For scalable data center performance, NVIDIA GPUs have become a must-have.
NVIDIA GPU parallel processing capabilities, supported by thousands of computing cores, are essential to accelerating a wide variety of applications across different industries. The most compute-intensive applications across diverse industries use GPUs today:
- High-performance computing, such as aerospace, bioscience research, or weather forecasting
- Consumer applications that use AI to improve search, recommendations, language translation, or transportation, such as autonomous driving
- Healthcare, such as enhanced medical imaging
- Financial, such as fraud detection
- Entertainment, such as visual effects
Different applications across this spectrum can have different computational requirements. Training giant AI models where the GPUs batch process hundreds of data samples in parallel, keeps the GPUs fully utilized during the training process. However, many other application types may only require a fraction of the GPU compute, thereby resulting in underutilization of the massive computational power.
In such cases, provisioning the right-sized GPU acceleration for each workload is key to improving utilization and reducing the operational costs of deployment, whether on-premises or in the cloud.
To address the challenge of GPU utilization in Kubernetes (K8s) clusters, NVIDIA offers multiple GPU concurrency and sharing mechanisms to suit a broad range of use cases. The latest addition is the new GPU time-slicing APIs, now broadly available in Kubernetes with NVIDIA K8s Device Plugin 0.12.0 and the NVIDIA GPU Operator 1.11. Together, they enable multiple GPU-accelerated workloads to time-slice and run on a single NVIDIA GPU.
Before diving into this new feature, here’s some background on use cases where you should consider sharing GPUs and an overview of all the technologies available to do that.
When to share NVIDIA GPUs
Here are some example workloads that can benefit from sharing GPU resources for better utilization:
- Low-batch inference serving, which may only process one input sample on the GPU
- High-performance computing (HPC) applications, such as simulating photon propagation, that balance computation between the CPU (to read and process inputs) and GPU (to perform computation). Some HPC applications may not achieve high throughput on the GPU portion due to bottlenecks on the CPU core performance.
- Interactive development for ML model exploration using Jupyter notebooks
- Spark-based data analytics applications, where some tasks, or the smallest units of work, are run concurrently and benefit from better GPU utilization
- Visualization or offline rendering applications that may be bursty in nature
- Continuous integration/continuous delivery (CICD) pipelines that want to use any available GPUs for testing
In this post, we explore the various technologies available for sharing access to NVIDIA GPUs in a Kubernetes cluster, including how to use them and the tradeoffs to consider while choosing the right approach.
GPU concurrency mechanisms
The NVIDIA GPU hardware, in conjunction with the CUDA programming model, provides a number of different concurrency mechanisms for improving GPU utilization. The mechanisms range from programming model APIs, where the applications need code changes to take advantage of concurrency, to system software and hardware partitioning including virtualization, which are transparent to applications (Figure 1).
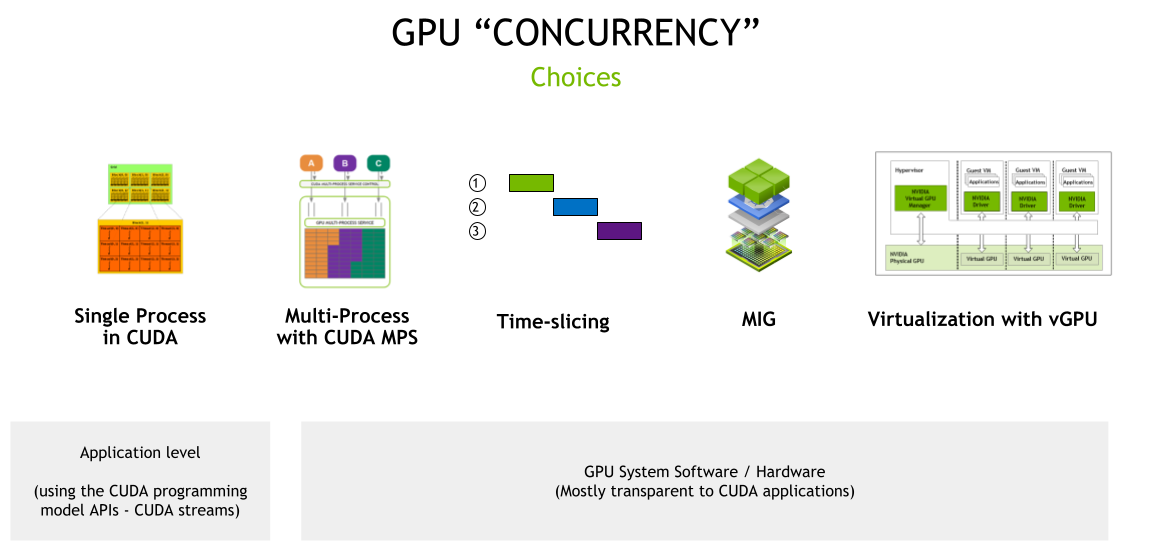
CUDA streams
The asynchronous model of CUDA means that you can perform a number of operations concurrently by a single CUDA context, analogous to a host process on the GPU side, using CUDA streams.
A stream is a software abstraction that represents a sequence of commands, which may be a combination of computation kernels, memory copies, and so on that all execute in order. Work launched in two different streams can execute simultaneously, allowing for coarse-grained parallelism. The application can manage parallelism using CUDA streams and stream priorities.
CUDA streams maximize GPU utilization for inference serving, for example, by using streams to run multiple models in parallel. You either scale the same model or serve different models. For more information, see Asynchronous Concurrent Execution.
The tradeoff with streams is that the APIs can only be used within a single application, thus offering limited hardware isolation, as all resources are shared, and error isolation between various streams.
Time-slicing
When dealing with multiple CUDA applications, each of which may not fully utilize the GPU’s resources, you can use a simple oversubscription strategy to leverage the GPU’s time-slicing scheduler. This is supported by compute preemption starting with the Pascal architecture. This technique, sometimes called temporal GPU sharing, does carry a cost for context-switching between the different CUDA applications, but some underutilized applications can still benefit from this strategy.
Since CUDA 11.1 (R455+ drivers), the time-slice duration for CUDA applications is configurable through the nvidia-smi utility:
$ nvidia-smi compute-policy --help
Compute Policy -- Control and list compute policies.
Usage: nvidia-smi compute-policy [options]
Options include:
[-i | --id]: GPU device ID's. Provide comma
separated values for more than one device
[-l | --list]: List all compute policies
[ | --set-timeslice]: Set timeslice config for a GPU:
0=DEFAULT, 1=SHORT, 2=MEDIUM, 3=LONG
[-h | --help]: Display help information
The tradeoffs with time-slicing are increased latency, jitter, and potential out-of-memory (OOM) conditions when many different applications are time-slicing on the GPU. This mechanism is what we focus on in the second part of this post.
CUDA Multi-Process Service
You can take the oversubscription strategy described earlier a step further with CUDA MPS. MPS enables CUDA kernels from different processes, typically MPI ranks, to be processed concurrently on the GPU when each process is too small to saturate the GPU’s compute resources. Unlike time-slicing, MPS enables the CUDA kernels from different processes to execute in parallel on the GPU.
Newer releases of CUDA (since CUDA 11.4+) have added more fine-grained resource provisioning in terms of being able to specify limits on the amount of memory allocatable (CUDA_MPS_PINNED_DEVICE_MEM_LIMIT) and the available compute to be used by MPS clients (CUDA_MPS_ACTIVE_THREAD_PERCENTAGE). For more information about the usage of these tuning knobs, see the Volta MPS Execution Resource Provisioning.
The tradeoffs with MPS are the limitations with error isolation, memory protection, and quality of service (QoS). The GPU hardware resources are still shared among all MPS clients. You can CUDA MPS with Kubernetes today but NVIDIA plans to improve support for MPS over the coming months.
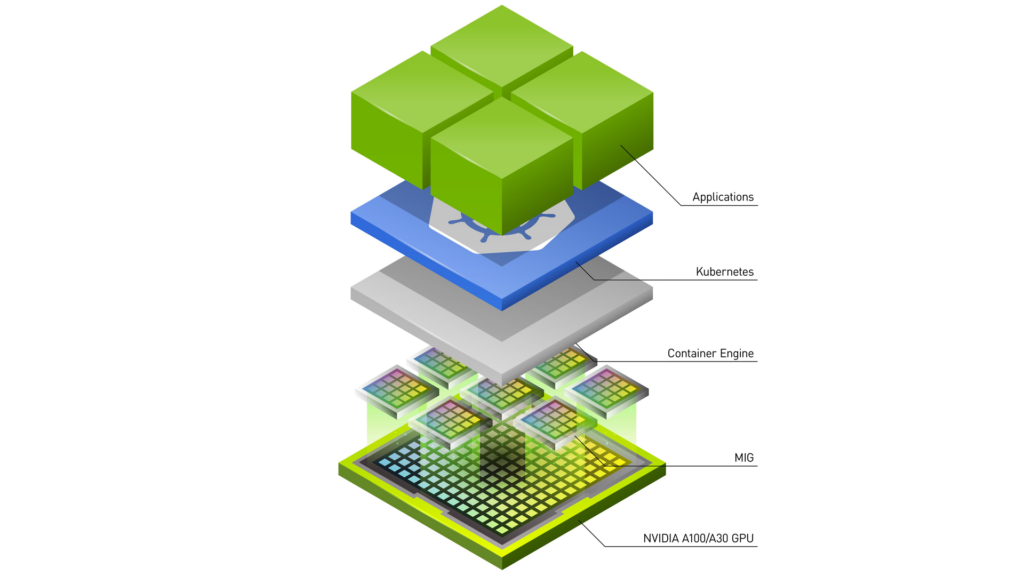
Multi-instance GPU (MIG)
The mechanisms discussed so far rely either on changes to the application using the CUDA programming model APIs, such as CUDA streams, or CUDA system software, such as time-slicing or MPS.
With MIG, GPUs based on the NVIDIA Ampere Architecture, such as NVIDIA A100, can be securely partitioned up to seven separate GPU Instances for CUDA applications, providing multiple applications with dedicated GPU resources. These include streaming multiprocessors (SMs) and GPU engines, such as copy engines or decoders, to provide a defined QoS with fault isolation for different clients such as processes, containers or virtual machines (VMs).
When the GPU is partitioned, you can use the prior mechanisms of CUDA streams, CUDA MPS, and time-slicing within a single MIG instance.
For more information, see the MIG user guide and MIG Support in Kubernetes.
Virtualization with vGPU
NVIDIA vGPU enables virtual machines with full input-output memory management unit (IOMMU) protection to have simultaneous, direct access to a single physical GPU. Apart from security, NVIDIA vGPU brings in other benefits such as VM management with live VM migration and the ability to run mixed VDI and compute workloads, as well as integration with a number of industry hypervisors.
On GPUs that support MIG, each GPU partition is exposed as a single-root I/O virtualization (SR-IOV) virtual function for a VM. All VMs can run in parallel as opposed to being time-sliced (on GPUs that do not support MIG).
Table 1 summarizes these technologies including when to consider these concurrency mechanisms.
| Streams | MPS | Time-Slicing | MIG | vGPU | |
| Partition Type | Single process | Logical | Temporal (Single process) | Physical | Temporal & Physical – VMs |
| Max Partitions | Unlimited | 48 | Unlimited | 7 | Variable |
| SM Performance Isolation | No | Yes (by percentage, not partitioning) | Yes | Yes | Yes |
| Memory Protection | No | Yes | Yes | Yes | Yes |
| Memory Bandwidth QoS | No | No | No | Yes | Yes |
| Error Isolation | No | No | Yes | Yes | Yes |
| Cross-Partition Interop | Always | IPC | Limited IPC | Limited IPC | No |
| Reconfigure | Dynamic | At process launch | N/A | When idle | N/A |
| GPU Management (telemetry) | N/A | Limited GPU metrics | N/A | Yes – GPU metrics, support for containers | Yes – live migration and other industry virtualization tools |
| Target use cases (and when to use each) | Optimize for concurrency within a single application | Run multiple applications in parallel but can deal with limited resiliency | Run multiple applications that are not latency-sensitive or can tolerate jitter | Run multiple applications in parallel but need resiliency and QoS | Support multi-tenancy on the GPU through virtualization and need VM management benefits |
With this background, the rest of the post focuses on oversubscribing GPUs using the new time-slicing APIs in Kubernetes.
Time-slicing support in Kubernetes
NVIDIA GPUs are advertised as schedulable resources in Kubernetes through the device plugin framework. However, this framework only allows for devices, including GPUs (as nvidia.com/gpu) to be advertised as integer resources and thus does not allow for oversubscription. In this section, we discuss a new method for oversubscribing GPUs in Kubernetes using time-slicing.
Before we discuss the new APIs, we introduce a new mechanism for configuring the NVIDIA Kubernetes device plugin using a configuration file.
New configuration file support
The Kubernetes device plugin offers a number of options for configuration, which are set either as command-line options or environment variables, such as setting MIG strategy, device enumeration, and so on. Similarly, gpu-feature-discovery (GFD) uses a similar option for generating labels to describe GPU nodes.
As configuration options become more complex, you use a configuration file to express these options to the Kubernetes device plugin and GFD, which is then deployed as a configmap object and applied to the plugin and the GFD pods during startup.
The configuration options are expressed in a YAML file. In the following example, you record the various options in a file called dp-example-config.yaml, created under /tmp.
$ cat << EOF > /tmp/dp-example-config.yaml
version: v1
flags:
migStrategy: "none"
failOnInitError: true
nvidiaDriverRoot: "/"
plugin:
passDeviceSpecs: false
deviceListStrategy: "envvar"
deviceIDStrategy: "uuid"
gfd:
oneshot: false
noTimestamp: false
outputFile: /etc/kubernetes/node-feature-discovery/features.d/gfd
sleepInterval: 60s
EOF
Then, start the Kubernetes device plugin by specifying the location of the config file and using the gfd.enabled=true option to start GFD as well:
$ helm install nvdp nvdp/nvidia-device-plugin \
--version=0.12.2 \
--namespace nvidia-device-plugin \
--create-namespace \
--set gfd.enabled=true \
--set-file config.map.config=/tmp/dp-example-config.yaml
Dynamic configuration changes
The configuration is applied to all GPUs on all nodes by default. The Kubernetes device plugin enables multiple configuration files to be specified. You can override the configuration on a node-by-node basis by overwriting a label on the node.
The Kubernetes device plugin uses a sidecar container that detects changes in desired node configurations and reloads the device plugin so that new configurations can take effect. In the following example, you create two configurations for the device plugin: a default that is applied to all nodes and another that you can apply to A100 GPU nodes on demand.
$ helm install nvdp nvdp/nvidia-device-plugin \
--version=0.12.2 \
--namespace nvidia-device-plugin \
--create-namespace \
--set gfd.enabled=true \
--set-file config.map.default=/tmp/dp-example-config-default.yaml \
--set-file config.map.a100-80gb-config=/tmp/dp-example-config-a100.yaml
The Kubernetes device plugin then enables dynamic changes to the configuration whenever the node label is overwritten, allowing for configuration on a per-node basis if so desired:
$ kubectl label node \
--overwrite \
--selector=nvidia.com/gpu.product=A100-SXM4-80GB \
nvidia.com/device-plugin.config=a100-80gb-config
Time-slicing APIs
To support time-slicing of GPUs, you extend the definition of the configuration file with the following fields:
version: v1
sharing:
timeSlicing:
renameByDefault: <bool>
failRequestsGreaterThanOne: <bool>
resources:
- name: <resource-name>
replicas: <num-replicas>
...
That is, for each named resource under sharing.timeSlicing.resources, a number of replicas can now be specified for that resource type.
Moreover, if renameByDefault=true, then each resource is advertised under the name <resource-name>.shared instead of simply <resource-name>.
The failRequestsGreaterThanOne flag is false by default for backward compatibility. It controls whether pods can request more than one GPU resource. A request of more than one GPU does not imply that the pod gets proportionally more time slices, as the GPU scheduler currently gives an equal share of time to all processes running on the GPU.
The failRequestsGreaterThanOne flag configures the behavior of the plugin to treat a request of one GPU as an access request rather than an exclusive resource request.
As the new oversubscribed resources are created, the Kubernetes device plugin assigns these resources to the requesting jobs. When two or more jobs land on the same GPU, the jobs automatically use the GPU’s time-slicing mechanism. The plugin does not offer any other additional isolation benefits.
Labels applied by GFD
For GFD, the labels that get applied depend on whether renameByDefault=true. Regardless of the setting for renameByDefault, the following label is always applied:
nvidia.com/<resource-name>.replicas = <num-replicas>
However, when renameByDefault=false, the following suffix is also added to the nvidia.com/<resource-name>.product label:
nvidia.com/gpu.product = <product name>-SHARED
Using these labels, you have a way of selecting a shared or non-shared GPU in the same way you would traditionally select one GPU model over another. That is, the SHARED annotation ensures that you can use a nodeSelector object to attract pods to nodes that have shared GPUs on them. Moreover, the pods can ensure that they land on a node that is dividing a GPU into their desired proportions using the new replicas label.
Oversubscribing example
Here’s a complete example of oversubscribing GPU resources using the time-slicing APIs. In this example, you walk through the additional configuration settings for the Kubernetes device plugin and GFD) to set up GPU oversubscription and launch a workload using the specified resources.
Consider the following configuration file:
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 5
...
If this configuration were applied to a node with eight GPUs on it, the plugin would now advertise 40 nvidia.com/gpu resources to Kubernetes instead of eight. If the renameByDefault: true option was set, then 40 nvidia.com/gpu.shared resources would be advertised instead of eight nvidia.com/gpu resources.
You enable time-slicing in the following example configuration. In this example, oversubscribe the GPUs by 2x:
$ cat << EOF > /tmp/dp-example-config.yaml
version: v1
flags:
migStrategy: "none"
failOnInitError: true
nvidiaDriverRoot: "/"
plugin:
passDeviceSpecs: false
deviceListStrategy: "envvar"
deviceIDStrategy: "uuid"
gfd:
oneshot: false
noTimestamp: false
outputFile: /etc/kubernetes/node-feature-discovery/features.d/gfd
sleepInterval: 60s
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 2
EOF
Set up the Helm chart repository:
$ helm repo add nvdp https://nvidia.github.io/k8s-device-plugin \ && helm repo update
Now, deploy the Kubernetes device plugin by specifying the location to the config file created earlier:
$ helm install nvdp nvdp/nvidia-device-plugin \
--version=0.12.2 \
--namespace nvidia-device-plugin \
--create-namespace \
--set gfd.enabled=true \
--set-file config.map.config=/tmp/dp-example-config.yaml
As the node only has a single physical GPU, you can now see that the device plugin advertises two GPUs as allocatable:
$ kubectl describe node ... Capacity: cpu: 4 ephemeral-storage: 32461564Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 16084408Ki nvidia.com/gpu: 2 pods: 110 Allocatable: cpu: 4 ephemeral-storage: 29916577333 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 15982008Ki nvidia.com/gpu: 2 pods: 110
Next, deploy two applications (in this case, an FP16 CUDA GEMM workload) with each requesting one GPU. Observe that the applications context switch on the GPU and thus only achieve approximately half the peak FP16 bandwidth on a T4.
$ cat << EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: dcgmproftester-1
spec:
restartPolicy: "Never"
containers:
- name: dcgmproftester11
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
args: ["--no-dcgm-validation", "-t 1004", "-d 30"]
resources:
limits:
nvidia.com/gpu: 1
securityContext:
capabilities:
add: ["SYS_ADMIN"]
---
apiVersion: v1
kind: Pod
metadata:
name: dcgmproftester-2
spec:
restartPolicy: "Never"
containers:
- name: dcgmproftester11
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
args: ["--no-dcgm-validation", "-t 1004", "-d 30"]
resources:
limits:
nvidia.com/gpu: 1
securityContext:
capabilities:
add: ["SYS_ADMIN"]
EOF
You can now see the two containers deployed and running on a single physical GPU, which would not have been possible in Kubernetes without the new time-slicing APIs:
$ kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE default dcgmproftester-1 1/1 Running 0 45s default dcgmproftester-2 1/1 Running 0 45s kube-system calico-kube-controllers-6fcb5c5bcf-cl5h5 1/1 Running 3 32d
You can use nvidia-smi on the host to see that the two containers are scheduled on the same physical GPU by the plugin and context switch on the GPU:
$ nvidia-smi -L GPU 0: Tesla T4 (UUID: GPU-491287c9-bc95-b926-a488-9503064e72a1) $ nvidia-smi ...<snip>... +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 466420 C /usr/bin/dcgmproftester11 315MiB | | 0 N/A N/A 466421 C /usr/bin/dcgmproftester11 315MiB | +-----------------------------------------------------------------------------+
Summary
Get started with leveraging the new GPU oversubscription support in Kubernetes today. Helm charts for the new release of the Kubernetes device plugin make it easy to start using the feature right away.
The short-term roadmap includes integration with the NVIDIA GPU Operator so that you can get access to the feature, whether that is with Red Hat’s OpenShift, VMware Tanzu, or provisioned environments such as NVIDIA Cloud Native Core on NVIDIA LaunchPad. NVIDIA is also working on improving support for CUDA MPS in the Kubernetes device plugin so that you can take advantage of other GPU concurrency mechanisms within Kubernetes.
If you have questions or comments, please leave them in the comments section. For technical questions about installation and usage, we recommend filing an issue on the NVIDIA/k8s-device-plugin GitHub repo. We appreciate your feedback!
