
The internet has changed how people consume media. Rather than just watching television and movies, the combination of ubiquitous mobile devices, massive computation, and available Internet bandwidth has led to an explosion in user-created content: users are re-creating the Internet, producing exabytes of content every day.
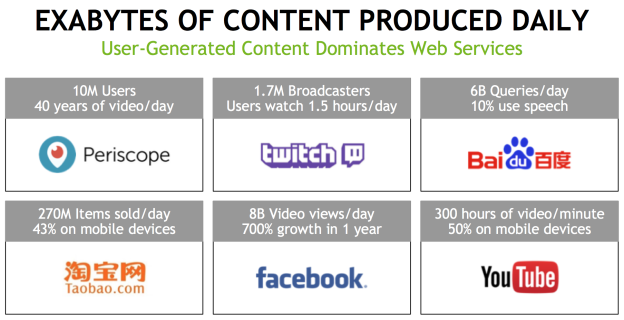
Periscope, a mobile application that lets users broadcast video to followers has 10M users who broadcast over 40 years of video per day. Twitch, a popular game broadcasting service, revealed last month that 1.7M users have live-streamed 7.5B minutes of content. China’s biggest search engine, Baidu, processes 6B queries per day, and 10% of those queries use speech. About 300 hours of video is uploaded to YouTube every minute. And just last week, Mark Zuckerberg shared that Facebook users view 8B videos every day—a number that has grown by a factor of 8 in about a year.
This massive scale of content requires massive amounts of processing. Due to the volume of media content involved, data center workloads are changing. Increasing resources are spent on video and image processing, resizing, transcoding, filtering, and enhancement. Likewise, large-scale machine learning and deep learning techniques apply trained models to what’s known as inference, which applies trained models to tasks such as image classification, object detection, machine translation, and speech recognition.

Accelerating hyperscale with GPUs
By 2019, annual global IP traffic will reach the two-zettabyte threshold, with video content predicted to account for 80% of consumer internet traffic worldwide. This rapid growth will put a strain on the massive “hyperscale” data centers that web services companies use to ingest, transcode, and process all that video.
Adding to the strain is the drive to enable new ways for users to experience, share, and interact with the video content. Web services companies are applying complex machine learning algorithms to train models that can classify, recognize, and analyze relationships in the data. These models are used to tag photos, recommend content or products, and deliver more relevant advertising.
To accelerate these hyperscale data center workloads, NVIDIA has extended its Accelerated Computing platform with new GPU and software offerings that enable web services companies to keep up with these computational demands at lower cost:
- NVIDIA M40 GPU: The most powerful accelerator designed for training deep neural networks.
- NVIDIA GPU: A low-power, small form-factor accelerator for video processing and machine learning inference.
- NVIDIA Hyperscale Suite:A rich layer of software optimized for machine learning and video processing.

M40 GPU Accelerator

The M40 GPU dramatically reduces the time to train deep neural networks, saving days or weeks on each training and allowing data scientists to train their neural networks against a massive amount of data to deliver higher overall accuracy. Key M40 GPU features include the following:
- Optimized for machine learning: Reduces training time by 8X compared with CPUs (1.2 days vs. 10 days for typical AlexNet training).
- Built for 24/7 reliability: Designed and tested for high reliability in data center environments.
- Scale-out performance: Support for NVIDIA GPUDirect enabling fast, multi-node neural network training.
The M40 provides 12GB of GDDR5 memory and 3,072 CUDA® cores delivering 7 TFLOPS of single-precision peak performance. It will be available from key server manufacturers, including Cirrascale, Dell, HP, QCT (Quanta Cloud Technology), Sugon, and Supermicro, as well as from NVIDIA reseller partners.
M4 GPU Accelerator
The M4 is a low-power GPU purpose-built for hyperscale environments and optimized for demanding, high-growth web services applications, including video transcoding, image processing, and machine learning inference. Providing 4GB of GDDR5 memory and 1,024 CUDA cores delivering 2.2 Tflops of single precision peak performance, key M4 GPU features include:

Key features include the following:
- Higher throughput: Transcodes, enhances, and analyzes up to 5X more simultaneous video streams compared with CPUs.
- Low power consumption: With a user-selectable power profile, the M4 consumes 50-75 watts of power, and delivers up to 10X better energy efficiency than a CPU for video processing and machine learning algorithms.
- Small form factor: Low-profile PCIe design fits into enclosures required for hyperscale data center systems.
Here are the key specifications for M40 and M4. All specifications and data are subject to change without notice.
| GPU Accelerator | M40 (GM200) | M4 (GM206) |
| CUDA Cores | 3072 | 1024 |
| FP32 TFLOP/s | 7 | 2.2 |
| GPU Base Clock | 948 MHz | 872 MHz |
| GPU Boost Clock | 1114 MHz | 1072 MHz |
| Compute Capability | 5.2 | 5.2 |
| SMs (version 5.2) | 24 | 8 |
| Shared Memory / SM | 96KB | 96KB |
| Register File Size / SM | 256KB | 256KB |
| Active Blocks / SM | 32 | 32 |
| GDDR5 Memory | 12,288MB | 4096MB |
| Memory Clock | 3000 MHz | 2750 MHz |
| Memory Bandwidth | 288 GB/sec | 88 GB/sec |
| L2 Cache Size | 3072KB | 2048KB |
| Form Factor | PCIe | PCIe Low Profile |
| TDP | 250 Watts | 50-75 Watts |
NVIDIA Hyperscale Suite
The new NVIDIA Hyperscale Suite includes tools for both developers and data center managers specifically designed for web services deployments:
- cuDNN: the industry’s most popular algorithm software for processing deep convolutional neural networks used for AI applications.
- GPU-accelerated FFmpeg multimedia software: Extends widely used FFmpeg software to accelerate video transcoding and video processing.
- NVIDIA GPU REST Engine: Enables the easy creation and deployment of high-throughput, low-latency accelerated web services spanning dynamic image resizing, search acceleration, image classification, and other tasks.
- NVIDIA Image Compute Engine: GPU-accelerated service with REST API that provides image resizing 5X faster compared to a CPU.

Hyperscale video transcoding and processing
What we watch on a screen and how we watch it have changed dramatically in the last decade. Video content has been freed from TV screens: we watch on a broad range of devices of many different sizes and resolutions. High-speed Internet to all devices has enabled a seemingly infinite number of “channels”.
Traditional broadcast and video-on-demand (VoD) providers have one-to-many models, where a few channels are transmitted to millions of viewers. The opposite scenario has become the norm in social media, where millions of channels are sometimes watched by many but in the majority of cases, by very few.
This poses a big problem for data centers because these millions of channels must be processed for efficient delivery to and display on myriad devices of different resolutions. Software video encoding using general-purpose CPUs is the default today, but this approach doesn’t scale. Video acceleration is needed in the data center.
NVIDIA GPUs with the NVENC hardware video encoder can supercharge existing data centers for video processing. The NVENC video encoder is an order of magnitude faster than software encoding so it can help data centers scale with the explosive growth of video channels.
Higher performance encoding helps solve the scaling problem, but it exposes bottlenecks in the rest of the processing pipeline. The most popular tool for building video processing pipelines is the flexible open-source technology called FFmpeg. FFmpeg is a multimedia framework with a library of plugins that can be applied to each part of the audio/video processing pipeline.
The NVIDIA NVENC plugin is now an important part of the FFmpeg framework, along with two new FFmpeg plugins, GPU Zero-copy and GPU Resize.
GPU Zero-copy enables other GPU-accelerated plugins to avoid expensive memory copies between system memory and GPU memory between video processing steps. This is especially beneficial for the GPU Resize plugin, which can convert single-source footage to many resolutions in parallel.
One-to-many (“1:n”) resize is commonly performed on internet-delivered video because a different resolution is needed for each device the video is to be played on. Web video servers often scale HD 1080p down to 720p, 576p, 480p, and smaller handheld sizes such as 360p, 240p, and 120p. Within each resolution, they create different bitrates so that the quality of streaming video can be adjusted based on the Internet connection.
The following example command uses FFmpeg with GPU Resize to generate five different scaled versions of the input video.
ffmpeg -y -i INPUT -filter_complex \ nvresize=5:s=hd1080\|hd720\|hd480\|wvga\|cif:readback=0[out0][out1][out2][out3][out4] \ -map [out0] -an -vcodec nvenc -b:v 6M -bufsize 6M -maxrate 6.8M -bf 2 out0nv.mp4 \ -map [out1] -an -vcodec nvenc -b:v 3M -bufsize 3M -maxrate 3.4M -bf 2 out1nv.mp4 \ -map [out2] -an -vcodec nvenc -b:v 2M -bufsize 2M -maxrate 2.1M -bf 2 out2nv.mp4 \ -map [out3] -an -vcodec nvenc -b:v 1M -bufsize 1M -maxrate 1.1M -bf 2 out3nv.mp4 \ -map [out4] -an -vcodec nvenc -b:v 0.5M -bufsize 0.5M -maxrate 0.5M -bf 2 out4nv.mp4
With so many channels available, searching for specific content is a new challenge for data centers. New techniques based on deep learning enable the content and even the action of the video to be inferred so that videos can be automatically tagged and indexed and then searched. However, training the neural network models and applying them to new videos is computationally expensive.
GPUs are the best platform for deep learning training. The combination of hardware video encoding and CUDA accelerated computing on the same accelerator makes the GPU the perfect platform to enable this exciting frontier in advanced video analytics.
For more information, see NVIDIA FFmpeg plug-ins.
NVIDIA GPU Rest Engine
REST services provide the data center equivalent of library calls. Multiple REST services are often combined within a full data center-level application. REST systems typically communicate over HTTP using the same HTTP commands (GET, PUT, and so on) used by web browsers to retrieve and update web pages. REST interfaces identify resources by URI. For example, a REST interface to an image resize service might use a URI like the following:
http://sass.com/resize/800x/pix/example.jpg?quality=50&crop=10x10x100x100”
This URI would cause the service to resize the image example.jpg to 800 pixels wide while maintaining the original aspect ratio after cropping the input image to a 100×100 region offset by 10 in x and y, and finally encoding the output image with 50% quality.
After the work is complete, the service sends the resulting image back to the web front-end for the final destination. For example, it could return the processed JPEG image in the case of a GET request, commit the image to disk, or send it to a downstream service in the case of a POST.
The goal of NVIDIA GPU REST Engine is to enable GPU-accelerated libraries and applications to easily fit into the data center as services accessible using REST interfaces. This enables high-throughput and low-latency computing capabilities for traditionally expensive offline bulk processing like image resizing and video transcoding.
GPU REST Engine provides the infrastructure to allow management of REST calls to GPU computing, with the goal of using multiple simultaneous incoming requests to efficiently use all the resources on the GPU. Functionally, GPU REST Engine has two main components: a web frontend like Apache or Go, and a threaded runtime system to manage GPU execution resources.
The runtime system takes command requests from the front-end, (usually GET or PUT requests), and hands them off to a pool of many worker threads. All threads share a CUDA context and each thread is responsible for one of many CUDA streams on a GPU. GPU REST Engine can manage multiple GPUs simultaneously.
By servicing REST requests asynchronously with many threads across multiple GPUs, GPU REST Engine achieves high resource utilization and efficiency. For example, as one worker thread is downloading data from host to device, a second thread can execute kernels, and a third can move data from device to host, all for separate requests. In practice, the GPU REST Engine resource scheduler can execute multiple simultaneous kernels and transfers. Instead of relying purely on bulk synchronous parallel execution, GPU REST Engine transforms the GPU into a task- and data-parallel execution device.
GRE also helps with managing the CPU-heavy components of algorithms. Specifically in the case of JPEG transcoding, the JPEG decode step is generally serial in nature and executes on the CPU. The heavily threaded work pool concept in GPU REST Engine enables high-priority CPU tasks, like JPEG decode, to execute while the GPU execution and driver management parts of the code run at a lower priority.
For more information, see NVIDIA GPU REST Engine.
NVIDIA Image Compute Engine
The NVIDIA Image Compute Engine (ICE) is a production instance of GPU REST Engine technology. ICE combines the GPU REST Engine, the NPP library (NVIDIA Performance Primitives), and custom CUDA C++ kernels to provide high throughput, low-latency image processing for the web. It is a great example of the power of REST and GPUs for hyperscale, providing on-the-fly image JPEG resizing and filtering to eliminate static, preprocessed image breakpoint sizes.
ICE can resize images fast enough on Amazon EC2 g2.2xlarge instances to replace 3-5 CPU nodes while reducing latency to make on-the-fly resizing possible.
This capability means that web designers can redesign or change site user interfaces and layout without needing to worry about having to reprocess their entire image library. Moreover, because resize can occur on the fly, the optimal image size can be sent to users. With ICE, sites no longer have to choose between saving bandwidth by sending low-resolution images and upsampling on the client, or saving computation by sending oversized images and downsampling on the client.
ICE splits processing into multiple phases; the Huffman decode of the incoming JPEG is executed on the CPU, while the inverse DCT, resize, filtering, and full encode are executed on the GPU. This maximizes utilization of the node, matching the phases to the best available processor for each task.
The popular photo-sharing service SmugMug has already deployed NVIDIA ICE to serve optimally sized images to their users on the fly. “Our photographers communicate their vision through the photos they share on our platform, and experiencing those images quickly at the highest quality regardless of screen size is critical to their success,” says Don MacAskill, CEO and Chief Geek of SmugMug.

For more information on the NVIDIA Image Compute Engine, visit https://developer.nvidia.com/ice.
Tools for Hyperscale Deployment
Developing applications that can scale to large data centers is not easy. For one, building applications that are cluster-aware and can distribute work across the network of cluster nodes to execute in parallel. And those cluster nodes are a shared resource, meaning that data centers need to be able to efficiently and safely run scalable applications while maintaining security, fault tolerance, and high cluster utilization. Cluster managers aim to simplify these tasks.
The second challenge is deployment. Applications may need to run on a variety of machine configurations (single machine, local cluster, cloud infrastructure) with different underlying hardware architectures or operating systems. Most apps depend on a variety of components, libraries, and resources. Software containers help solve deployment problems by encapsulating an application and all its dependencies, without being tied to any architecture or infrastructure.
Bringing GPUs to Apache Mesos
Apache Mesos is a distributed resource manager for scheduling applications across the data center on a shared cluster (either running on-premises or on cloud infrastructure). Mesos provides efficient resource isolation and sharing across distributed applications or frameworks, abstracting CPU, memory, storage, and other compute resources away from machines, enabling building and running fault-tolerant, scalable distributed applications and services.

Mesos is being extended to support GPUs as a native system resource. This new capability is thanks to an engineering partnership between Mesosphere and NVIDIA that enables Mesos to treat GPU resources in the same way that it treats CPU and system memory resources. This enables accelerated applications to share fine-grained GPU resources on a common data center cluster to deliver higher application throughput and resource efficiency. It also simplifies data center operations by removing the overhead of managing multiple independent clusters.
Long-running applications and system services can be scheduled and managed using the GPU-enabled Marathon framework. Similarly, batch jobs can be scheduled using Chronos, all sharing the common cluster managed by Mesos. The applications can be deployed as native host OS tasks as well as Docker-ized containers or microservices on the cluster to ensure portability and isolation. A diverse set of accelerated applications such as deep learning, image, video, and audio processing and analytics can now benefit from Mesos resource management for hyperscale data center deployment.
Easily containerize GPU-accelerated applications
Containers wrap applications into an isolated virtual environment to simplify data center deployment. By including all application dependencies (binaries and libraries), application containers run seamlessly in any data center environment.

Docker, the leading container platform, can now be used to containerize GPU-accelerated applications. To make it easier to deploy GPU-accelerated applications in software containers, NVIDIA has released open-source utilities to build and run Docker container images for GPU-accelerated applications. This means you can easily containerize and isolate accelerated applications without any modifications and deploy them on any supported GPU-enabled infrastructure.
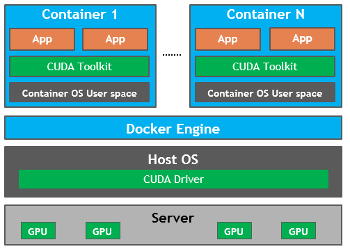
The NVIDIA Docker Recipe, instructions, and examples are now available in the /NVIDIA/nvidia-docker GitHub repo. Building a Docker image with support for CUDA is easy with a single command:
# With latest versions $ docker build -t cuda ubuntu/cuda/latest
There is also a new nvidia-docker script that is a drop-in replacement for the Docker command-line interface. It takes care of setting up the NVIDIA host driver environment inside Docker containers for proper execution.
./nvidia-docker <docker-options> <docker-command> <docker-args>
Conclusion
The new M40 and M4 GPUs are powerful accelerators for hyperscale data centers. Combined with the NVIDIA Hyperscale Suite and GPU deployment capabilities in Apache Mesos and Docker containers, developers of data center services will be ready to handle the massive data of the world’s users.
Learn more about the NVIDIA FFmpeg plug-ins, GPU REST Engine, Image Compute Engine, and NVIDIA-docker.
