
Data loading is a critical aspect of deep learning workflows, whether you’re focused on training or inference. However, it often presents a paradox: the need for a highly convenient solution that is simultaneously customizable. These two goals are notoriously difficult to reconcile.
One of the traditional solutions to this problem is to scale out the processing and parallelize the user-written function. In this approach, the user creates a custom algorithm, while the system takes on the responsibility of scaling up its execution across multiple workers that simultaneously compute the task. This is where torch.DataLoader comes into play.
This post documents an experiment we conducted on optimizing torch.DataLoader by switching from processes to threads. This exploration was made possible due to Python’s ongoing effort to remove the GIL, enabling us to rethink parallelism in deep learning workflows and explore new performance optimizations.
What is torch.DataLoader and how does it work?
torch.DataLoader is a fundamental tool in PyTorch that facilitates the loading of data in deep learning applications. It plays a pivotal role in managing how data is fed into the model, ensuring that the process is both efficient and effective.
The important feature of torch.DataLoader is its ability to parallelize the loading process, which is crucial when dealing with large datasets.
This parallelization is typically achieved by creating multiple worker processes, each responsible for loading a portion of the data. These processes run in parallel, enabling data to be loaded and preprocessed concurrently with model training.
The parallelism is particularly important for maintaining a steady flow of data to the GPU, minimizing idle time, and maximizing resource utilization.
The dreaded GIL
torch.DataLoader uses processes to parallelize data-loading tasks, and this approach stems directly from a fundamental aspect of Python architecture known as the global interpreter lock (GIL).
The GIL is a mutex that prevents multiple native threads from executing Python bytecodes simultaneously in CPython, the most widely used Python implementation. This lock was introduced to simplify memory management and ensure thread safety by preventing race conditions when multiple threads try to access or modify Python objects at the same time.
While the GIL makes Python’s memory management straightforward and helps avoid complex concurrency bugs, it also imposes a significant limitation: Python threads are not truly parallel.
In CPU-bound tasks, where processing power is the bottleneck, threads are forced to take turns running, leading to suboptimal performance. This is why torch.DataLoader uses processes instead of threads. Each process operates in its own memory space, bypassing the GIL entirely and allowing true parallel execution on multi-core processors.
Naturally, the GIL’s influence is not all negative. It simplifies the development of Python programs by making thread safety less of a concern for developers, which is one of the reasons Python is so popular.
On the flip side, the GIL can be a bottleneck in CPU-bound and multi-threaded applications, as it hinders the full utilization of multi-core systems. This trade-off has sparked ongoing debates in the Python community about its merits and drawbacks.
Swapping processes for threads
With recent developments, the GIL is being removed in upcoming versions of Python. This opens up new possibilities for parallelism in Python applications, including deep learning.
One of our key ideas was to experiment with swapping the process-based parallelism in torch.DataLoader with thread-based parallelism (Figure 1).

Using threads instead of processes has several potential advantages. Threads are generally lighter weight than processes, enabling quicker context switches and lower memory overhead.
However, threading also comes with its own set of challenges, particularly in ensuring thread safety and avoiding issues like deadlocks.
We implemented a thread-based version of torch.DataLoader to explore these possibilities. The results were intriguing and demonstrated that threads could be a viable alternative to processes in certain scenarios.
Results of thread-based data loading
To assess the performance impact of replacing processes with threads in torch.DataLoader, we conducted a series of experiments across different data processing scenarios. The results highlighted both the potential and the limitations of thread-based parallelism.
Image decoding with nvImageCodec
One of the most compelling cases for using threads emerged in the image decoding scenario using nvImageCodec. In this scenario, the use of threads led to a substantial speedup compared to the traditional process-based approach.
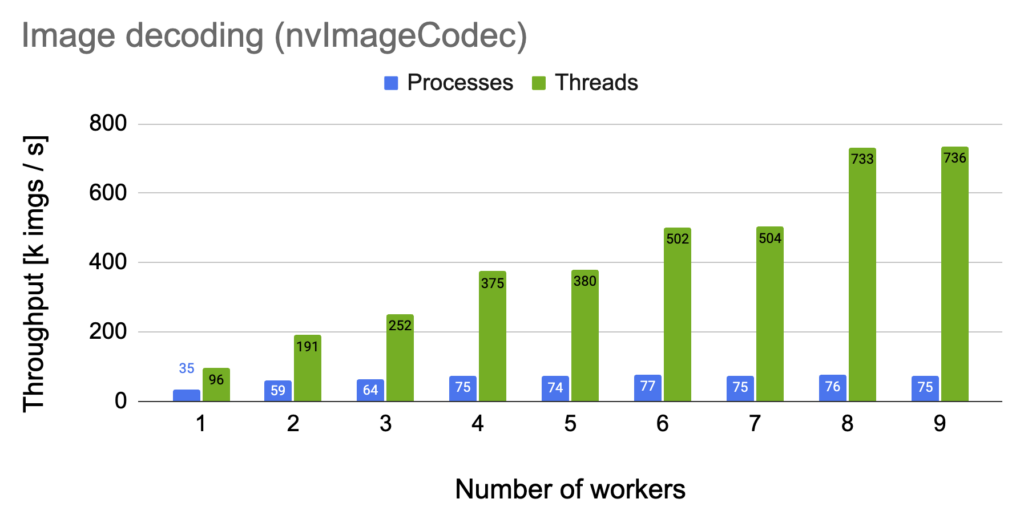
Benchmark details: EPYC 9654 | H100 | Batch size: 512 | Image size: 640 x 408 (JPEG)
The primary reason for this improvement is the reduction in CUDA context switching. Processes introduce a heavier overhead when switching contexts, which can cause significant delays, especially in GPU-accelerated workloads.
Threads, on the other hand, mitigate this overhead, enabling faster, more efficient execution.
Image decoding with Pillow
In contrast to nvImageCodec, our experiments with Pillow, a widely used Python imaging library, showed that the threaded approach was slightly slower than the process-based method.

Benchmark details: EPYC 9654 | Batch size: 512 | Image size: 640 x 408 (JPEG)
The key difference here lies in how the global state is managed. Pillow’s operations involve frequent access to global state data stored in dictionaries. When multiple threads access this shared data concurrently, the current implementation relies on atomics to manage these operations safely.
However, atomics can become a bottleneck under contention, leading to slower performance when compared to separate processes, where each worker has its own isolated state.
Due to this bottleneck, we initiated a discussion on discuss.python.org about revisiting the idea of freezing the data type, which could help mitigate these performance issues by enabling more efficient read access without the need for costly atomics.
Combined results: nvImageCodec vs. Pillow
To better show the performance differences, we combined the results from the nvImageCodec and Pillow scenarios into a single chart (Figure 4).
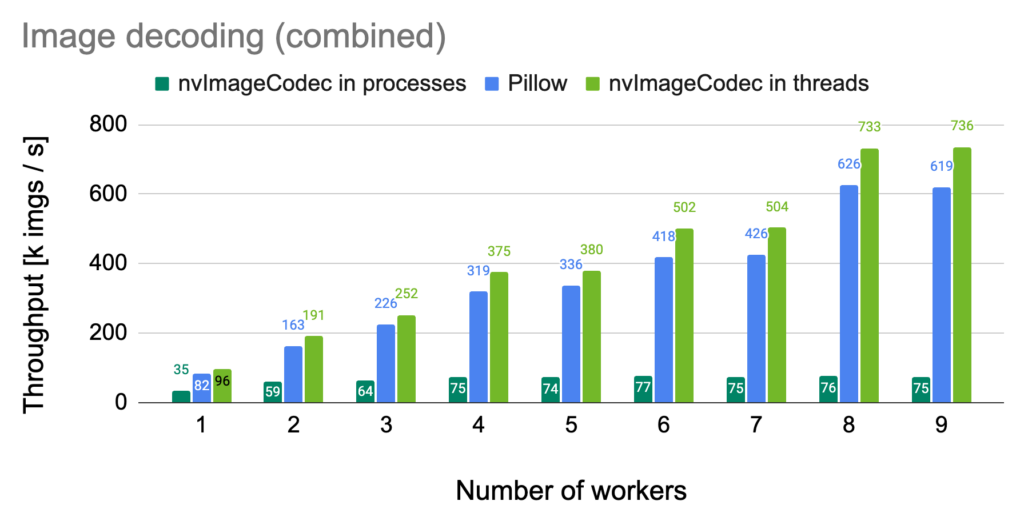
Benchmark details: EPYC 9654 | H100 | Batch size: 512 | Image size: 640 x 408 (JPEG)
This comparison clearly demonstrates the stark contrast between the two approaches:
nvImageCodec: Threads significantly outperform processes, showing that in GPU-heavy tasks with CUDA dependencies, the threaded approach is highly advantageous.- Pillow: Processes still hold a slight edge, emphasizing that tasks involving shared state might not benefit as much from threading.
These findings underscore that removing the GIL can immediately offer significant speedups in GPU-based scenarios. However, as Python takes its first steps into the free-threaded universe, we should put more effort into introducing new tools and concepts that fully leverage hardware capabilities and unlock the language’s full potential.
Pros and cons of thread-based torch.DataLoader
While our thread-based torch.DataLoader demonstrated clear advantages in certain scenarios, it’s important to consider the trade-offs.
The advantages are clear:
- Lower overhead: Threads are less resource-intensive than processes, leading to lower memory usage and faster context switches.
- Better performance in certain scenarios: As demonstrated in the
nvImageCodecexperiments, threads can reduce synchronization overhead, improving overall performance.
The disadvantages are as follows:
- Thread safety: Ensuring that the code is thread-safe can be challenging, especially in complex data pipelines. With threads, there’s also always a higher risk of deadlocks, which can halt the entire data-loading process.
- Extensive synchronization: Typically, threads must synchronize more often than processes. Implementing thread-based execution needs more scrutiny in the development process.
- Migrating existing implementations: Free-threaded Python ecosystem is in the early stages of development. It will take some time to adjust the vast amount of dependencies that the deep learning projects have.
Conclusion
The removal of the GIL presents new opportunities for optimizing deep-learning workflows in Python. Our exploration of a thread-based torch.DataLoader demonstrated that it is a beneficial approach whenever the worker implementation involves GPU processing.
For CPU operations, however, the performance tends to bottleneck due to inefficient parallel read access to data structures, which we hope will be addressed in the future.
As Python continues to evolve, the landscape of data loading in deep learning is set to change, and we’re excited to be at the forefront of these developments.
If you’re interested in learning more about our experiments with free-threaded Python, refer to our free-threaded Docker environment. Don’t hesitate to post your question in the issues section and try out the free-threaded Python in your use case!
