
At GDC 2019, NVIDIA presented a talk called “Truly Next Gen: Adding Deep Learning to Games & Graphics”, which detailed the current state-of-the-art in deep learning for games. In the excerpt below, Anjul Patney, Senior Research Scientist at NVIDIA, provides information on how to capture data for neural network training. He also describes common deep learning bugs, and explains how to fix them.
The full hour-long video can be found here. It provides more information about advancements in DLSS (deep learning super sampling), and offers a detailed look at how this technology was integrated into EA’s Battlefield V.
Key Points:
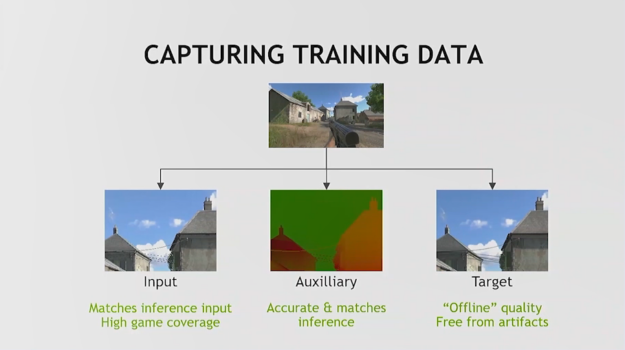
There are three specific sets of data that must be captured for neural network training
Input data: This is the input that you’re trying to optimize, or improve, or remove artifacts from. You want to capture this data set at the exact point at which you’re going to perform inference in the final run. Your capture pipeline and your inference pipeline should be aligned. You should have a high level of game coverage: include all biomes (day/night, indoor/outdoor, etc.).
Auxiliary buffers: This is the metadata (additional information) that you’re going to use to provide the network with more details about the task that you’re performing. It has to match the input.
Targets: References must be very high quality. Typically, you’ll need these in a state where one feature – the one you’re trying to train – is dialed up to its highest fidelity.
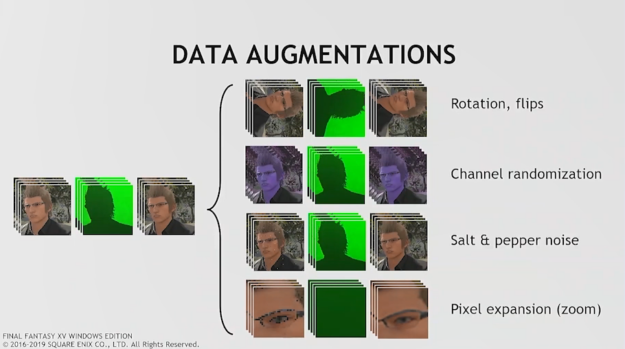
Data augmentations can be useful, but it is generally not a good substitute for actual data.
Augmentations for neural network training include flipping data around, randomizing colors, or adding noise. The goal is to expand the gamut of the input that you’re showing the network. This can be a useful exercise, but you have to be careful. In many cases this data set will be wider than the actual input the network will see. That can lead to the network learning more than it’s supposed to, potentially providing poorer results in the end.
Use a deterministic renderer
A common choke point: when you’re capturing data, you are writing a bunch of images from your renderer, but you can’t do that while you’re also playing the game. To make things even more frustrating, you’re frequently going to be changing resolutions, adjusting detail levels, etc., To make sure all of your exported data is aligned, you’re definitely going to want to use a deterministic renderer.
Make sure you have easy access to intermediate buffers
Depth, motion and normal buffers should exist non-ephemerally, and they should be easy to access and export out of your pipeline.
You need to be able to dial up individual effects “up to 11”
Many engines stop at a quality level that is real-time.You want an engine that goes beyond that. You want individual effects to be offline quality “flawless”, because any flaws in your target image will be reproduced by the network as it learns.
Watch the full talk, “Truly Next Gen: Adding Deep Learning to Games & Graphics”, here.
