
Using the same orchestration on-premise and on the public cloud allows a high level of agility and ease of operations. You can use the same API across bare metal and public clouds. Kubernetes is an open-source, container-orchestration system for automating the deployment, scaling, and management of containerized applications. It was originally designed by Google and is now maintained by the Cloud Native Computing Foundation.
Kubernetes is quickly becoming the new standard for deploying and managing containers in the hybrid cloud. As a network engineer, why should you care about what developers are doing with Kubernetes? Isn’t it just another application consuming network resources? Kubernetes provides a flexible and reliable platform so that developers can focus on developing and scaling their applications.
In this post, I discuss the basic building blocks of Kubernetes and some networking challenges.
Kubernetes building blocks
Kubernetes is a tool that enables you to manage cloud infrastructure and the complexities of having to manage a virtual machine or network.
Nodes
A node is the smallest unit of computing element in Kubernetes. It is a representation of a single machine in a cluster. In most production systems, a node is usually either a physical server or a virtual machine hosted on-premises or on the cloud.
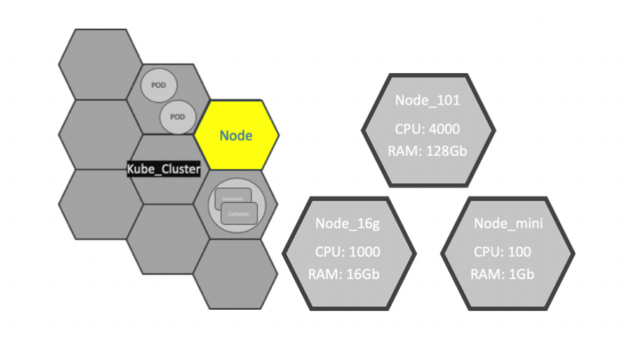
Clusters
A Kubernetes cluster is a set of node machines for running containerized applications. When you deploy applications on the cluster, the cluster intelligently handles distributing work to the individual nodes. If any nodes are added or removed, the cluster shifts workloads around as necessary. It should not matter to the application or developer which individual nodes are actually running the code.
Persistent volumes
Because applications running on the cluster are not guaranteed to run on a specific node, data cannot be saved to any arbitrary place in the file system. If an application tries to save data for later usage but is then relocated onto a new node, the data is no longer where the application expects it to be. For this reason, the traditional local storage associated with each node is treated as a temporary cache to hold applications, but any data saved locally cannot be expected to persist.
To store data permanently, Kubernetes use persistent volumes. While the CPU and RAM resources of all nodes are effectively pooled and managed by the cluster, persistent file storage is not. Instead, local or cloud stores can be attached to the cluster as a persistent volume.
Containers and microservices
Applications running on Kubernetes are packaged as Linux containers. Containers are a widely accepted standard, so there are already many prebuilt images that can be deployed on Kubernetes.
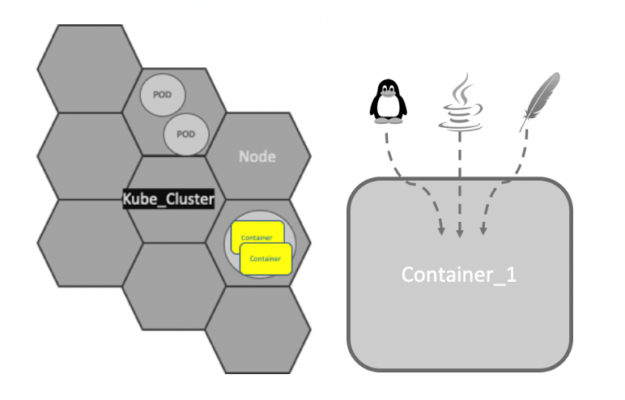
Containerization allows the creation of self-contained Linux execution environments. Any application and all its dependencies can be bundled up into a single file. Containers allow powerful continuous integration (CI) and continuous deployment (CD) pipelines to be formed, as each container can hold a specific part of an application. Containers are the underlying infrastructure for microservices.
Microservices are a software development technique, an architectural style that structures an application as a collection of loosely coupled services. The benefit of decomposing an application into different smaller services is that it improves modularity. This makes the application easier to understand, develop, test, and deploy.
Pods
Kubernetes doesn’t run containers directly. Instead, it wraps one or more containers into a higher-level structure called a Pod. Any containers in the same Pod share the same node and local network. Containers can easily communicate with other containers in the same Pod as though they were on the same machine, while maintaining a degree of isolation from others.
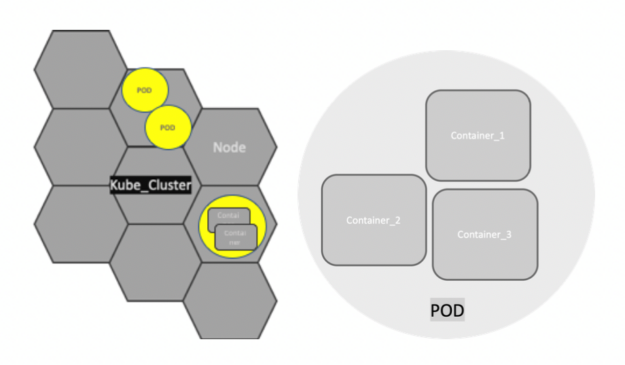
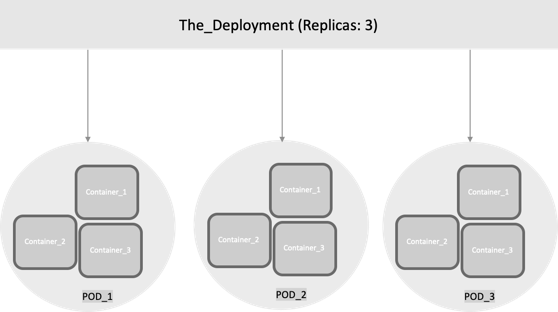
Pods are used as the unit of replication in Kubernetes. If your application becomes too heavy and a single Pod instance can’t carry the load, Kubernetes can be configured to deploy new replicas of your Pod to the cluster as necessary. Even when not under heavy load, it is standard to have multiple copies of a Pod running at any time in a production system to allow load balancing and failure resistance.
Deployments
Although Pods are the basic unit of computation in Kubernetes, they are not typically directly launched on a cluster. Instead, Pods are usually managed by one more layer of abstraction: deployment. A deployment’s purpose is to declare how many replicas of a Pod should be running at a time. When a deployment is added to the cluster, it automatically spins up the requested number of Pods, and then monitors them. If a Pod dies, the deployment automatically re-creates it.
With a deployment, you don’t have to deal with Pods manually. You can just declare the desired state of the system, and it is managed for you automatically.
Services and service meshes
A Kubernetes Service is an abstraction which defines a logical set of Pods and a policy by which to access them. Services enable loose coupling between dependent Pods.
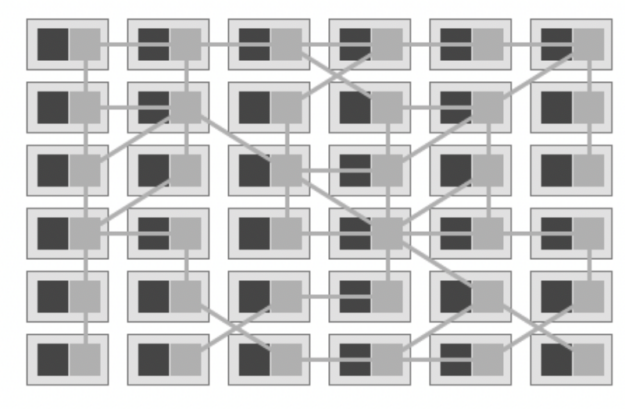
The term service mesh is used to describe the network of microservices that make up such applications and the interactions between them. As a service mesh grows in size and complexity, it can become harder to understand and manage. Its requirements can include discovery, load balancing, failure recovery, metrics, and monitoring. A service mesh also often has more complex operational requirements, like A/B testing, canary releases, rate limiting, access control, and end-to-end authentication.
One of the most popular plugins to control a service mesh is Istio, an open source, independent service, that provides the fundamentals you need to successfully run a distributed microservice architecture. Istio provides behavioral insights and operational control over the service mesh as a whole, offering a complete solution to satisfy the diverse requirements of microservice applications. With Istio, all instances of an application have their own sidecar container. This sidecar acts as a service proxy to all outgoing and incoming network traffic.
Networking
At its core, Kubernetes Networking has one important fundamental design philosophy: Every Pod has a unique IP address.
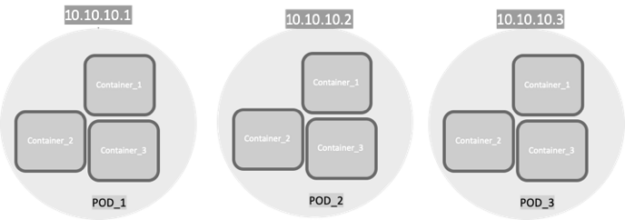
The Pod IP address is shared by all the containers inside, and it’s routable from all other Pods. A huge benefit of this IP-per-Pod model is there are no IP address or port collisions with the underlying host. There is no need to worry about what port the applications use.
With this in place, the only requirement Kubernetes has is that Pod IP addresses are routable and accessible from all the other Pods, regardless of their node.
To reduce complexity and make app porting seamless, in the Kubernetes networking model, a few rules are enforced as fundamental requirements:
- Containers can communicate with all other containers without Network Address Translation (NAT).
- Nodes can communicate with all containers without NAT and the reverse.
- The IP address that a container sees itself as is the same IP address that others see.
There are many network implementations for Kubernetes. Flannel and Calico are probably the most popular that are used as network plugins for the container network interface (CNI). CNI can be seen as the simplest possible interface between container runtimes and network implementations, with the goal of creating a generic plugin-based networking solution for containers.
Flannel can run using several encapsulation backends, with VXLAN being the recommended one. L2 connectivity is required between the Kubernetes nodes when using Flannel with VXLAN. Due to this requirement the size of the fabric might be limited, if a pure L2 network is deployed, the number of racks connected is limited to the number of ports on the spine switches.
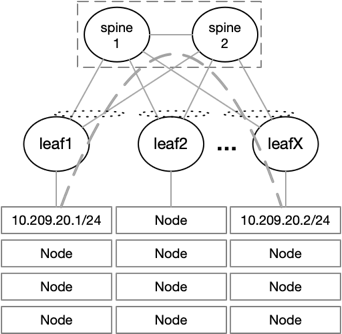
To overcome this issue, it is possible to deploy an L3 fabric with VXLAN and EVPN on the leaf level. L2 connectivity is provided to the nodes on top of a BGP-routed fabric that can scale easily. VXLAN packets coming from the nodes are encapsulated into VXLAN tunnels running between the leaf switches.
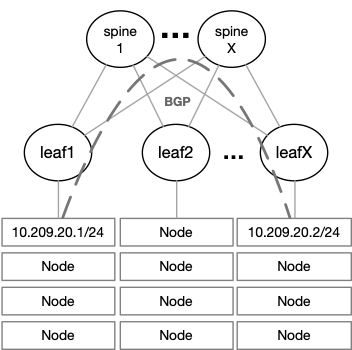
The NVIDIA Spectrum ASIC provides huge value when it comes to VXLAN throughput, latency, and scale. Most switches can support up to 128 remote VTEPs, meaning up to 128 racks in a single fabric. The NVIDIA Spectrum ASIC supports up to 750 remote VTEPs, allowing up to 750 racks in a single fabric.
NVIDIA Spectrum EVPN VXLAN differentiators
Watch the following video to learn why NVIDIA Spectrum Ethernet Switches are the best of breed platform to build a scalable, efficient, and high-performance EVPN VXLAN fabric.
Calico AS design options
In a Calico network, each endpoint is a route. Hardware networking platforms are constrained by the number of routes they can learn. This is usually in the range of 10,000s or 100,000s of routes. Route aggregation can help, but that is usually dependent on the capabilities of the scheduler used by the orchestration software, for example, OpenStack.
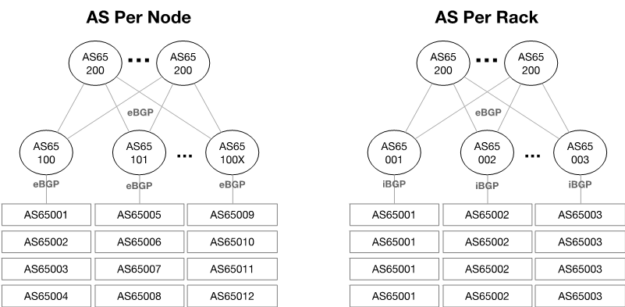
When choosing a Switch for your Kubernetes deployment, make sure it has a routing table size that won’t limit your Kubernetes compute scale. The NVIDIA Spectrum ASIC provides a fully flexible table size that enables up to 176,000 IP route entries with Spectrum1 and up to 512,000 with Spectrum2, enabling the largest Kubernetes clusters run by the biggest enterprises worldwide.
Routing stack persistency across a physical network and Kubernetes
When working with Cumulus Linux OS on the switch layer, we recommend using FRR as the routing stack on your nodes, leveraging BGP unnumbered. If you are looking for a pure, open-sourced solution, consider the NVIDIA Linux Switch, which supports both FRR and BIRD as the routing stack.
Network visibility challenges with Kubernetes
Containers are automatically spun up and destroyed as needed on any server in the cluster. Because the containers are located inside a host, they can be invisible to network engineers. You might never know where they are located or when they are created and destroyed.
Operating modern agile data centers is notoriously difficult with limited network visibility and changing traffic patterns.
By using Cumulus NetQ on top of NVIDIA Spectrum switches running the Cumulus OS, you can get wide visibility into Kubernetes deployments and operate in these fast-changing, dynamic environments.
