NVIDIA AI Enterprise 是一个端到端、安全的云原生 AI 软件套件。最近发布的 NVIDIA AI Enterprise 3.0 引入了新功能,以帮助优化生产 AI 的性能和效率。本文提供了以下新功能及其工作原理的详细信息。
- Magnum IO GPUDirect Storage
- GPU virtualization with VMware vSphere 8.0
- Red Hat Enterprise Linux ( RHEL ) KVM 8 和 9
- 分数多 v GPU 支架
- 扩展对 NVIDIA AI 的支持
生产 AI 功能
NVIDIA AI Enterprise 3.0 版本中的新 AI 工作流有助于缩短生产 AI 的开发时间。这些工作流是常见 AI 用例的参考应用程序,包括联络中心智能虚拟助理、音频转录和数字指纹。
未加密的预训练模型也首次包括在内,确保了 AI 的可解释性,并使开发人员能够查看模型的权重和偏差,了解模型偏差。
NVIDIA AI Enterprise 现在支持 NGC catalog 中发布的所有 NVIDIA 人工智能软件。开始 NGC 之旅的开发者现在可以无缝过渡到 NVIDIA AI Enterprise 订阅,并利用 NVIDIA Enterprise 支持 50 多个 AI 框架、预训练模型和 SDK 。
基础结构性能特征
NVIDIA AI Enterprise 3.0 包含许多有助于优化基础设施性能的新功能,因此您可以充分利用您的 AI 投资,并最大限度地节省成本和时间。下面将更详细地解释这些功能。
Magnum IO GPU 直接存储
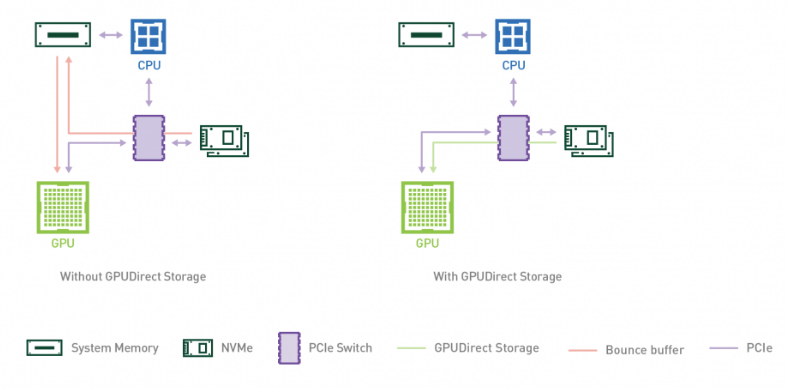
企业现在可以利用 NVIDIA AI Enterprise 3.0 部署中 Magnum IO GPUDirect Storage 的性能优势来加速和扩展其 AI 工作负载。 GPUDirect Storage 1.4 在本地或远程存储和 GPU 内存之间提供了直接数据路径,为复杂的工作负载提供了无与伦比的性能。
GPUDirect Storage 为在 GPU 上消费或生成数据而不需要 CPU 处理的应用程序简化了存储和 GPU buffer 之间的数据流。它使用远程直接内存访问( RDMA )在直接路径上快速将数据从存储移动到 GPU 内存,通过消除通过缓冲区进行的额外复制,减少了延迟并减轻了 CPU 的负担。
GPUDirect Storage 提供了显著的性能改进,与基线 NumPy 相比, NVIDIA DALI 的深度学习推理性能提高了 7.2 倍。有关详细信息,请参见 NVIDIA Magnum IO 。
NASA Mars Lander 演示 使用 NVIDIA IndeX 和 GPUDirect Storage 以及 27000 多个 NVIDIA GPU 来模拟反向推进,当利用 PCIe 交换机和 NVLinks 与 GPUDirect 存储时,带宽增益为 5 倍。
要了解更多信息,请参阅 guide for running NVIDIA AI Enterprise with GPUDirect Storage 。
GPU VMware vSphere 8.0 的虚拟化功能
NVIDIA AI Enterprise 3.0 引入了对 VMware vSphere 8 的支持,其中包括一些可加快性能和提高操作效率的功能。 VMware 环境现在可以将最多八个虚拟 GPU 添加到一个 VM 中,使 v GPU 的数量比以前的版本增加了一倍。这提高了大型 ML 模型的性能,并为复杂的 AI 和 ML 工作负载提供了更高的可扩展性。
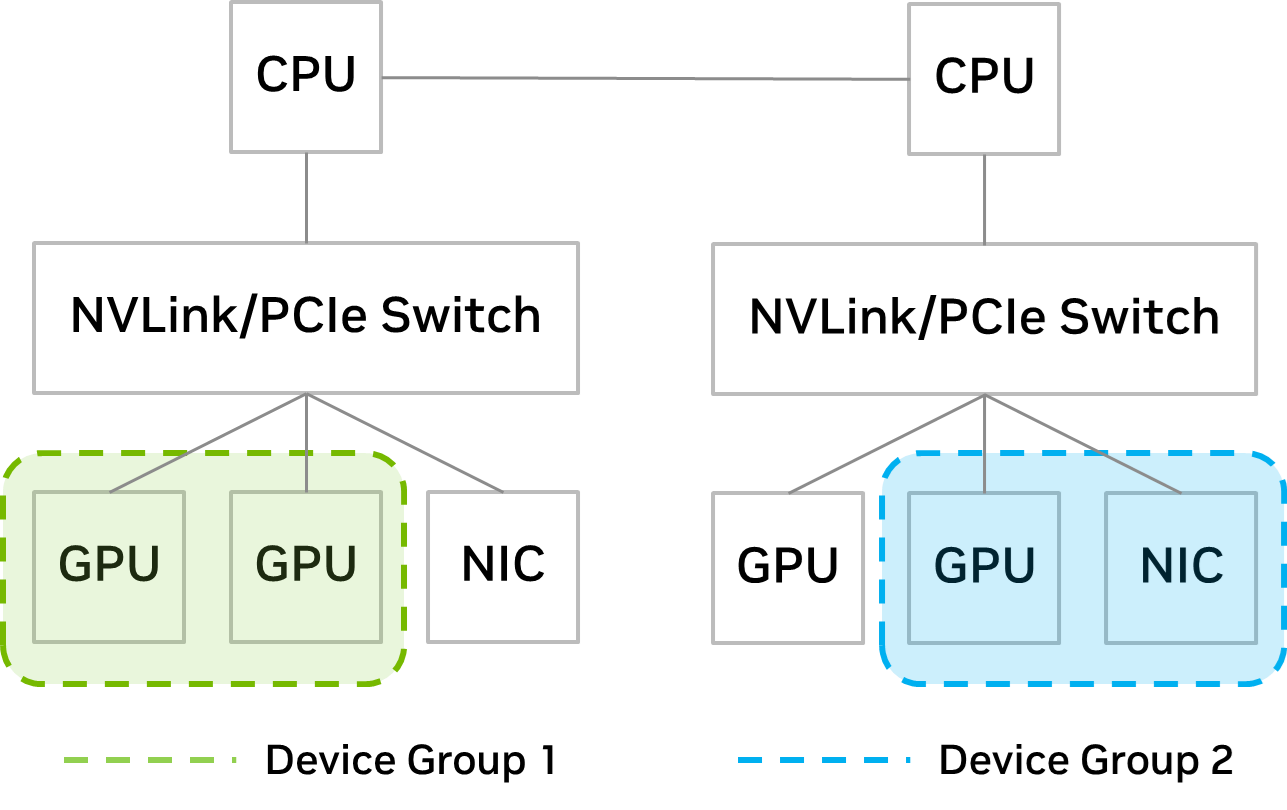
通过引入设备组, IT 管理员现在可以更好地控制 VM 的放置。 Distributed Resource Scheduler ( DRS )是 vSphere 中包含的一个管理工具,用于确定最佳虚拟机位置。
新的设备组功能提供了在硬件级别(通过 NVLink 或 PCIe 交换机)彼此配对的 PCIe 设备的详细信息, IT 管理员可以从中选择一个子集,以向 VM 提供 DRS 放置决策。
通过设备组, IT 管理员可以确保将设备的子集一起分配给 VM 。例如,如果用户希望扩大 GPU 以加速大型模型, IT 管理员可以创建一个包含 GPU 的设备组,其中包含 NVLinks 。如图 2 所示,如设备组 1 所示。
如果用户希望跨多个服务器扩展以进行分布式培训,设备组可以由共享同一 PCIe 交换机的 GPU 和 NIC 组成。这在图 2 中显示为设备组 2 。
Red Hat Enterprise Linux KVM
NVIDIA AI Enterprise 3.0 扩展了虚拟化支持,包括 Red Hat Enterprise Linux 8.4 、 8.6 、 8.7 、 9.0 和 9.1 ,使企业能够将 KVM 功能扩展到其 AI 工作负载。使用 RHEL KVM ,管理员可以将多达 16 个虚拟 GPU 添加到一个 VM 中,为计算密集型工作负载提供了指数级的更快处理。有关使用 RHEL KVM 部署 NVIDIA AI Enterprise 的更多信息,请访问 NVIDIA AI Enterprise Documentation Center 。
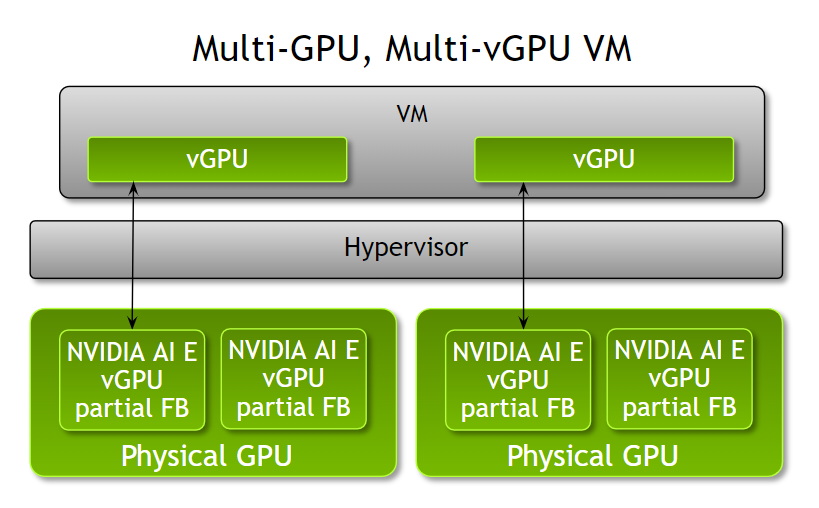
分数多 v GPU 支架
管理员现在可以使用 NVIDIA AI Enterprise 3.0 为单个虚拟机提供多个分数 v GPU ,从而提高了根据工作负载优化虚拟机配置的灵活性。在此版本之前, VM 只能通过 GPU 的单个部分、完整 GPU 或每个 VM 的多个 GPU 来加速。
管理员现在有了更大的灵活性,可以根据工作负载计算需求为 VM 分配多个部分 v GPU 配置文件。例如,当运行具有不同计算需求的多个推理工作负载时,管理员可以根据工作负载内存需求为 VM 分配 NVIDIA A100 Tensor Core GPUs 的部分配置文件和不同数量的帧缓冲区。
请注意,所有部分型材必须是相同的板类型和系列。这些部分 v GPU 配置文件可以从一个或多个物理 GPU 中分配。此功能在 VMware vSphere 8 和 RHEL KVM 8 和 9 上都可用。
扩展对 NVIDIA AI 的支持
NVIDIA AI Enterprise 为 NGC 目录中发布的所有 NVIDIA 人工智能软件提供支持,该目录现在包含 50 多个框架和模型。所有受支持的型号都标有“ NVIDIA AI Enterprise supported ”,以帮助用户轻松识别受支持的软件。
结论
借助 NVIDIA AI Enterprise 的最新 3.0 版本,企业可以通过最新的性能和效率优化缩短生产 AI 的开发时间。 NVIDIA LaunchPad 上的 Get Started with NVIDIA AI Enterprise 。 LaunchPad 可在私人加速计算环境(包括动手实验室)中即时、短期访问 NVIDIA AI Enterprise 软件套件。
Register for NVIDIA GTC 2023 for free 并于 3 月 20 日至 23 日加入我们,了解 NVIDIA AI Enterprise 和其他技术如何用于解决棘手的 AI 挑战。




