
NVIDIA and Apache MXNet partner to simplify mixed precision training in MXNet.
Today, Apache MXNet announced native support for NVIDIA’s Automatic Mixed Precision (AMP) training feature on Volta and Turing GPUs.
Developers can now easily access deep learning training speedups available from NVIDIA Tensor Cores using reduced precision.
“Designed specifically for deep learning, the first-generation Tensor Cores in Volta deliver groundbreaking performance with mixed-precision matrix multiply in FP16 and FP32 — up to 12X higher peak teraflops (TFLOPS) for training and 6X higher peak TFLOPS for inference over the prior-generation NVIDIA Pascal,” the engineers stated.
In the blog, the engineers outline how to get started with mixed precision training using AMP in MXNet.
“While training in FP16 showed great success in image classification tasks, other more complicated neural networks typically stayed in FP32 due to difficulties in manually applying the mixed precision training guidelines. That is where Automatic Mixed Precision (AMP) comes into play: It automatically applies the guidelines of mixed precision training, setting the appropriate data type for each operator.”
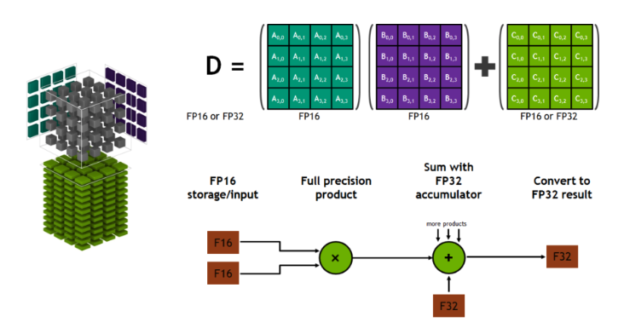
For the blog experiments, the team used an existing model and training script from the GluonCV model zoo. The GPU used in the walk-through is a single NVIDIA V100 GPU via AWS. In the benchmarks with SSD and Faster RCNN models, AMP demonstrated a 2X improvement in training throughput, and a 20x improvement with multiple GPUs.
Read the post in its entirety here.
