
Ultra-low latency and reliable packet delivery are critical requirements for modern applications in sectors such as the financial services industry (FSI), cloud gaming, and media and entertainment (M&E). In these domains, microseconds of delay or a single dropped packet can have a significant impact—causing financial losses, degraded user experiences, or visible glitches in media streams.
Why low-latency and dropless packet delivery matter
The following use cases are common examples where solutions with low latency are commonly required:
- FSI: Algorithmic trading and market data distribution demand deterministic, low-latency networking. Delays or packet losses can result in missed trading opportunities or incorrect decision-making.
- Cloud gaming: Cloud gaming platforms must deliver real-time rendering and input feedback. High latency or packet drops lead to lag, poor responsiveness, and user dissatisfaction, which is especially problematic given the rapid growth of the cloud gaming market.
- M&E: Professional live video production and broadcast workflows (e.g., SMPTE ST 2110) require precise timing and zero packet loss to avoid visible artifacts and ensure compliance with industry standards.
For these use cases, achieving high packet rates, sustaining bandwidth at line rates, and minimizing or eliminating packet drops are essential. Traditional networking stacks struggle to meet these demands, particularly as network speeds scale to 10/25/50/100/200 GbE and beyond.
NVIDIA Rivermax: a high-performance streaming solution
NVIDIA Rivermax is a highly optimized IP-based cross-platform software library designed to deliver exceptional performance for media and data streaming applications. By using advanced NVIDIA GPU-accelerated computing technologies and high-performance network interface cards (NICs), Rivermax achieves a unique combination of ultra-high throughput, precise packet pacing in hardware, minimal latency, and low CPU utilization. This makes it ideal for demanding workloads where efficiency and responsiveness are critical.
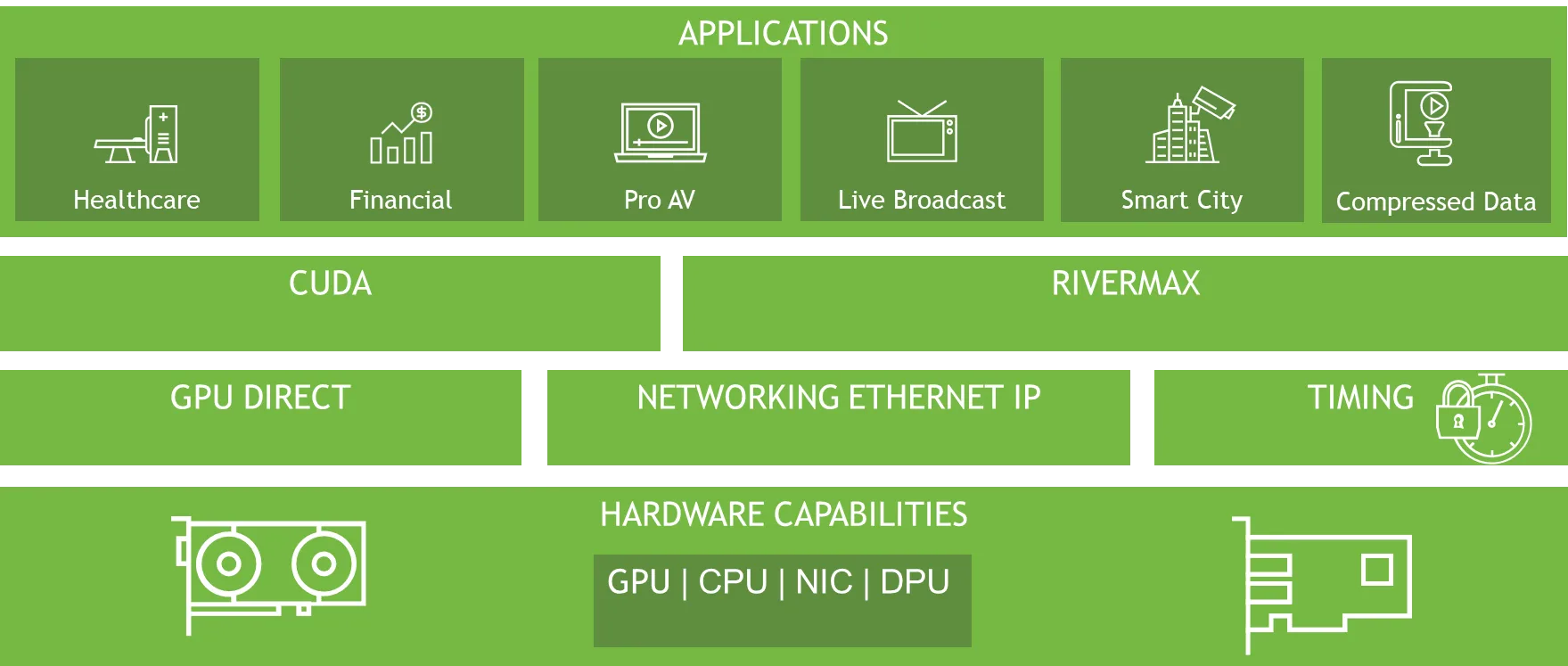
Rivermax’s innovative architecture is built on several key technologies:
- Kernel bypass: By bypassing the traditional OS kernel, it minimizes overhead and enables direct data transfer between user-space memory and the NIC. This reduces latency and maximizes throughput for high-performance streaming.
- Zero-copy architecture: Rivermax eliminates unnecessary memory copies by transferring data directly between the GPU and NIC. This approach reduces PCIe transactions, lowers CPU usage, and accelerates data processing.
- GPU acceleration: Using NVIDIA GPUDirect technology, Rivermax facilitates data movement between the GPU and NIC without the CPU. This offloading mechanism ensures efficient resource utilization while maintaining high throughput.
- Hardware-based packet pacing: Rivermax ensures precise timing for data streams by implementing packet pacing directly in hardware. This is essential for applications requiring strict compliance with standards like SMPTE ST 2110-21 for professional media workflows.
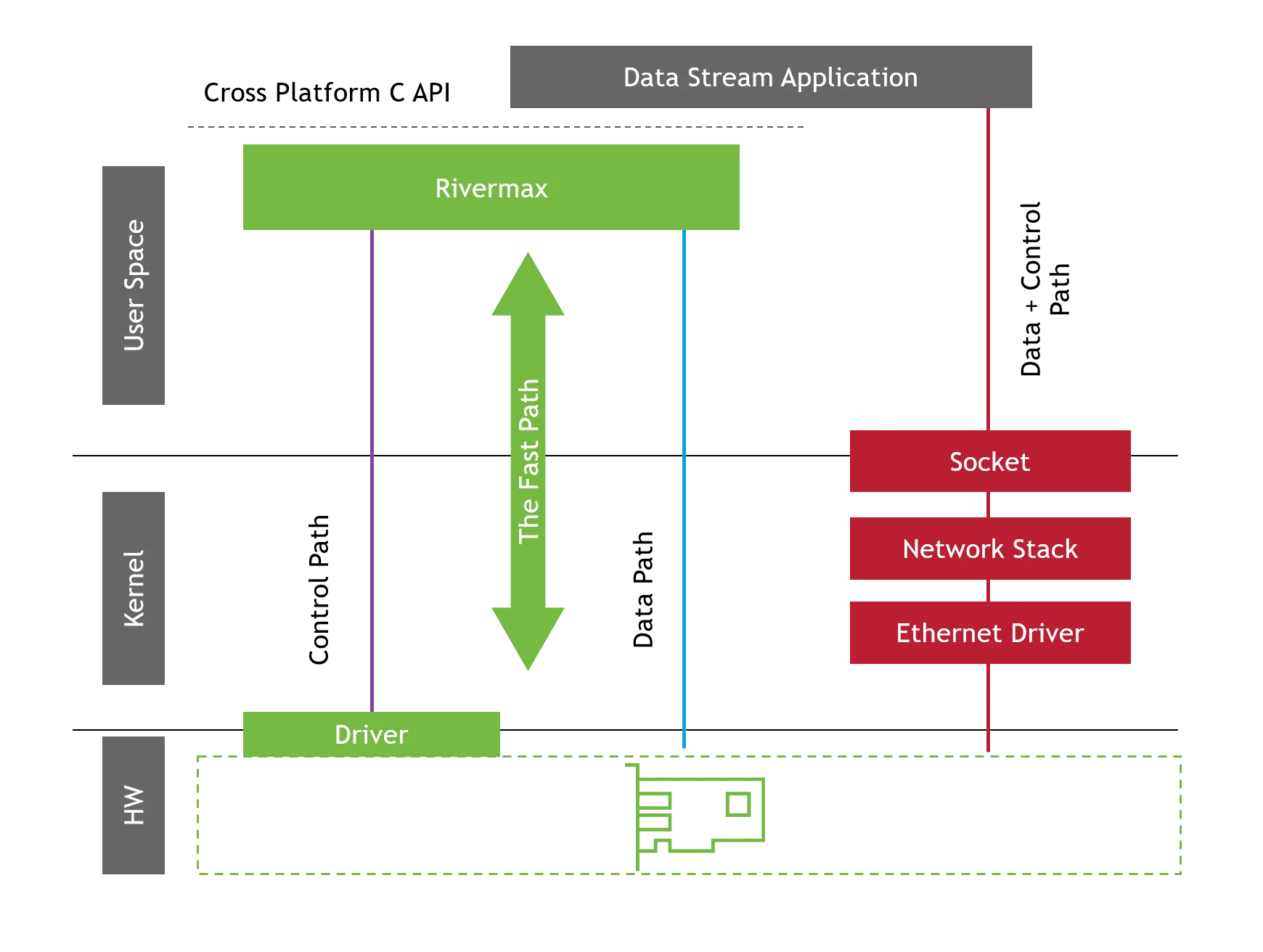
NEIO FastSocket based on Rivermax technology: reliable low-latency sockets
As network speeds have rapidly increased, traditional socket-based communication struggles to keep pace, especially at 10/25 GbE and higher. FastSockets from NEIO Systems Ltd. is a flexible middleware library designed for high-performance UDP and TCP communications, overcoming these limitations. Its key focus is to deliver dropless technology with the lowest latency and highest bandwidth/throughput.
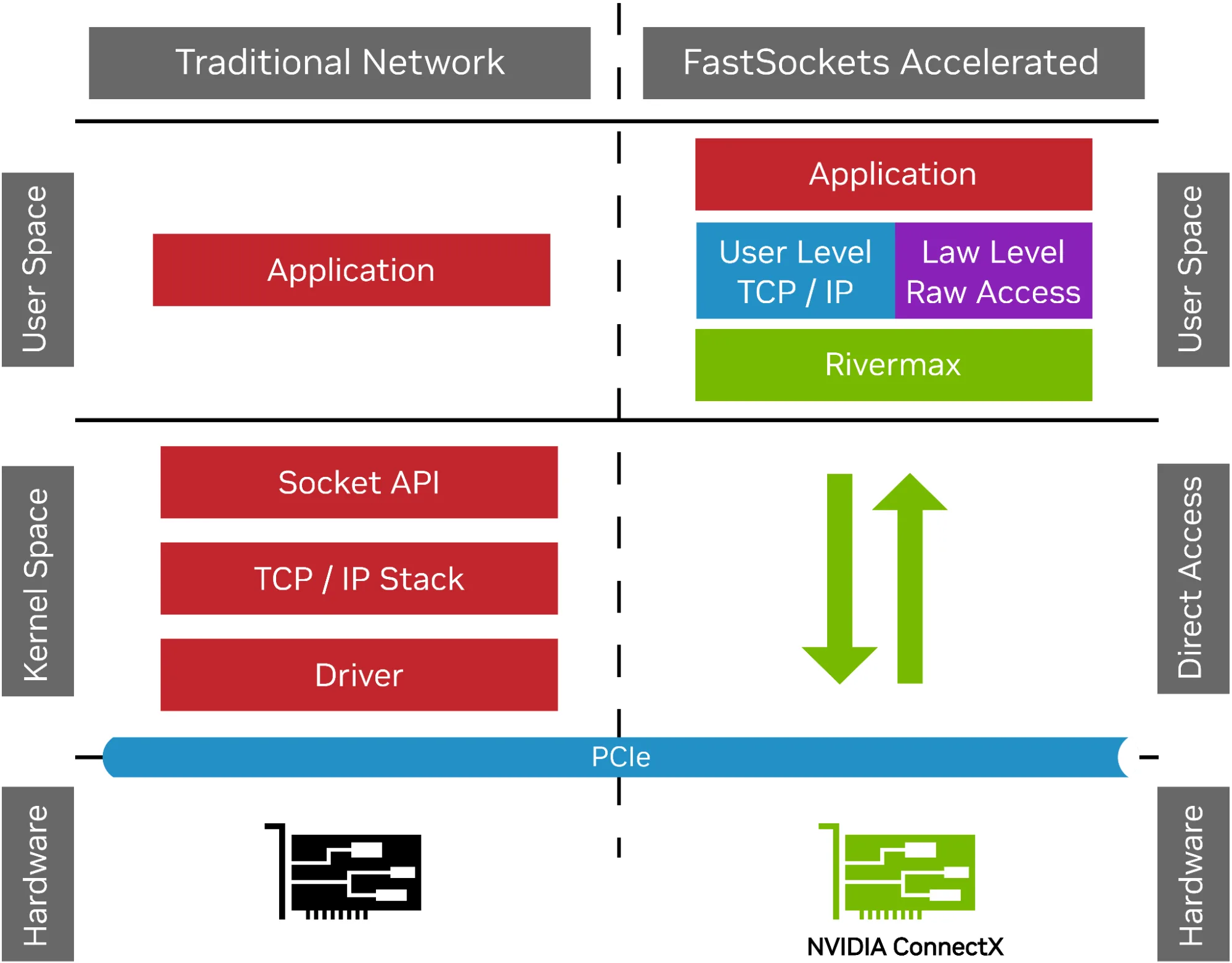
Using NVIDIA ConnectX adapters, FastSockets leverages Rivermax technologies, enabling kernel bypass techniques that deliver data directly from the NIC to the application, minimizing latency and maximizing packet rates.
Ensuring dropless User Datagram Protocol reception for high-performance networking
In modern networking applications, where speed and efficiency are paramount, reliable data transmission is critical. The User Datagram Protocol (UDP) is widely used for scenarios that require low-latency data transfer, such as video streaming in machine vision and financial market data distribution.
A key characteristic of UDP is that it is connectionless and does not guarantee reliable delivery, unlike protocols like TCP. While this design enables faster data transmission, it also introduces the risk of packet loss. In time-sensitive applications, achieving dropless UDP reception is essential for optimal performance.
Preventing retransmissions and reducing latency
UDP does not include built-in mechanisms for packet recovery, so any lost data must be managed by the application itself. If packet loss occurs, it can trigger manual retransmissions or create data gaps. When retransmissions are required, they can introduce significant delays, directly impacting latency-sensitive applications. For instance, FastSockets media extensions support the GigE Vision (GVA) protocol for machine vision, where even minor packet loss can cause visible glitches or buffering delays.
Algorithmic trading systems are another example, where millisecond delays can lead to lost opportunities or incorrect decisions. Retransmitted data may arrive too late to be useful. Latency is therefore critical. FastSockets delivers packets directly from the NIC to the application, minimizing latency by leveraging the foundational features provided by Rivermax.
Maximizing throughput and minimizing system overhead
The system overhead of kernel-based sockets cannot keep up with the highest packet rates, even when optimizations like CPU binding and enlarged socket buffers are applied. As packet rates increase, the kernel becomes the limiting factor, leading to packet drops. Kernel bypass techniques, as enabled by Rivermax, place data directly into application buffers, supporting dynamic buffer sizes and a zero-copy approach that eliminates unnecessary data copies. Lower overhead also means reduced serialization delays, with more packets being distributed efficiently.
Benchmarking
This section presents benchmarks that highlight the superior performance achieved by leveraging Rivermax technology. FastSockets is available for both Linux and Windows; the focus here is on Windows performance, where Rivermax offers unique advantages. Note that the RIO benchmark is limited in scope, as RIO capabilities are constrained for comprehensive networking performance evaluation.
Metrics and methodology
The benchmarks evaluate three key networking performance metrics: sustained throughput, average packet rate, and end-to-end latency. These metrics are critical for applications requiring high throughput with minimal delay, such as financial trading, cloud gaming, and professional media workflows. Comparisons are made between traditional sockets, Registered I/O (RIO), and FastSockets through Rivermax using NVIDIA ConnectX-6 adapters operating at 25 GbE. Evaluation with RIO is limited, reflecting the restricted functionality provided by RIO in this context.
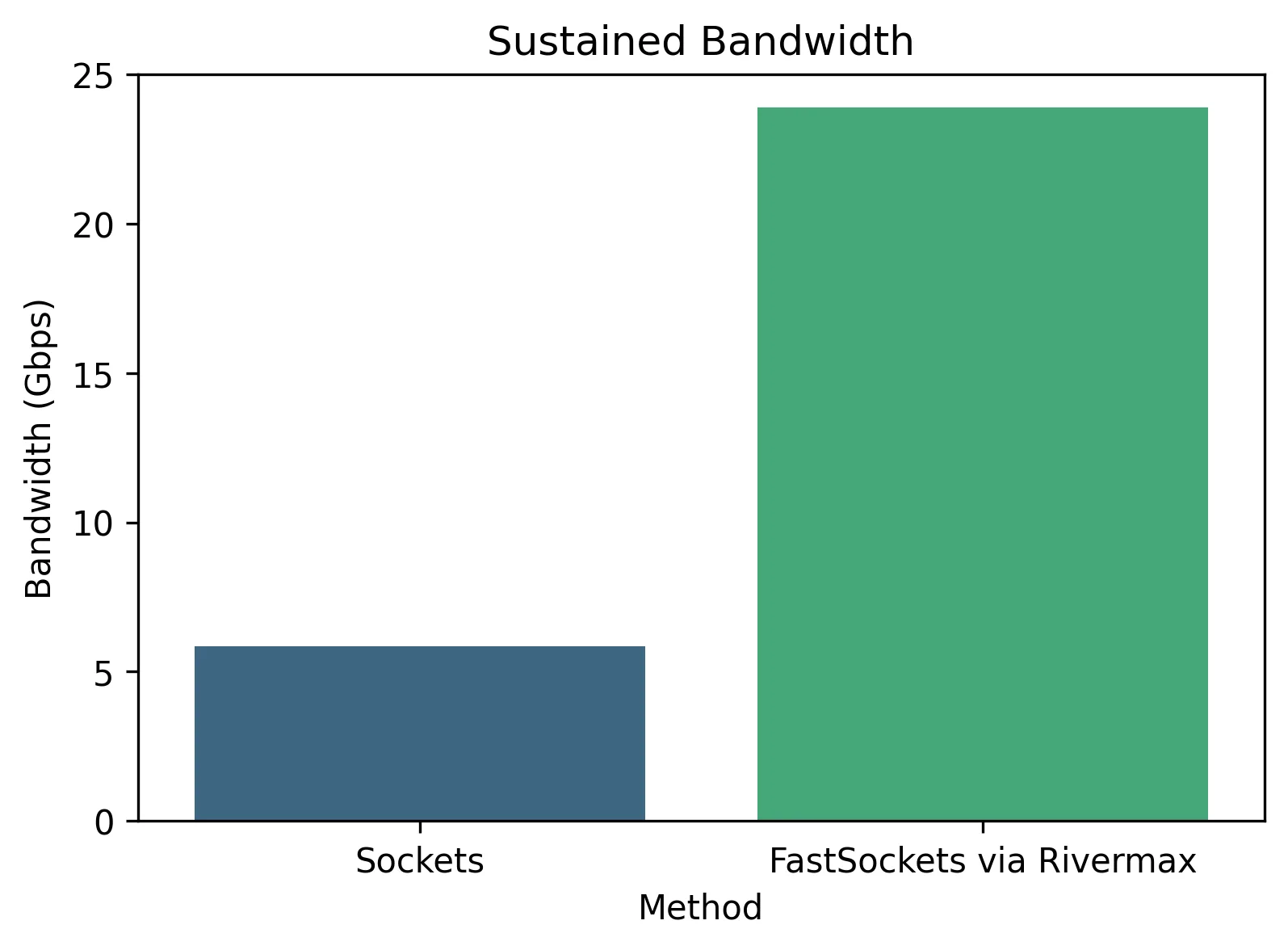
Sustained throughput
Sustained throughput measures the maximum data transfer rate that can be consistently maintained between the NIC and the application. Achieving line-rate throughput is essential for high-performance streaming and real-time data delivery. As shown in Figure 4, FastSockets using Rivermax achieves a sustained line-rate throughput, while traditional sockets fall significantly short.
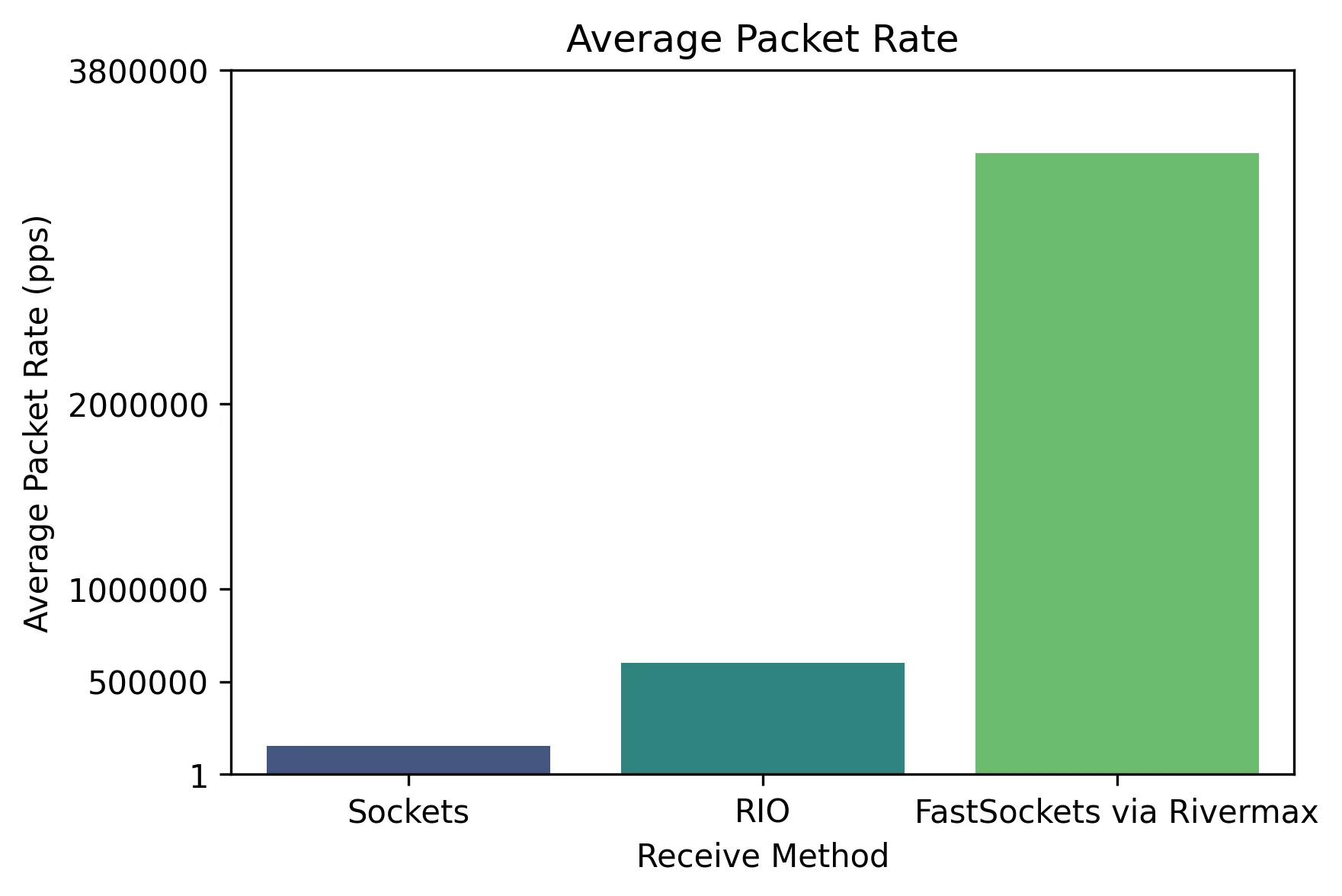
Average packet rate
The average packet rate reflects the number of packets processed per second, a crucial measure for workloads involving frequent, small data transfers. Higher packet rates reduce serialization delays for timely data delivery. In Figure 5, FastSockets via Rivermax delivers a dramatic increase in average packet rate, outperforming both sockets and RIO by a wide margin.
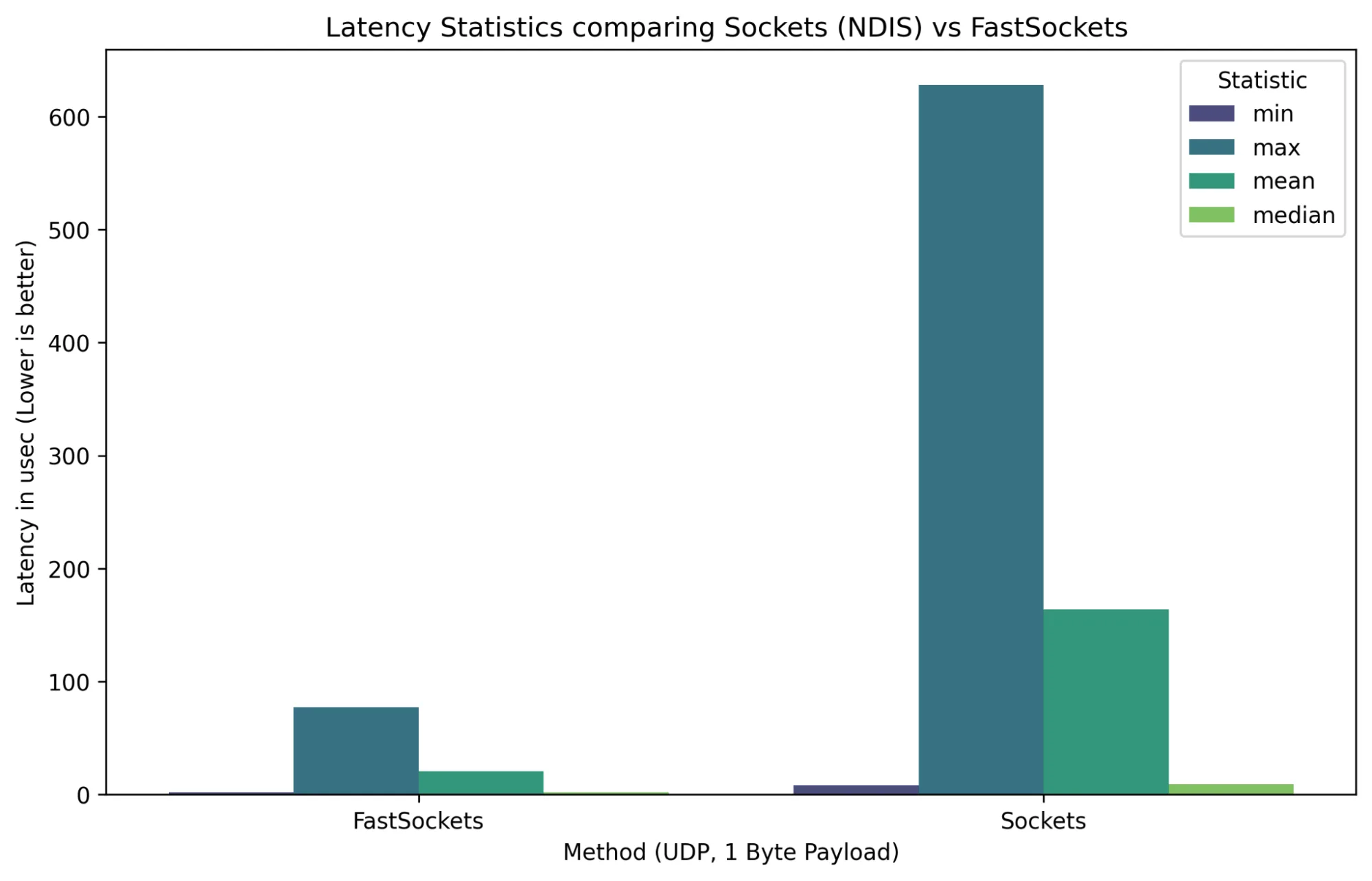
Latency
Latency measures the time taken for data to travel from the NIC to the application and back, directly impacting responsiveness in real-time applications. In this context, latency can be defined as half round-trip times, which provides a practical measure of the one-way delay experienced by packets. Lower latency is critical for use cases such as algorithmic trading and live media streaming. As shown in Figure 6, FastSockets demonstrate significantly lower minimum, mean, median, and maximum latency compared to traditional sockets, making it ideal for latency-sensitive environments.
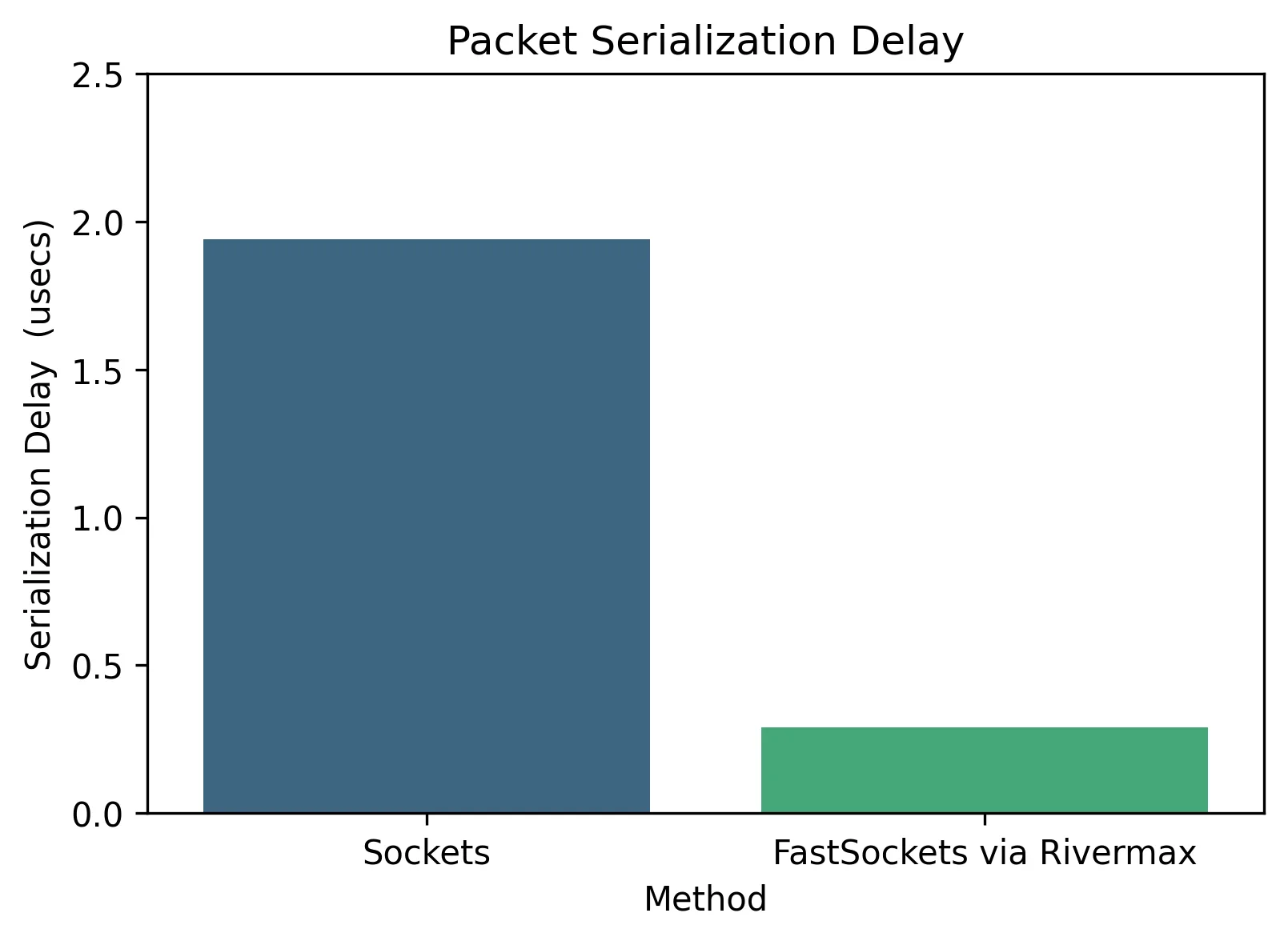
Serialization delay
Serialization delay refers to the time required to place a packet onto the network medium, which directly impacts the rate at which data can be transmitted from the application to the network. Lower serialization delay is crucial for improving overall throughput and reducing end-to-end latency, especially in high-performance and real-time applications. As shown in Figure 7, FastSockets via Rivermax achieves a substantially lower packet serialization delay compared to traditional sockets, further enhancing its suitability for demanding networking environments.
What’s next in GPUDirect technology?
GPUDirect technology is poised to improve the performance of trading systems by enabling direct memory access between NICs and GPUs, bypassing the CPU to reduce latency. With high-frequency market data received from exchanges, GPUDirect enables this data to stream directly into GPU memory, enabling rapid execution of AI models to detect critical patterns, such as sudden price movements or order book imbalances.
By accelerating this data pipeline, the system can make faster inferences, enabling trading software direct access to advanced quoting algorithms (pause/cancel/widening markets) during periods of high risk or volume, all without burdening the CPU.
AI models deployed for these use cases are carefully optimized for ultra-low-latency inference directly on GPUs, using technologies such as GPUDirect. These models generally include:
- Anomaly detection models (autoencoders, Isolation Forests, VAEs) to identify abnormal patterns that may precede volatility or manipulation, such as sudden changes in order book dynamics.
- Time series forecasting models (LSTM, TCNs, transformer-based models) to predict short-term market movements and trigger responses if sharp price moves are anticipated.
- Classification models for event detection (CNNs, gradient-boosted trees, simple neural nets) to classify market states and halt quoting during risky or abnormal events.
- Reinforcement learning agents (DQN, policy gradient, actor-critic) that adaptively learn optimal actions (quote, adjust, stop) based on evolving markets to maximize returns or minimize risk.
Feature engineering is performed on real-time order book snapshots, order flow imbalances, trade statistics, and other relevant data. Inference is further optimized using ONNX, NVIDIA TensorRT, and NVIDIA CUDA, with models distilled and quantized for minimal size and latency.
With Rivermax and GPUDirect powering zero-copy access, market data is streamed directly from high-speed NICs into GPU memory, eliminating PCIe bottlenecks. This architecture enables AI models to process and respond to market changes almost instantaneously, critical for deciding when to quote or pull out during volatile periods.
As these AI and GPU acceleration technologies continue to evolve, their integration with high-performance networking solutions like Rivermax will unlock new levels of speed, intelligence, and adaptability, transforming not only trading but any latency-sensitive domain.
Get started with Rivermax and FastSockets for your ultra-low-latency and zero-packet applications:
