
Confidential and self-sovereign AI is a new approach to AI development, training, and inference where the user’s data is decentralized, private, and controlled by the users themselves. This post explores how the capabilities of Confidential Computing (CC) are expanded through decentralization using blockchain technology.
The problem being solved is most clearly shown through the use of personal AI agents. These services help users with many tasks, from writing emails to preparing taxes and looking at medical records. Needless to say, the data being processed is of a sensitive and personal nature.
In a centralized system, this data is processed in clouds by providers of AI services, which are generally not transparent. When a user’s data leaves their device, they lose control of their own data, which could be used for training, leaked, sold, or otherwise misused. There’s no way to track personal data at that point.
This problem of trust has impeded specific aspects of the evolution of the AI industry, especially for startups and AI developers who do not yet have the reputation or proof to back up their honest intent. A confidential and self-sovereign AI cloud provides a solution for customers who must secure their data and ensure data sovereignty.
Solving the self-sovereign AI cloud need
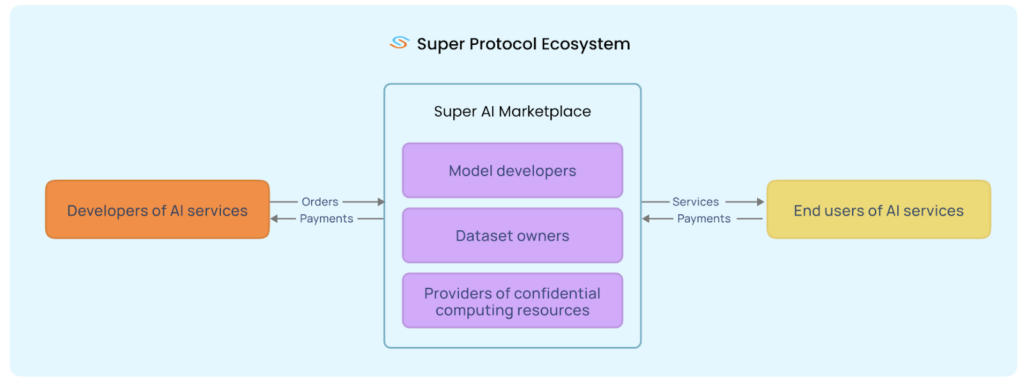
Super Protocol has built an eponymous AI cloud and marketplace based on the principles of confidentiality, decentralization, and self-sovereignty. In the Super Protocol cloud, confidential computing technology protects data during execution, while blockchain-based decentralized networks provide orchestration, transparency, and verifiability of all processes.
NVIDIA Confidential Computing uses CPUs and NVIDIA GPUs to protect the data in use, rendering it invisible and inaccessible by malicious actors and even the owners of the host machines.
NVIDIA Hopper architecture introduced Confidential Computing capabilities and the NVIDIA Blackwell architecture enhanced it with performance nearly identical to unencrypted modes for large language models (LLMs).
Use case: Fine-tuning and deploying an AI agent-as-a-service in Super Protocol
Here’s a practical use case: An AI developer wants to launch a commercial AI agent service by leasing a pretrained base model from the Super Protocol AI Marketplace and fine-tuning a new layer for a specific purpose that involves processing the end users’ private and sensitive data.
The pretrained model is proprietary and may not be downloaded, only leased on certain conditions set by its owner. Fine-tuning may include various methods such as knowledge distillation, low-rank adaption (LoRA), retrieval-augmented generation (RAG), and other approaches that don’t change the structure and weights of the base model.
Uploading and publishing
As a prerequisite, the owner of the base model uploaded their pretrained model to their account in a decentralized file storage (DFS) system and published an offer (an open listing for the model) on the Super Protocol AI Marketplace (steps 1-3 in Figure 2). This enables the model to be leased on preset conditions, which in this use case are payments for each hour of usage.
Now, you, as the AI developer, securely upload datasets to your account in a DFS system (steps 4-5 in Figure 2). These are private datasets to be used to fine-tune the base model.

Here are the components and services participating in this sequence of steps:
- DFS: Decentralized file storage is a peer-to-peer network such as Filecoin and Storj, used for storing and sharing data in a decentralized file system. Because DFS systems themselves are committed to the principles of self-sovereignty, users have full control of their own data and accounts. During the uploading process through the web interface or CLI, the data is archived and encrypted.
- AI Marketplace: The AI Marketplace is a ledger of offers published by the model developers, data owners, and the providers of CC resources. It is based on blockchain and smart contracts and is accessible through a web interface or CLI. It is used to upload and manage content as well as create and manage deployment orders and offers.
- Blockchain: A transparent, polygon-based decentralized ledger that stores information about providers, offers, and orders. This information includes descriptions, pricing conditions (free, per hour, fixed, revenue share), system requirements, and various usage rules and restrictions. This record is transparent, but immutable and can’t be altered.
- Smart contracts: Transparent and decentralized blockchain apps that orchestrate the deployments based on the usage rules and restrictions specified in the offers.
Fine-tuning
In the AI Marketplace, you select a pretrained base model that fits the purpose of the future AI service. You then create a deployment order to lease a pretrained base model from the AI Marketplace and fine-tune it with your own datasets (steps 6-7 in Figure 3).
Then, the smart contracts automatically select one or multiple machines from the Confidential Compute cloud that meet the requirements for the model fine-tuning. The execution controller, located in the confidential VM inside the TEE in each machine, verifies the order, downloads the content, and sends it to the trusted loader (steps 8-10 in Figure 3).
The trusted loader then deploys the workload for execution. An AI training engine takes the base pretrained model and fine-tunes it with the datasets as per the deployment order specifications (steps 11-12 in Figure 3 ).
This process may repeat multiple times until you are satisfied with the result. The new fine-tuned layer is uploaded back into your DFS system. I didn’t show these steps on the diagram to avoid needless visual complexity.
Both the owner of the pretrained model and the owners of the compute machines get paid on an hourly basis for their products and services (step 13 in Figure 3).

Here are the components and services participating in these steps:
- Confidential Compute cloud
- TEE
- Confidential virtual machine
- Execution controller
- Trusted loader
Confidential Compute cloud
A Confidential Compute cloud has distributed groups of clusters of powerful machines with CC enabled in the CPUs and NVIDIA H100 Tensor Core GPUs.
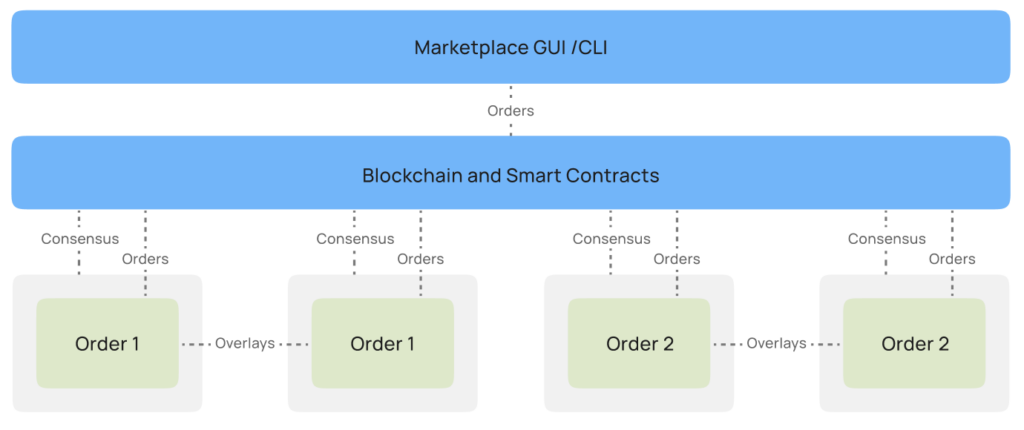
As Super Protocol is a decentralized cloud, it does not have a central data center. Instead, a network of overlays connects the containers participating in the deployment into a local network, ensuring the distribution of workloads similar to a centralized data center, while staying true to the principles of decentralization. Owners of models and datasets may restrict the distribution of their products to specific TEE devices and geolocations.
All machines are offered on the network by independent providers, similar to mining, but for useful workloads. The machines are coordinated by smart contracts, and the providers are rewarded by the network for offering their resources.
A consensus mechanism verifies that machines are present on the network and ready to take orders, that their declared system configuration is true, and that the TEE is valid, and also removes any fraudulent or malicious compute providers.
A single deployment may be created in multiple machines across different GPU cloud service providers (CSPs), resulting in higher utilization of underused CSP resources, improving stability, load balancing, and producing more competitive pricing deals.
Fault tolerance ensures that if one compute machine goes offline, another machine is automatically ordered as a replacement and that the deployment as a whole continues uninterrupted.
TEE
The trusted execution environment (TEE), a critical component of CC, is a protected area of the RAM where the actual workloads are executed in each machine. It is created specifically for each deployment order and is encrypted with a session key. The TEE protects data from any unauthorized third parties, including the owners of the host machines and the Super Protocol team.
The TEE of traditional confidential VMs has historically been limited to the CPU and its allocated RAM, while the NVIDIA CC solution extends the TEE to include NVIDIA Hopper GPUs.
NVIDIA GPUs configured in CC mode have hardware-based cryptographic engines, firewalls, and remote attestation flows activated to ensure the integrity of the TEE such that end users can ensure and validate that their confidential workloads are protected while in use on the GPU.
Hopper CC encrypts and signs all user data on the PCIe bus with AES-GCM256 and blocks infrastructure and out-of-band access with firewalls configured by signed and attestable firmware.
NVIDIA also provides a public remote attestation service such that end users or relying parties can receive up-to-date confidence that their drivers and firmware have not been revoked due to bugs or exploits.
Confidential virtual machine
A confidential virtual machine is where the execution controller, trusted loader, and the workloads run on each participating compute machine.
Execution controller
The execution controller (EC) downloads data from the DFS system as per the resource path written on blockchain. It creates the main deployment order in compliance with the smart contracts and blockchain conditions for the participating offers.
Trusted loader
The trusted loader establishes a secure CC layer, applicable to individual machines or a network of machines integrated into a computational cluster. The trusted loader publishes a TEE confirmation block (TCB), a remote attestation report, on blockchain, decrypts the workflow files, verifies their integrity by comparing hashes, and creates the workload for execution.
The goal here is to confirm the integrity of the order: confidentiality does not allow access inside the TEE and only inputs and outputs may be verified.

Production launch
Now it’s time for the production launch. Steps 14-19 (Figures 2-4) are similar to the previous phase.
The main difference begins in step 20 (Figure 5), where the AI engine deployed has a web interface and supports multi-user interactions and payment processing. It takes the base pretrained model and runs it with the new fine-tuned layer.
A set of confidential tunnels is also deployed to ensure secure and stable access by the end users (steps 22-23 in Figure 5). You provide end users with the URL to access the AI engine web interface. It may also be launched through Super Protocol as a part of another solution, but that is a different use case.
End users pay for the use of the AI agent service through convenient payment tools, with pricing determined by the developer.
For the production launch, you will want to order multiple machines running in parallel to ensure load balancing and fault tolerance. Tunnel servers should run on separate machines from tunnel clients.

- AI engine: An inference AI engine used for deployment. It has a user-friendly web interface that supports payment processing and executes the pretrained model with the new fine-tuned layer. These engines are open source and verified by Super Protocol to ensure that they don’t leak data.
- Confidential tunnels: Super Protocol developed a technology that enables you to launch the tunneling network protocol in a confidential mode inside the TEE, where the tunnel clients run as a web service containing the AI agent service. Tunnel servers provide external public IP addresses.
- Payment tools: An open-source service that also runs in the TEE with the AI engine and accepts payments from the end users on behalf of the developer.
Results for the AI agent-as-a-service use case
The fine-tuning and deploying an AI agent-as-a-service in Super Protocol scenario produces the following results:
- The developer adds new capabilities to the base model by training a new layer and launches a confidential AI agent as a commercial service.
- The base model owner gets paid for each hour of usage of their pretrained model.
- Providers of the CC resources are compensated for the use of their machines on an hourly basis.
- End users receive web access to a useful AI agent with convenient payment options and confidence that their sensitive data will not be leaked or used for model training.
- The Super Protocol cloud ensures fault tolerance and decentralization of the deployed AI services.
Security, transparency, and verifiability
Super Protocol achieves security and transparency through process integrity and the authenticity of components, which may be verified by independent security researchers:
- Blockchain and smart-contract transparency
- Content verification by the trusted loader
- TCB verification
- Open-source verification
- AI engine open-source verification
- E2E encryption
- TEE attestation
- Distributed secrets
Blockchain and smart-contract transparency
All blockchain records and smart contracts are immutable and transparent to anyone on the Internet. Offers, orders, and providers are visible, yet anonymous, and the contents of the deployment orders are confidential.
Content verification by the trusted loader
The integrity of all the input data (models, datasets, and solutions) of the deployment order is attested with the calculation of the hashes and signatures, which are then verified by the trusted loader during runtime.
The trusted loader provides a runtime report to any interested parties to independently verify that the hashes in the report match with hashes of provided content and that it has not been tampered with.
The GPU report can be directly used with the NVIDIA Remote Attestation Cloud services to independently validate the status of the GPU’s CC state.
TCB verification
The TCB is written on blockchain automatically by the TCB services. However, it is also possible for anyone to verify the TCB manually. This is done by verifying that the TEE device signature and the device itself are authentic and then comparing the hash of the VM image with the hash of the TCB.
Open-source verification of the trusted loader
Execution controllers, trusted loaders, tunnels, and other Super Protocol middleware are available on GitHub as open-source after the completion of the testnet phase.
The owners of the models and data attest the TCB containing the trusted loader key before the creation of the deployment order and then transferring secrets to access their data. This way, the owners are confident that the trusted loader application has not been tampered with and is identical with the official open-source version.
AI engine open-source verification
All AI engines in Super Protocol are available as open source. This enables security researchers to audit them for built-in vulnerabilities, such as leaking data.
E2E encryption
E2E encryption is used throughout this process. Data uploaded to the DFS system is encrypted and is only decrypted inside the trusted loader.
TEE attestation
For the complete attestation of the confidential environment, the trusted loader first receives a signed report from the NVIDIA GPU TEE. This report and the trusted loader public key are included in the general CPU TEE report that is received through remote attestation.
A TCB composed of two connected attestation reports is written to blockchain. Super Protocol uses NVIDIA and Intel libraries to verify the report and attestation, check the trusted loader hash, and then validate the confidential VM environment.
Distributed secrets
It is an encrypted secret vault on a DFS system that contains any private or sensitive user data generated by the solution deployed on Super Protocol.
The goal is to ensure that thesolution developers don’t have access to the stored data. The key to the vault is generated and shared between trusted loaders, while the vault itself is accessible by different instances of the deployment that have the same solution hash.
Conclusion
Historically, most AI models have been open-source and available for anyone to take and reuse freely. However, the emerging trend is that models and datasets are becoming increasingly proprietary.
CC and self-sovereign AI provides an opportunity for you to protect and commercialize your work, and further incentivizes you to provide AI services that are secure, transparent, and verifiable. This is especially important in the face of increasing government scrutiny over the AI industry.
For more information, see the following resources:
- Super Protocol
- Benefits of Confidential Computing for Web3 AI
- Real-Time AI Processing Workshop (NVIDIA provided the H100 TEE access for this workshop through NVIDIA LaunchPad.)
- NVIDIA Confidential Computing
- NVIDIA Launchpad for access to this and other labs
