Cache Size | 512KB | 2048KB |
| TDP | 195 Watts | 165 Watts |
| Transistors | 3.54 billion | 5.2 billion |
| Die Size | 294 mm² | 398 mm² |
| Manufacturing Process | 28-nm | 28 nm |
The improvements to SM topology and scheduling should benefit performance as well as efficiency, and as I mentioned in my post about first-generation Maxwell, instruction latencies have been significantly reduced.
Because occupancy (which translates to available warp-level parallelism) is the same or better on SMM as on SMX, these reduced latencies improve utilization and throughput.
In addition, the throughput of many integer operations including multiply, logical operations and shift is improved on Maxwell, and there are now specialized integer instructions that can accelerate pointer arithmetic. These instructions are most efficient when data structures are a power of two in size, and here’s a tip provided by the Maxwell Tuning Guide:
Note: As was already the recommended best practice, signed arithmetic should be preferred over unsigned arithmetic wherever possible for best throughput on SMM. The C language standard places more restrictions on overflow behavior for unsigned math, limiting compiler optimization opportunities.
The end result of all of these improvements is that applications run more efficiently on Maxwell.
More Maxwell Improvements
There are a number of additional improvements in Maxwell that are likely to affect your CUDA application performance.
Larger, Dedicated Shared Memory
In my introduction to the Maxwell architecture earlier this year, I proclaimed that Maxwell improves on Kepler by separating shared memory from L1 cache, providing a dedicated 64KB shared memory in each SMM. Well, GM204 goes one better, upping that to 96KB of dedicated shared memory per SMM. There’s nothing you really need to change to take advantage of this feature: the maximum shared memory per thread block is still 48KB, just like on Kepler and Fermi GPUs. If you have kernels where occupancy is limited by shared memory capacity (or that use all 48KB in each thread block), those kernels could achieve up to 2x the occupancy that they achieved on Kepler.
Larger L2 Cache
The L2 cache on GM204 is four times larger than the L2 on GK104. As a result, bandwidth-bound applications may see a performance benefit, for example in the case where the working set size is between 512KB (GK104 cache size) and 2MB (GM204 cache size).
Shared Memory Atomics
Kepler introduced large improvements to the performance of atomic operations to device memory, but shared memory atomics used a lock/update/unlock pattern that could be expensive in the case of high contention for updates to particular locations in shared memory. Maxwell introduces native shared memory atomic operations for 32-bit integers and native shared memory 32-bit and 64-bit compare-and-swap (CAS), which can be used to implement other atomic functions with reduced overhead compared to the Fermi and Kepler methods. This should make it much more efficient to implement things like list and stack data structures shared by the threads of a block.
More Active Thread Blocks Per SM
The number of active warps per multiprocessor (64), the register file size (64K 32-bit registers), and the maximum registers used per thread (255) are the same on Maxwell as they were on (most) Kepler GPUs. But Maxwell increases the maximum active thread blocks per SM from 16 to 32. This should help improve occupancy of kernels running on small thread blocks (such as 64 threads per block).
Amazing New Graphics Features

On top of the incredible power efficiency and computational performance improvements that Maxwell Provides, GeForce GTX 980 includes some amazing new graphics capabilities. NVIDIA Voxel Global Illumination (VXGI) is the next big leap forward in lighting. Based on the concept pioneered by NVIDIA researcher Cyril Crassin in 2011, VXGI uses a 3D voxel data structure to capture coverage and lighting information at every point in the scene. This data structure can then be traced during the final rendering stage to accurately determine the effect of light bouncing around in the scene. (See How Our Maxwell GPUs Debunked the Apollo 11 Conspiracy Theory)
GM204 also introduces a new anti-aliasing approach known as Multi-Frame sampled Anti-aliasing (MFAA), which interleaves AA sample patterns both temporally and spatially to produce the best image quality while still offering a performance advantage compared to traditional Multi-Sample Anti-aliasing (MSAA). The final result can deliver image quality approaching that of 8x MSAA at roughly the cost of 4x MSAA.
In addition to VXGI and MFAA, GM204 introduces a number of other high-quality graphics features, including Dynamic Super Resolution, Conservative Rasterization, Viewport Multicast, and Sparse Texture.
Programming Maxwell: What You Need to Know
For the most part, programming Maxwell is business as usual—you won’t necessarily have to change your code to get the performance and efficiency benefits of this new architecture. But in addition to the SMM improvements I mentioned previously, there are a few things that you may be interested in trying in your code.
First off, to compile for a specific GPU architecture, you need to specify it on the nvcc command line. GM204 is a Compute Capability / SM Version 5.2 GPU, so you can specify the -arch=sm_52 flag to nvcc.
nvcc -arch=sm_52 example.cu -o example
Of course you can also compile for multiple architecture versions in a fat binary, and if you don’t compile explicitly for sm_52 you can still run the application on Maxwell, because the CUDA runtime will JIT compile for the architecture you run on. See my post about fat binaries and JIT compilation for full details, and also check out the Maxwell Compatibility Guide.
As an example, we compiled and ran the CUDA SDK n-body example (without any changes specifically for Maxwell) on GeForce GTX 980, and achieved 2,782 GFLOP/s for 65,536 bodies, which is the highest n-body performance we’ve seen on a GeForce GPU.
./nbody -benchmark -numbodies=65536
Get Started with Maxwell Today
All GPU Computing developers should be excited about the performance and efficiency that Maxwell GM204 brings to the table. So get started by learning more about developing for Maxwell, and installing the new CUDA 6.5 Toolkit and developer drivers with support for GM204, available now on CUDAZone.
 For more architecture details and guidance on optimizing your code for Maxwell, I encourage you to check out the Maxwell Tuning Guide and the Maxwell Compatibility Guide.
For more architecture details and guidance on optimizing your code for Maxwell, I encourage you to check out the Maxwell Tuning Guide and the Maxwell Compatibility Guide.
I’d like to thank M Clark for significant contributions to this post.