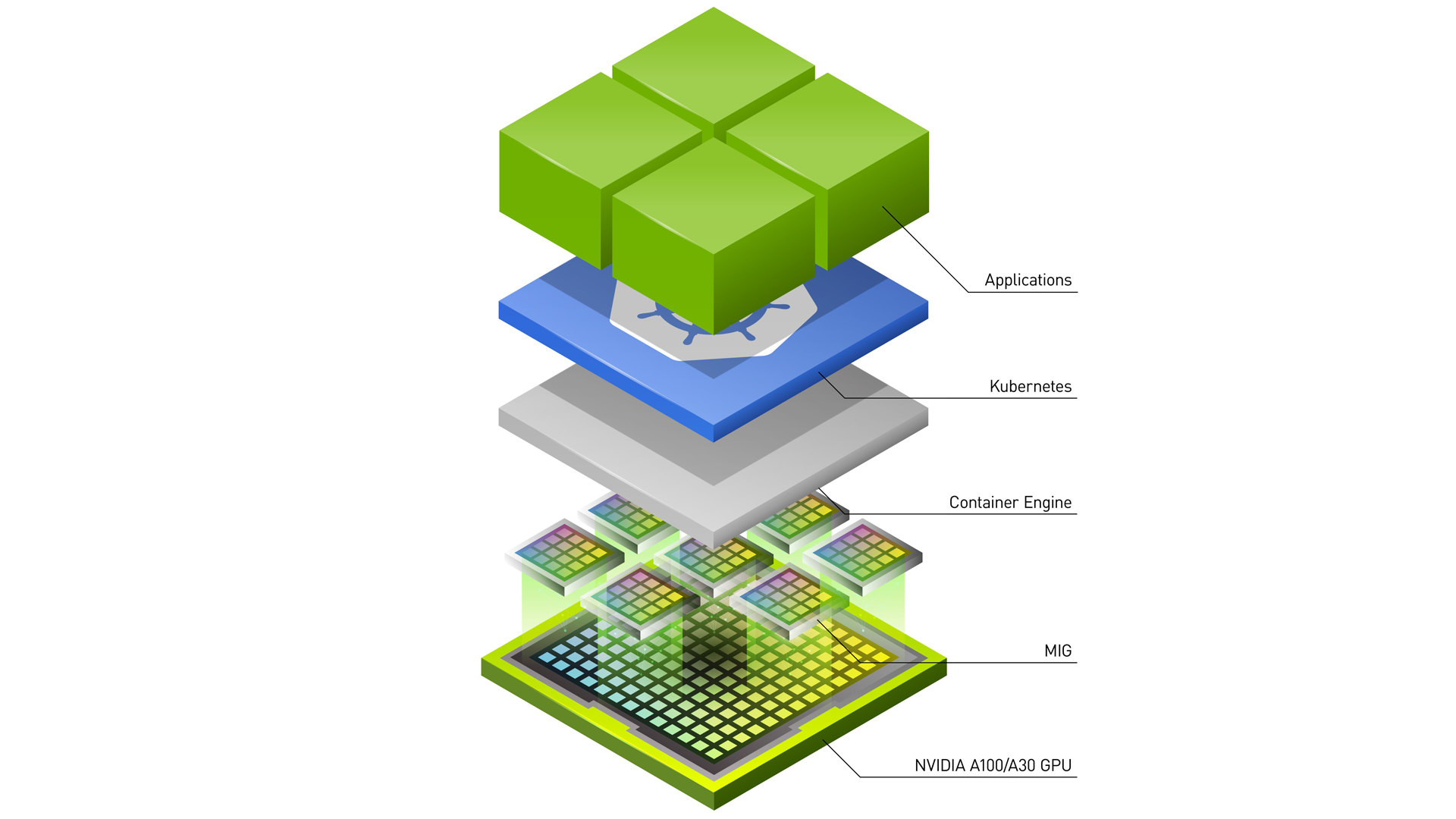
NVIDIA KAI Scheduler is now natively integrated with KubeRay, bringing the same scheduling engine that powers high‑demand and high-scale environments in NVIDIA Run:ai directly into your Ray clusters. This means you can now tap into gang scheduling, workload autoscaling, workload prioritization, hierarchical queues, and many more features in your Ray environment. Together, these capabilities make your infrastructure smarter by coordinating job starts, sharing GPUs efficiently, and prioritizing workloads. And all you have to do is configure it.
What this means for Ray users:
- Gang scheduling: no partial startups
Distributed Ray workloads need all their workers and actors to start together—or not at all. KAI ensures they launch as a coordinated gang, preventing wasteful partial allocations that stall training or inference pipelines. - Workload and cluster autoscaling
For workloads such as offline batch inference, Ray clusters can scale up as cluster resources become available or when queues permit over-quota usage. They can also scale down as demand decreases, providing elastic compute aligned with resource availability and workload needs without manual intervention. - Workload priorities: smooth coexistence of different types of workloads
High‑priority inference jobs can automatically preempt lower‑priority batch training if resources are limited, keeping your applications responsive without manual intervention. - Hierarchical queuing with priorities: dynamic resource sharing
Create queues for different project teams with clear priorities so that when capacity is available, the higher‑priority queue can borrow idle resources from other teams.
In this post, we’ll walk through a hands-on example of how KAI enables smarter resource allocation and responsiveness for Ray—particularly in clusters where training and online inference must coexist. You’ll see how to:
- Schedule distributed Ray workers as a gang, ensuring coordinated startup.
- Leverage priority-based scheduling, where inference jobs preempt lower-priority training jobs.
The result is a tightly integrated execution stack, built from tools designed to work together, from scheduling policies to model serving.
Technical setup
This example assumes the following environment:
- Kubernetes cluster with one NVIDIA A10G GPU.
- NVIDIA GPU Operator installed.
- NVIDIA KAI Scheduler deployed (see installation guide).
- KubeRay Operator nightly image or through Helm chart of KubeRay, configured to use KAI Scheduler (see installation guide).
--set batchScheduler.name=kai-schedulerStep 1: Set up KAI Scheduler queues
Before submitting Ray workloads, queues must be defined for the KAI Scheduler. KAI Scheduler supports hierarchical queuing, which enables teams and departments to be organized into multi-level structures with fine-grained control over resource distribution.
In this example, a simple two-level hierarchy will be created with a top-level parent queue called department-1 and a child queue called team-a. All workloads in this demo will be submitted through team-a, but in a real deployment, multiple departments and teams can be configured to reflect organizational boundaries.
apiVersion: scheduling.run.ai/v2
kind: Queue
metadata:
name: department-1
spec:
resources:
cpu:
quota: -1
limit: -1
overQuotaWeight: 1
gpu:
quota: -1
limit: -1
overQuotaWeight: 1
memory:
quota: -1
limit: -1
overQuotaWeight: 1
---
apiVersion: scheduling.run.ai/v2
kind: Queue
metadata:
name: team-a
spec:
parentQueue: department-1
resources:
cpu:
quota: -1
limit: -1
overQuotaWeight: 1
gpu:
quota: -1
limit: -1
overQuotaWeight: 1
memory:
quota: -1
limit: -1
overQuotaWeight: 1A quick breakdown of the key parameters:
- Quota: The deserved share of resources to which a queue is entitled.
- Limit: The upper bound on how many resources a queue can consume.
- Over Quota Weight: Determines how surplus resources are distributed among queues that have the same priority. Queues with higher weights receive a larger portion of the extra capacity.
In this demo, no specific quotas, limits, or priorities are enforced. We’re keeping it simple to focus on the mechanics of integration. However, these fields provide powerful tools for enforcing fairness and managing contention across organizational boundaries.
To create the queues:
kubectl apply -f kai-scheduler-queue.yamlWith the queue hierarchy now in place, workloads can be submitted and scheduled under team-a.
Step 2: Submit a training job with gang scheduling and workload prioritization
With the queues in place, it’s time to run a training workload using KAI’s gang scheduling.
In this example, we define a simple Ray cluster with one head node and two worker replicas.
KAI schedules all Kubernetes Pods (the two workers and the head) as a gang, meaning they launch together or not at all, and if preemption occurs, they’re stopped together too.
The only required configuration to enable KAI scheduling is the kai.scheduler/queue label, which assigns the job to a KAI queue—in this case, team-a.
An optional setting, priorityClassName: train, marks the job as a preemptible training workload. Here it is included to illustrate how KAI applies workload prioritization. For more information on workload priority, please refer to the official documentation.
Here’s the manifest used in this demo:
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: raycluster-sample
labels:
kai.scheduler/queue: team-a
priorityClassName: train
spec:
headGroupSpec:
template:
spec:
containers:
- name: ray-head
image: rayproject/ray:2.46.0
resources:
limits:
cpu: 4
memory: 15Gi
requests:
cpu: "1"
memory: "2Gi"
# ---- One Worker with a GPU ----
workerGroupSpecs:
- groupName: worker
replicas: 1
minReplicas: 1
maxReplicas: 2
template:
spec:
containers:
- name: ray-worker
image: rayproject/ray:2.46.0
resources:
limits:
cpu: 4
memory: 15Gi
requests:
cpu: "1"
memory: "1Gi"
nvidia.com/gpu: "1"To apply the workload:
kubectl apply -f kai-scheduler-example.yamlKAI then gang-schedules the Ray head and two workers.
Step 3: Deploy an inference service with higher priority using vLLM
Now that we’ve submitted a training workload, let’s walk through how KAI Scheduler handles inference workloads, which are non-preemptible and higher priority by default. This distinction enables inference workloads to preempt lower-priority training jobs when GPU resources are limited, ensuring fast model responses for user-facing services.
In this example, we’ll:
- Deploy Qwen2.5-7B-Instruct using vLLM with Ray Serve and RayService.
- Submit the job to the same queue (team-a) as the training job.
- Use the label kai.scheduler/queue to enable KAI scheduling.
- Set the priorityClassName to inference to mark this as a high-priority workload.
Note: The only required label for scheduling with KAI is kai.scheduler/queue.The priorityClassName: inference used here is optional and specific to this demo to demonstrate workload preemption. Also, be sure to create a Kubernetes secret named ‘hf-token’ containing your Hugging Face token before applying the YAML.
Here’s the manifest (make sure to add your own HF token at the Secret):
apiVersion: ray.io/v1
kind: RayService
metadata:
name: ray-kai-scheduler-serve-llm
labels:
kai.scheduler/queue: team-a
priorityClassName: inference
spec:
serveConfigV2: |
applications:
- name: llms
import_path: ray.serve.llm:build_openai_app
route_prefix: "/"
args:
llm_configs:
- model_loading_config:
model_id: qwen2.5-7b-instruct
model_source: Qwen/Qwen2.5-7B-Instruct
engine_kwargs:
dtype: bfloat16
max_model_len: 1024
device: auto
gpu_memory_utilization: 0.75
deployment_config:
autoscaling_config:
min_replicas: 1
max_replicas: 1
target_ongoing_requests: 64
max_ongoing_requests: 128
rayClusterConfig:
rayVersion: "2.46.0"
headGroupSpec:
rayStartParams:
num-cpus: "0"
num-gpus: "0"
template:
spec:
containers:
- name: ray-head
image: rayproject/ray-llm:2.46.0-py311-cu124
ports:
- containerPort: 8000
name: serve
protocol: TCP
- containerPort: 8080
name: metrics
protocol: TCP
- containerPort: 6379
name: gcs
protocol: TCP
- containerPort: 8265
name: dashboard
protocol: TCP
- containerPort: 10001
name: client
protocol: TCP
resources:
limits:
cpu: 4
memory: 16Gi
requests:
cpu: 1
memory: 4Gi
workerGroupSpecs:
- replicas: 1
minReplicas: 1
maxReplicas: 1
numOfHosts: 1
groupName: gpu-group
rayStartParams:
num-gpus: "1"
template:
spec:
containers:
- name: ray-worker
image: rayproject/ray-llm:2.46.0-py311-cu124
env:
- name: HUGGING_FACE_HUB_TOKEN
valueFrom:
secretKeyRef:
name: hf-token
key: hf_token
resources:
limits:
cpu: 4
memory: 15Gi
nvidia.com/gpu: "1"
requests:
cpu: 1
memory: 15Gi
nvidia.com/gpu: "1"
---
apiVersion: v1
kind: Secret
metadata:
name: hf-token
type: Opaque
stringData:
hf_token: $HF_TOKENApply the workload:
kubectl apply -f ray-service.kai-scheduler.llm-serve.yamlLoading the model and starting the vLLM engine will take some time here.
Observe preemption in action
Once applied, you’ll notice that KAI Scheduler preempts the training job to make room for the inference workload, since both compete for the same GPU, but the inference workload has higher priority.
Example output from kubectl get pods:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
ray-kai-scheduler-serve-llm-xxxx-gpu-group-worker-xxxx 1/1 Running 0 21m
ray-kai-scheduler-serve-llm-xxxx-head-xxxx 1/1 Running 0 21m
raycluster-sample-head-xxxx 0/1 Running 0 21m
raycluster-sample-worker-worker-xxxx 0/1 Running 0 21m
For the sake of simplicity in this demo, we used the Hugging Face model loading directly inside the container. This works for showcasing KAI Scheduler logic and preemption behavior. However, in real production environments, model loading time becomes a critical factor, especially when autoscaling inference replicas or recovering from eviction.
For that, we recommend using NVIDIA Run:ai Model Streamer, which is natively supported in vLLM and can be used out-of-the-box with Ray. For reference, please refer to the Ray documentation that includes an example showing how to configure the Model Streamer in your Ray workloads.
Interact with the deployed model
Before we port forward to access the Ray dashboard or the inference endpoint, let’s list the available services to ensure we target the correct one:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ray-kai-scheduler-serve-llm-head-svc ClusterIP None xxxxxx 10001/TCP,8265/TCP,6379/TCP,8080/TCP,8000/TCP 17m
ray-kai-scheduler-serve-llm-xxxxx-head-svc ClusterIP None xxxxxx 10001/TCP,8265/TCP,6379/TCP,8080/TCP,8000/TCP 24m
ray-kai-scheduler-serve-llm-serve-svc ClusterIP xx.xxx.xx.xxx xxxxxx 8000/TCP 17m
raycluster-sample-head-svc ClusterIP None xxxxxx 10001/TCP,8265/TCP,6379/TCP,8080/TCP,8000/TCP 32m
Now that we can see the service names, we’ll use:
ray-kai-scheduler-serve-llm-xxxxx-head-svcto forward the Ray dashboard.ray-kai-scheduler-serve-llm-serve-svcto forward the model’s endpoint.
Then, port forward the Ray dashboard:
kubectl port-forward svc/ray-kai-scheduler-serve-llm-xxxxx-head-svc 8265:8265Then open http://127.0.0.1:8265 to view the Ray dashboard and confirm the deployment is active.


Next, port forward the LLM serve endpoint:
kubectl port-forward svc/ray-kai-scheduler-serve-llm-serve-svc 8000:8000And finally, query the model using an OpenAI-compatible API call:
curl http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{
"model": "qwen2.5-7b-instruct",
"prompt": "San Francisco is a",
"max_tokens": 13,
"temperature": 0}'Sample response:
{
"id": "qwen2.5-7b-instruct-xxxxxx",
"object": "text_completion",
"created": 1753172931,
"model": "qwen2.5-7b-instruct",
"choices": [
{
"index": 0,
"text": " city of neighborhoods, each with its own distinct character and charm.",
"finish_reason": "length"
}
],
"usage": {
"prompt_tokens": 4,
"completion_tokens": 13,
"total_tokens": 17
}
}Wrapping up
In this blog, we explored how the KAI Scheduler advances scheduling capabilities to Ray workloads, including gang scheduling and hierarchical queuing. We demonstrated how training and inference workloads can be efficiently prioritized, with inference workloads able to preempt training jobs when resources are limited.
While this demo used a simple open-weight model and Hugging Face for convenience, NVIDIA Run:ai Model Streamer is a production-grade option that reduces model spin-up times by streaming model weights directly from S3 or other high-bandwidth storage to GPU memory. It’s also natively integrated with vLLM and works out of the box with Ray, as shown in this example from Ray’s docs. We’re excited to see what the community builds with this stack. Happy scheduling.
The KAI Scheduler team will be at KubeCon North America in Atlanta this November. Have questions about gang scheduling, workload auto-scaling, or AI workload optimization? Find us at our booth or sessions.
Get started with KAI Scheduler.