
In every meeting, call, crowded room, or voice-enabled app, technology has a core question: who is speaking, and when? For decades, answering that question in real-time transcription was almost impossible without specialized equipment or offline batch processing.
NVIDIA Streaming Sortformer, an open, production-grade diarization model, changes what’s possible. It’s designed for low latency in realistic, multi-speaker scenarios, and integrates with NVIDIA NeMo and NVIDIA Riva. You can drop it into transcription pipelines, live voicebot orchestration, or enterprise meeting analytics.
Main capabilities
NVIDIA Streaming Sortformer provides the following key capabilities, making it a robust and flexible solution for a variety of real-time applications:
- Frame-level diarization with tags (e.g., spk_0, spk_1).
- Precision time stamps for every labeled utterance.
- Robust 2–4+ speaker tracking with minimal latency.
- Efficient GPU inference, ready for NeMo and Riva workflows.
- Optimized for English, but tested successfully on Mandarin meeting data and the 4-speaker CALLHOME non-English set (low DER), indicating strong performance across many languages.
Benchmark results
Here’s how Streaming Sortformer performs in Diarization Error Rate (DER), lower is better.

Sample use cases
Streaming Sortformer enables practical solutions in a variety of real-time multi-speaker scenarios, including:
- Meetings and productivity: Live, speaker-tagged transcripts and next-day summaries.
- Contact centers: Separate agent/customer streams for QA or compliance.
- Voicebots and AI assistants: More natural dialog, correct turn-taking, and identity tracking.
- Media and broadcast: Automatic labeling for editing and moderation.
- Enterprise and compliance: Auditable, speaker-resolved logs for regulatory needs.
See the following demo.
Architecture and internals
Streaming Sortformer is a speaker diarization model that uniquely sorts speakers based on when they first appear in an audio recording. Under the hood, it acts as an encoder that first uses a convolutional pre-encode module to process and compress the raw audio, before feeding it to a series of conformer and transformer blocks that work together to analyze the conversational context and sort the speakers.
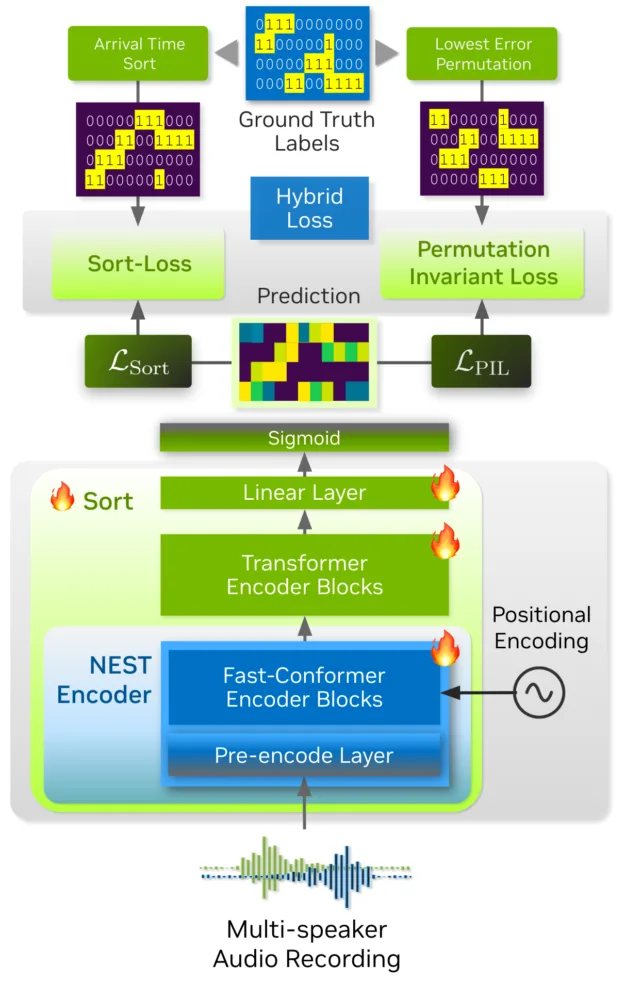
To handle live audio, Streaming Sortformer processes the sound in small, overlapping chunks. It uses a clever memory buffer called an Arrival-Order Speaker Cache (AOSC) that tracks all speakers previously detected in the audio stream. This enables the model to compare speakers in the current chunk with those in the previous, ensuring a person is consistently identified with the same label throughout the stream. Ultimately, the AOSC buffer makes real-time, multi-speaker tracking practical and accurate.



Figure 5. A three-speaker example of arrival-time order speaker cache for Streaming Sortformer

Figure 6. A four-speaker example of arrival-time order speaker cache for Streaming Sortformer
Responsible AI, limitations, and next steps
Here is a list of boundaries and best practices to keep in mind:
- Designed for up to four speakers in a conversation. In cases of more than four speakers, the performance degrades, as the model is currently unable to produce more than four outputs.
- Optimized for English, but can be used for other languages such as Mandarin Chinese.
- To get the best performance for a specific domain or language, fine-tuning is recommended.
- Real-world tests confirm resilience to overlaps, but very rapid turn-taking or heavy crosstalk may still challenge accuracy.
- Roadmap includes:
- Extension to higher speaker counts.
- Improving performance on various languages and in challenging acoustic conditions.
- Full integration with Riva and NeMo agentic/voicebot pipelines
Conclusion
With Streaming Sortformer, developers and organizations have an open, real-time diarization solution for real conversation in voice-enabled, multi-speaker applications—not just in research but in every production setting.
Ready to build?
- Download, deploy, or test Streaming Sortformer on Hugging Face. Review the support matrix.
- Try NVIDIA Riva NIM for ASR, TTS, and Translation, supported by NVIDIA AI Enterprise.
- For questions or troubleshooting, visit the NeMo GitHub, Riva Tutorials, or the Riva developer forums.
For a deeper dive into the technical details and background on Streaming Sortformer, check out our latest research on Offline Sortformer, available on arXiv.
