
The adoption of unmanned aerial systems (UAS) has been steadily growing over the last decade, and they have proven to be beneficial in a variety of fields, including agriculture, geographical mapping, aerial photography, and search and rescue. These systems, however, require a person in the loop for remote control, scene recognition, and data acquisition. This increases the cost of operation and significantly limits the scope of applications to those where remote control is possible.

Through our work we aim to bring the power of deep learning to unmanned systems via two main thrusts.
- Optimization of deep neural networks for specific tasks such as target detection, object recognition, mapping, localization and more.
- Implementation optimization of inference in deep neural networks with a focus on cost and performance. We leverage high performance, low-power, off-the-shelf platforms with embedded Graphics Processing Units (GPUs), like the NVIDIA Jetson TK1 Developer Kit and Jetson TX1.
In June 2016 our team from The Technion participated in an annual unmanned aerial vehicle competition by the Association for Unmanned Vehicle Systems International (AUVSI) and took fourth place. In this post we will describe our system that used deep learning on a Jetson TK1 Developer Kit.
The Rules of the competition state that “The principal focus of the SUAS Competition is the safe application and execution of Systems Engineering principles to develop and operate an autonomous Unmanned Aerial System (UAS) to successfully accomplish a specific set of tasks.”
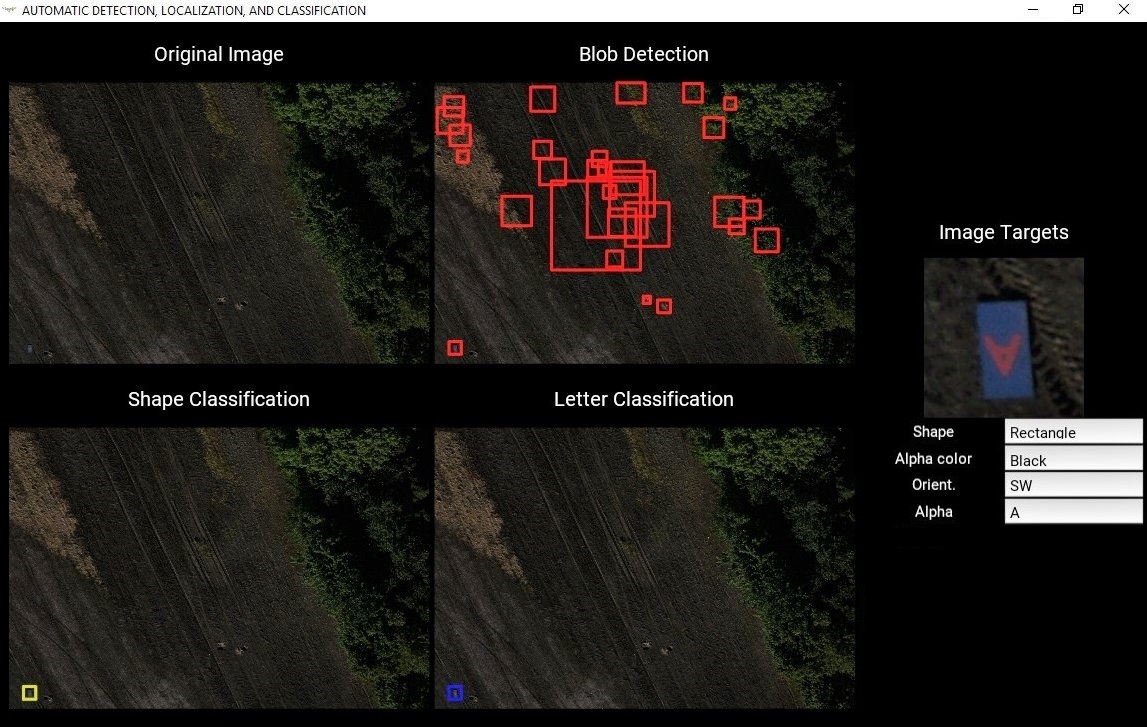
One of these tasks was the Automatic Detection, Localization and Classification (ADLC) of ground targets. These targets were constructed of plywood and characterized by their location (latitude and longitude), shape (circle, triangle, etc.), alphabetic letter (each target had a letter drawn in the center, as seen in Figure 1), letter orientation and color. The targets were not known beforehand and were scattered around a cluttered mission area. The UAV had to recognize the targets, their properties, and their locations while flying above the mission area.
In this post we’ll look at some of the constraints and challenges in building such a system and explain how we used deep learning on the Jetson TK1 Developer Kit to achieve human-level accuracy under variable conditions.
System Description
We developed our system in the Vision and Image Sciences Laboratory (VISL) for the ATHENA drone built by 20 students from the Technion Aerial System (TAS) team (see Figure 2). ATHENA is equipped with a Sony α-6000 camera, which produces 24M-pixel color images at two frames per second. Covering the complete search area takes approximately 10 minutes, and the total flight mission time is less than 30 minutes. This requires the system to process a total of 1,200 images at less than 0.7 seconds per image on average.

We selected the NVIDIA Jetson TK1 Developer Kit as our main image processing unit because its GPU provides high performance and efficiency (performance per watt) for convolutional neural networks in a lightweight and compact form factor. We were able to optimize the memory intensive application to fit within Jetson’s 2GB RAM and obtain a data rate needed to process the image.
We approached the challenge with the following design choices.
- Design the ADLC algorithm as a cascade of classifiers that enables discarding images that do not contain targets in an early stage of the pipeline. This saves computational resources and speeds the average processing time per frame.
- Balance the design of the deep learning networks between accuracy and speed.
- Parallelize the CPU share of the algorithm on multiple cores (Jetson boasts a quad-core ARM CPU).
- Use a separate airborne computer to control the camera and communicate with the ground station. This frees the Jetson to handle only the image processing tasks.
- Strip unnecessary modules from the Jetson operating system (Linux For Tegra: L4T) to free memory to hold larger neural networks.
Algorithm Description
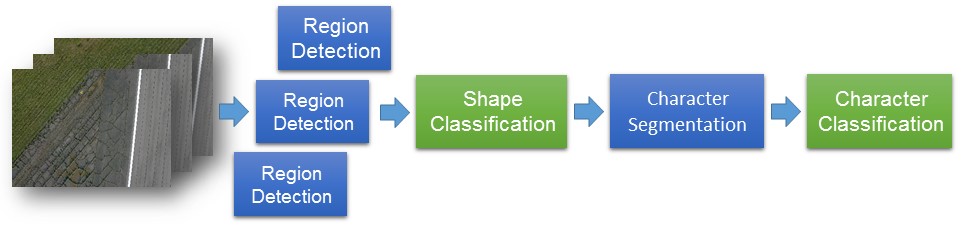
We implemented the ADLC algorithm as a four-stage pipeline, as Figure 3 shows.
- Detection of targets using a region detection algorithm
- Shape classification using a deep neural network, DNN1
- Character segmentation
- Character classification using another deep neural network, DNN2
The results of the ADLC algorithm are sent to the ground station and displayed in a custom GUI to the drone operators (Figure 4).
Region Detection
We chose to perform region detection using a standard blob detection algorithm running on the CPU. This frees the GPU to handle only the classification tasks. The blob detection algorithm detects salient regions in the picture and is performed on downscaled images to trade precision for speed. Candidates are further filtered using criteria like target size and convexity. We use OpenCV4Tegra for an optimized implementation of the algorithm, running up to four detection jobs in parallel.
It’s possible to use neural networks for region detection, and with the more powerful GPU in Jetson TX1, we expect that our next-generation system will be able to use end-to-end deep learning for the entire pipeline, even with the high resolution images taken by the camera.
Shape Classification
Target candidates are cropped from the full resolution images, downscaled to 32×32-pixel patches that are then processed by a convolutional neural network (CNN; see Figure 5). We carefully designed the network to be computationally lightweight while maintaining high accuracy. In addition to the shape classes defined by the competition organizers, a “no target” class was added to identify false positives. Patches identified as “no target” or classified with low confidence are discarded. At this point in the pipeline, most false positives are eliminated.
We use CAFFE with cuDNN for DNN inference.

Character Segmentation
In this step, patches classified as valid shapes (circle, square etc.) are preprocessed to produce binary masks of the character inside the target. Using a tight crop around the target, we assume the background in the patch is relatively uniform. We use k-means clustering to cluster the pixels in the patch into three classes: “background”, “shape” and “character”. We classify the clusters using the first two moments and convert the “character” class pixels into a binary mask of the target character.
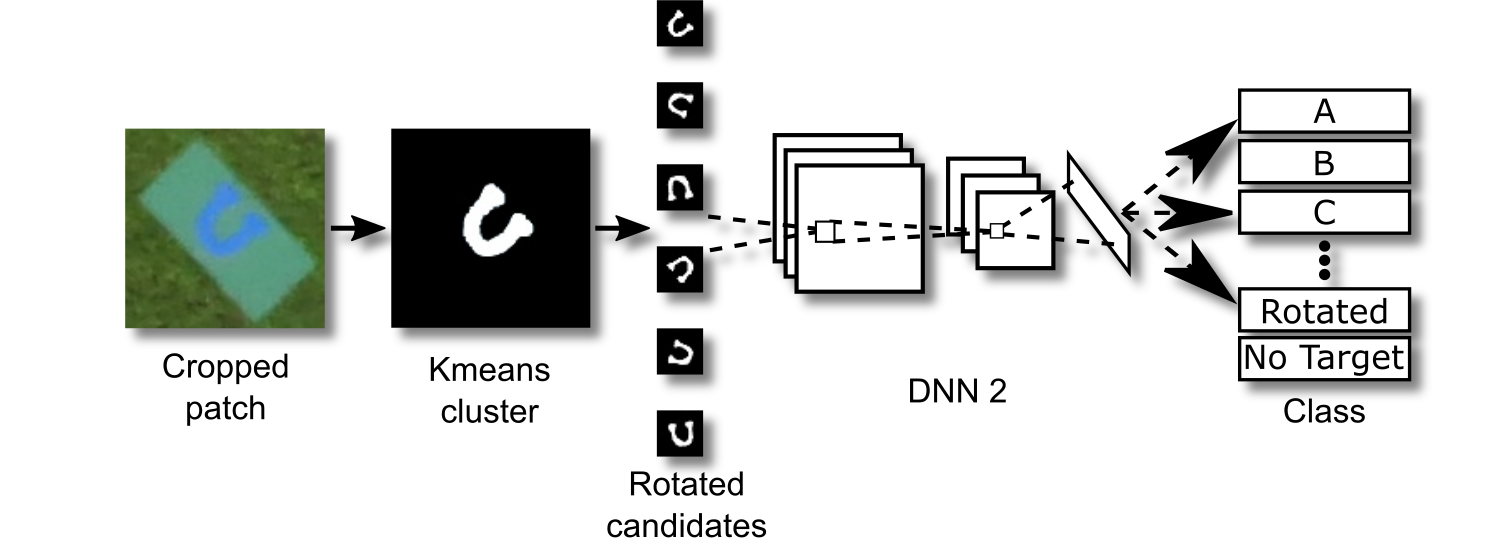
Character Classification and Orientation
The binary mask of the character is passed to the character classification stage. At first we considered using the Tesseract OCR algorithm, but we found it to be very sensitive to image quality, with low accuracy on single characters. Consequently, we trained a custom neural network to handle this stage.
In addition to the alphanumeric classes, we trained the network to classify “rotated character” and “no target” classes. The binary mask of the character from the previous stage is fed into the network at different rotations 15 degrees apart. The network takes the angle with the highest confidence as the correct answer. We deduce the orientation of the character from the rotation angle and camera orientation. Adding the “rotated character” improved the accuracy of the system. We speculate that it allows the network more flexibility in discriminating letters from non-letters.
Neural Network Training
There is no standard dataset of the competition targets, and building one large enough to enable training is labor-intensive and would require creating thousands of real targets to cover all possible combinations of shapes, letters and colors. Additionally, it would require hundreds of test flights to capture images of these targets, so we trained our deep neural networks on synthetic targets instead.
We created two synthetic datasets, one for training the shape network and the other for training the character network. We created the shape samples by first cropping random-sized patches from downsampled images taken during flight tests or from previous competitions, and then pasted random targets (random shapes, colors, sizes, orientations and characters) at random positions on the patch. Before pasting them target brightness was set to match the overall brightness of the patch, and Poisson noise was added to imitate camera capture noise. The targets were blended into the patch to avoid sharp edges.

We created the character samples by first generating a shape target at full resolution, and then extracting the target character using k-means clustering in a similar fashion to the segmentation algorithm previously described. This way the synthetic targets not only look real to the human eye, but they also imitate the way the system captures and processes the real targets. Figure 7 shows samples of synthetic targets. The only true target is the star at the top right with character ‘C’.
The processes described above enabled the creation of large datasets. Each dataset contained 500K labeled samples split evenly between the different classes. The characters dataset contained an additional “rotated characters” class. Also, to prevent the network from overfitting to synthetic targets, we augmented the training dataset with real targets that were captured during test flights or in previous competitions.
Training Process
We split the training dataset at 80% for training,10% for testing, and 10% for validation. We used DIGITS and an NVIDIA Titan X (Maxwell) for training and achieved 98% accuracy in only 28 minutes of training time.
We further validated the system on images taken during flight tests and images from the target detection mission of the previous year’s competition. The small number of targets that appeared in these images served more for qualitative than quantitative validation. This setup imitates a real competition scenario, and serves to compare the performance of different networks.
Results and Future Work
Using deep learning and the Jetson TK1 Developer Kit, we were able to create a system to solve a challenging real-world image processing task compact enough to fit into a small sized drone. When deployed, the system achieves a throughput of three images per second on average with a four second latency. Under full load Jetson consumed nine watts of power and was replaceable for under $200 in case of a crash during the drone development.

The system achieved the goals we set, garnering us 4th place in the competition, and we have already started working on next year’s system for SUAS 2017. We plan to make the following improvements.
- Replace the Jetson TK1 Developer Kit with the newer Jetson TX1 system. The larger memory and higher performance should enable us to use deeper networks while decreasing the processing latency.
- Replace the blob detection algorithm with a deep learning network for detection. This should enable end-to-end training.
- Use TensorRT for inference to simplify the code base and increase performance.
Get Started with Deep Learning for Unmanned Aerial Systems
On Wednesday, November 30, 2017, from 3:00-4:00pm ET NVIDIA will also be hosting a free webinar on the topic of “AI for UAVs” that will discuss how it’s possible to deploy artificial intelligence to small, mobile platforms with Jetson.
You can download our target synthesis code from Github.