
Developing a high-performing Hebrew large language model (LLM) presents distinct challenges stemming from the rich and complex nature of the Hebrew language itself. The intricate structure of Hebrew, with words formed through root and pattern combinations, demands sophisticated modeling approaches. Moreover, the lack of capitalization and the frequent absence of punctuation like periods and commas in Hebrew text poses difficulties for tokenizers in properly segmenting sentences.
For example, the word הקפה could mean “the coffee” or “encircle,” depending on the pronunciation. The flexible word order allowable in Hebrew syntax adds another layer of complexity. Compounding these issues is the high degree of morphological ambiguity, where a single word can indicate multiple meanings, depending on the context. In addition, the Hebrew language avoids diacritical marks that convey vowel sounds, which further complicates accurate text processing and understanding.
Overcoming these unique linguistic hurdles is crucial for training an AI model capable of truly comprehending and generating high-quality Hebrew text. The DictaLM-2.0 suite of Hebrew-specific LLMs was trained on classical and modern Hebrew texts, and has recently led the Hugging Face Open Leaderboard for Hebrew LLMs.
This post explains how to use NVIDIA TensorRT-LLM and NVIDIA Triton Inference Server to optimize and accelerate inference deployment of this model at scale. TensorRT-LLM is a comprehensive open-source library for compiling and optimizing LLMs for inference on NVIDIA GPUs. Triton Inference Server is an open-source platform that streamlines and accelerates the deployment of AI inference workloads to create production-ready deployment of LLMs.
What is a low-resource language?
In the context of conversational AI, low-resource languages are those without large amounts of data available for training. While this post focuses on Hebrew, the same challenges are prevalent when dealing with low-resource languages in general, including the languages of Southeast Asia. LLMs such as SEA-LION and SeaLLM address these challenges by training on specific data that better represents the regional cultures and languages. Both of these LLMs are available as NVIDIA NIM microservices that are currently available for prototyping in the NVIDIA API catalog.
The majority of LLMs are primarily trained on English text corpora, leading to an inherent bias towards Western linguistic patterns and cultural norms. This results in LLMs struggling to accurately capture the nuances, idioms, and cultural contexts specific to non-Western languages and societies.
Additionally, the lack of high-quality digitized text data for many non-Western languages exacerbates the resource scarcity issue, making it difficult for LLMs to learn and generalize effectively across these languages. Consequently, LLMs often fail to reflect the culturally appropriate expressions, emotional connotations, and contextual subtleties inherent in non-Western languages, leading to potential misinterpretations or biased outputs.
Contemporary LLMs also rely on statistically-driven tokenization methods. Due to the underrepresentation of low-resource languages in training datasets, these tokenizers often have a limited set of tokens for each of these languages. This results in poor compression efficiency for these languages. As a consequence, generating text in these languages becomes more challenging, and producing lengthy content requires significantly more computational resources and complexity.
Optimization workflow
For the first optimization use case, we focused on DictaLM 2.0 Instruct, a model continually pre-trained on Mistral 7B with a custom tokenizer trained for Hebrew, and then further aligned for chat purposes.
git clone https://huggingface.co/dicta-il/dictalm2.0-instruct
Set up TensorRT-LLM
To begin, clone the latest version of TensorRT-LLM. TensorRT-LLM incorporates many advanced optimizations we’ll use in this example.
git lfs install
git clone -b v0.11.0 https://github.com/NVIDIA/TensorRT-LLM.git
cd TensorRT-LLM
Pull the Triton container
Next, pull the Triton Inference Server container with TensorRT-LLM backend:
docker pull nvcr.io/nvidia/tritonserver:24.07-trtllm-python-py3
docker run --rm --runtime=nvidia --gpus all --volume
${PWD}/../dictalm2.0-instruct:/dictalm-2-instruct --volume
${PWD}:/TensorRT-LLM --entrypoint /bin/bash -it --workdir /TensorRT-LLM
nvcr.io/nvidia/tritonserver:24.07-trtllm-python-py3
Create the FP16 TensorRT-LLM engine
Convert the Hugging Face checkpoint to TensorRT-LLM format:
python examples/llama/convert_checkpoint.py --model_dir /dictalm-2-instruct/
--output_dir fp16_mistral/ --tp_size 1 --dtype float16
Then build the optimized engine:
trtllm-build --checkpoint_dir fp16_mistral/ --output_dir
fp16_mistral_engine/ --max_batch_size 64 --max_output_len 1024
--paged_kv_cache enable
Quantize to INT4 and create the efficient TensorRT-LLM engine
To benefit from the more efficient INT4 numeric weight representation, saving significant memory bandwidth and capacity, perform post-training quantization (PTQ). PTQ requires a representative small dataset to update the weights while maintaining statistical similarity. The provided script will pull an English calibration dataset, but you could also update the script to pull and use data from your target language. TensorRT-LLM performs the quantization while converting to the TensorRT-LLM format.
PTQ will enable the model to obtain comparable results to the FP16 model. It is expected that, even after PTQ, the LLM will demonstrate some level of decrease in accuracy. Though this is out of scope, it should be mentioned that to overcome any performance decrease you can look into quantization aware training, or train with FP8 or FP4 using an NVIDIA transformer engine along with newer NVIDIA H100 and NVIDIA B200 GPUs.
Download the Dicta calibration dataset consisting of a mix of Hebrew and English tokens. This will significantly improve INT4 accuracy, in comparison to using a default English calibration dataset.
git clone
https://huggingface.co/datasets/dicta-il/dictalm2.0-quant-calib-dataset
Quantize to INT4 using the calibration dataset:
python3 examples/quantization/quantize.py --kv_cache_dtype fp8 --dtype
float16 --qformat int4_awq --output_dir ./quantized_mistral_int4
--model_dir /dictalm-2-instruct --calib_size 32
Then build the engine:
trtllm-build --checkpoint_dir quantized_mistral_int4/ --output_dir
quantized_mistral_int4_engine/ --max_batch_size 64 --max_output_len 1024
--weight_only_precision int4 --gemm_plugin float16 --paged_kv_cache enable
Deploy the model with Triton Inference Server
After the engine is built, you can deploy the model with Triton Inference Server. This will help reduce setup and deployment time. The Triton Inference Server backend for TensorRT-LLM leverages the TensorRT-LLM C++ runtime for rapid inference execution and includes techniques like in-flight batching and paged KV caching. You can access Triton Inference Server with the TensorRT-LLM backend as a prebuilt container through the NVIDIA NGC catalog.
First, set up TensorRT-LLM backend:
git clone -b v0.11.0
https://github.com/triton-inference-server/tensorrtllm_backend.git
cd tensorrtllm_backend
cp ../TensorRT-LLM/fp16_mistral_engine/*
all_models/inflight_batcher_llm/tensorrt_llm/1/
Dealing with customized tokenizers requires adopting the workaround workflow. In the case of low-resource languages, tokenizers often feature different vocabularies, unique token mapping, and so on.
First, set up the tokenizer directories:
HF_MODEL=/dictalm-2-instruct
ENGINE_PATH=tensorrtllm_backend/all_models/inflight_batcher_llm/tensorrt_llm/1
python3 tools/fill_template.py -i
all_models/inflight_batcher_llm/preprocessing/config.pbtxt
tokenizer_dir:${HF_MODEL},tokenizer_type:auto,triton_max_batch_size:32,preprocessing_instance_count:1
python3 tools/fill_template.py -i
all_models/inflight_batcher_llm/postprocessing/config.pbtxt
tokenizer_dir:${HF_MODEL},tokenizer_type:auto,triton_max_batch_size:32,postprocessing_instance_count:1
python3 tools/fill_template.py -i
all_models/inflight_batcher_llm/ensemble/config.pbtxt
triton_max_batch_size:32
python3 tools/fill_template.py -i
all_models/inflight_batcher_llm/tensorrt_llm/config.pbtxt
triton_backend:tensorrtllm,triton_max_batch_size:32,decoupled_mode:True,m
ax_beam_width:1,engine_dir:${ENGINE_PATH},max_tokens_in_paged_kv_cache:40
96,max_attention_window_size:4096,kv_cache_free_gpu_mem_fraction:0.5,excl
ude_input_in_output:True,enable_kv_cache_reuse:False,batching_strategy:in
flight_fused_batching,max_queue_delay_microseconds:0
rm -r all_models/inflight_batcher_llm/tensorrt_llm_bls
Then launch with Triton Inference Server:
docker run --rm -it \
-p8000:8000 -p8001:8001 -p8002:8002 \
--gpus 0 \
--name triton_trtllm_server \
-v $(pwd)/dictalm2.0-instruct:/dictalm-2-instruct \
-v $(pwd):/workspace \
-w /workspace \
nvcr.io/nvidia/tritonserver:24.07-trtllm-python-py3 tritonserver \
--model-repository=/workspace/tensorrtllm_backend/all_models/inflight_bat
cher_llm --model-control-mode=NONE --log-verbose=0
Inference with Triton Inference Server
To send requests to and interact with the running server, you can use one of the Triton client libraries or send HTTP requests to the generated endpoint.
To get started with a simple request, use the following curl command to send HTTP requests to the generated endpoint. We specifically ask a challenging question, requiring both detailed knowledge as well as cultural context: “Do you have recipes for Yemenite soup?”
curl -X POST localhost:8000/v2/models/ensemble/generate
-d \
'{
"text_input": "[INST]האם יש לך מתכונים למרק תימני?[/INST]",
"parameters": {
"max_tokens": 1000,
"bad_words":[""],
"stop_words":[""]
}
}'
The LLM generates a detailed response with a detailed recipe. It adds cultural context by noting when this dish is typically served, as well as several variations (Figure 1).

Performance results
For performance experiments and measurement, we ran the model with different acceleration configurations on a single NVIDIA A100 GPU. Figure 2 shows the latency to complete different numbers of async requests of 1024 output tokens, comparing the baseline Python backend (blue line) to Tensor-RT LLM (red line). The non-accelerated Python backend grows in latency as the number of requests increases, whereas TensorRT-LLM provides very effective scaling throughout.
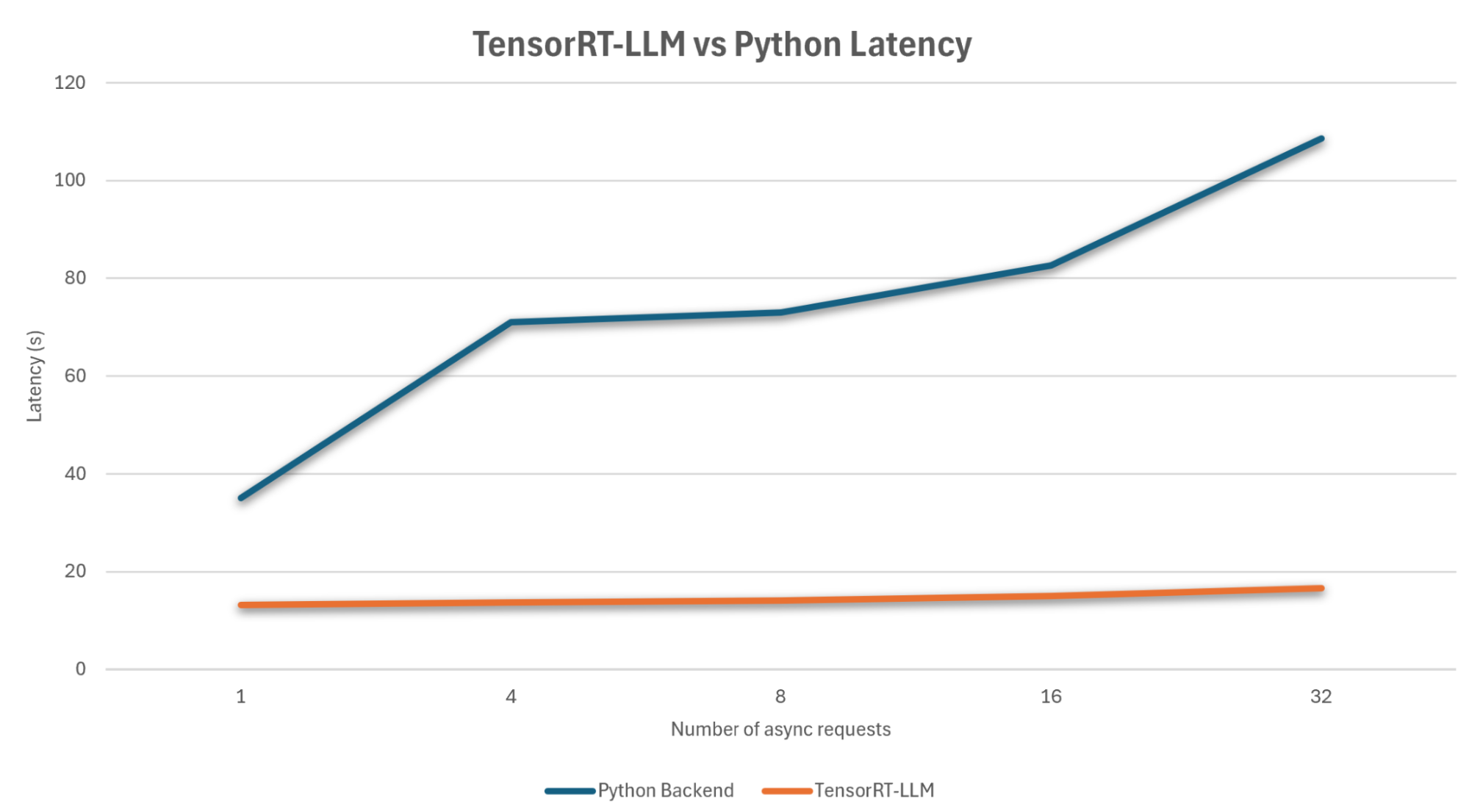
Conclusion
With baseline support for many popular LLM architectures, TensorRT-LLM makes it easy to deploy, experiment, and optimize with a variety of LLMs. Together, TensorRT-LLM and Triton Inference Server provide an integrative toolkit for optimizing, deploying, and running LLMs efficiently.
To get started, visit NVIDIA/TensorRT-LLM on GitHub to download and set up the TensorRT-LLM open-source library, and experiment with other multi-language LLMs, such as Baichuan-7B.
