导读:本文将介绍如何在GPU上高效地部署语音AI模型,主要内容如下:
- 语音AI部署背景介绍
- 基于GPU的ASR解决方案介绍
- 基于Triton的ASR部署方案
- 基于GPU的ASR decoding
- NST训练方法优化
- 基于Tensor-LLM的Whisper模型加速推理
- 基于GPU的TTS解决方案介绍
- 基于FastPitch+Hifi-GAN的Streaming TTS 效果优化
- 关于声音克隆的参考工作
- 未来规划
▌语音AI部署背景介绍
首先介绍下搭建语音识别和语音生成类工作管线的痛点与挑战。

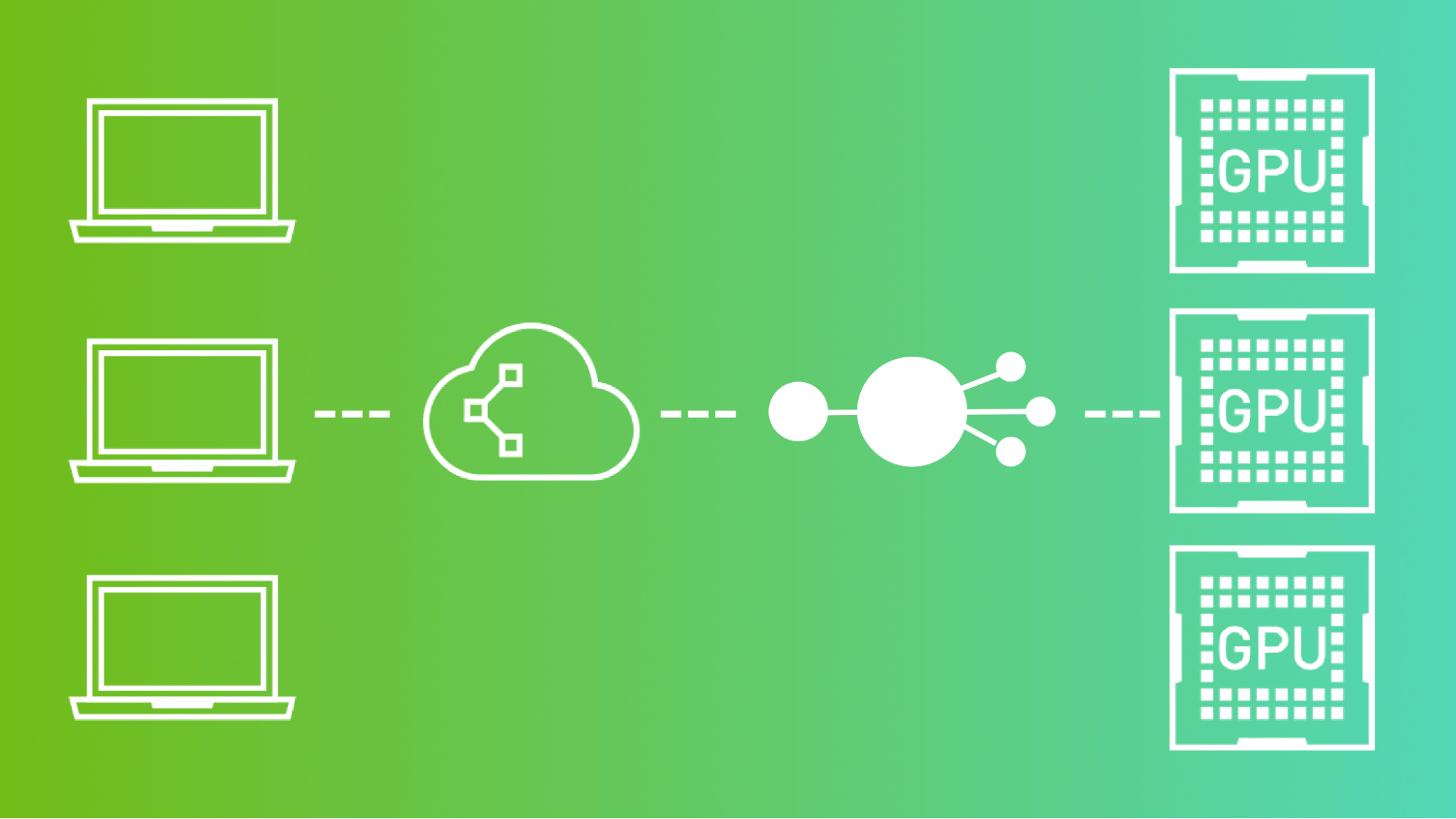
首先,AI模型的部署,有端上和云上两种不同的方式。在云上部署时,常常面对服务延时高、并发路数低、部署成本高等问题。我们希望通过更有效地利用 GPU 资源,服务更多的用户,同时降低部署成本。
第二,语音 AI 与传统的 CV 算法不同,其工作管线更为复杂,通常包含多个模块,并且需要处理流之间的状态维护、管理以及状态切换。这使得开发难度大,有时简单的 Python 脚本调度并不高效。
第三,当前许多从事语音 AI 服务的实践者开始探索使用大型模型,如Whisper,来完成语音识别和语音模型的任务。然而,使用大型模型带来了更大的计算需求,因此迫切需要提升大语言模型在 ASR、TTS领域中的推理效率。
▌基于GPU的ASR解决方案介绍
- 基于Triton的ASR部署方案
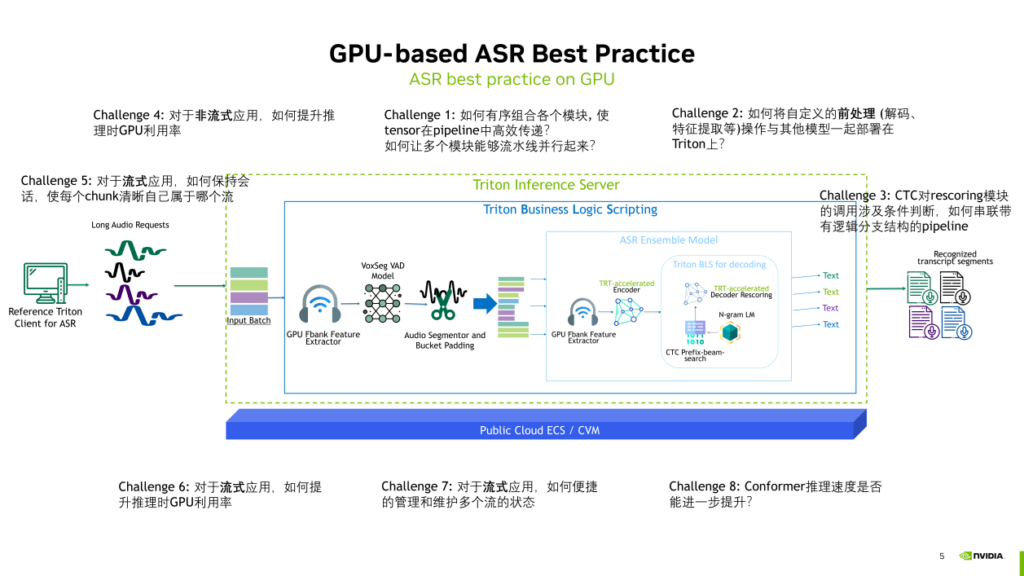
过去一年中,NVIDIA与WeNet社区紧密合作,利用Triton Inference Server这一推理服务的部署框架,构建了在GPU上部署WeNet模型的工作管线。在WeNet的架构下,进行了基本的音频特征提取(Fbank特征),并采用了U2++或Conformer的编码器来处理音频信号。解码的方式有很多选择,我们通过CTC的prefix Beam search和Transformer 或者 Conformer 的 decoder 一起完成(类似于U2++解码)。
整体来讲,通过TensorRT加速模型推理,同时通过Triton部署整个管线。
在利用Triton部署整个WeNet管线的过程中,解决了如下一些问题:
- Challenge1:如何有序组合各个模块, 使 tensor在pipeline中高效传递? 如何让多个模块能够流水线并行起来?
在使用Triton时,它不仅能够有序组合多个模块,还允许用户外接更多所需的模块。例如,通过Triton的 business logic scripting功能,可以添加VAD模块或者进行音频切分,并将其与ASR模块连接起来。这样的流程串接都可以在Triton中实现,并且各个部分可以并行进行,实现高效的流水线运行。
- Challenge2:如何将自定义的前处理(解码、特征提取等)操作与其他模型一起部署在Triton上?
Triton不仅能够部署深度学习模型,还支持许多自定义操作,包括Python和C++的自定义前后处理。这些操作可以与深度学习模型对接,这也是Triton提供的custom backend功能。因此,NVIDIA的custom backend可以与deep learning、framework backend共同部署,并实现它们之间的桥接。
- Challenge3:CTC对rescoring模块的调用涉及条件判断,如何串联带有逻辑分支结构的pipeline?
在部署前后处理中,尤其是在解码模块,我们经常需要进行条件判断等逻辑操作。这些逻辑操作可以用 Python 的business logic scripting 去实现,从而建立带有逻辑分支结构的工作关系。
- Challenge4:对于非流式应用,如何提升推理时GPU利用率?
对于非流式应用,Triton提供了动态批处理和多模型实例并行执行等功能。这些功能可以在将ASR服务部署在GPU上时,最大化GPU的利用率,提升整个服务的吞吐。
- Challenge5:对于流式应用,如何保持会话,使每个chunk清晰自己属于哪个流?
对于流式应用,Triton内置了流式状态管理器,能够有序地管理整个流式推理过程。每个流中的每个chunk都能清晰地知道自己属于哪个流,状态管理器在状态发生切换时能够自动地管理这个过程。最终,在推理完成后,客户端也能明确地了解每个chunk的识别结果属于最初输入的哪个流。这种有序的管理确保了流式应用中音频的输入输出流程的清晰性。
- Challenge6:对于流式应用,如何提升推理时GPU利用率?
针对流式应用,我们致力于提升GPU利用率。通过动态批处理,能够有效推理多个流中的多个chunk,使GPU以批处理方式高效运行,从而最大程度地提升GPU资源利用率。
- Challenge7:对于流式应用,如何便捷地管理和维护多个流的状态?
在流式应用方面,NVDIA提供了便捷的流状态管理功能。这包括对多个流的状态进行有效管理和维护,确保整个流式应用的状态处理更加高效和便捷。
- Challenge8:Conformer推理速度是否能进一步提升?
对于类似Conformer和Transformer这样的模型,我们不断探索加速方法,主要集中在TensorRT这一加速框架。通过TensorRT对模型本身的推理速度进行优化,有效提高整个服务的效率。
基于Triton的ASR部署方案实际上可以扩展到更通用的ASR工作管线,并不局限于WeNet的模型和管线。我们利用Triton,可以在很多其他的开源ASR方案架构下尽可能的提升ASR服务的吞吐。例如,以下是NVIDIA对除WeNet之外其他一些开源ASR项目贡献的Triton部署方案,如果感兴趣可以通过下方链接了解。
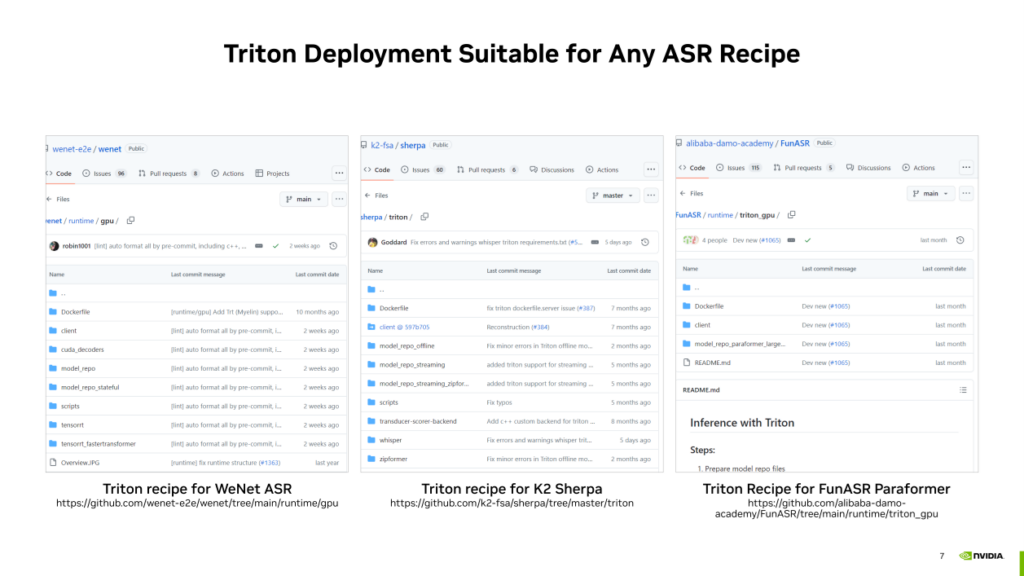
- 基于GPU的ASR的decoding

接下来介绍在解码方面的加速优化工作,主要包括两个方面。
- 对于CTC prefix Beam search的CUDA加速实现
之前,CTC prefix beam search主要在CPU上运行,而深度学习模型(如Conformer、Transformer、Zip Former)通常在GPU上运行。这导致深度学习模型和CTC解码的prefix beam search在GPU和CPU上分别运行,可能产生一些CPU到GPU之间的拷贝开销。为解决这个问题,我们通过CUDA实现了CTC prefix beam search,将解码循环包含在一个GPU的kernel中,并实现了beam search的查找。
这个方案速度非常快,相较于Touch Audio中的Flashlight decoder在CPU上的版本,我们的CUDA decoder的速度提升了十倍以上,而且精度相比于Flashlight decoder也更好。如果感兴趣,可以通过Torch Audio直接尝试。但值得注意的是,CTC目前还不支持热词和语言模型,它只是一个单纯的prefix beam search,这一局限性可能会影响在生产环境中的应用。
- 基于CUDA的TLG解码
因为以上问题,我们还提供了另一种解码实现,基于CUDA的TLG解码。TLG解码在包括Kaldi在内的很多ASR系统上应用广泛。TLG解码的速度相较于CTC加上一些blank skip的手段后,可能没有太明显的优势。但CUDA的TLG使得深度学习模型和解码全链路都在GPU上运行,避免了CPU到GPU之间的内存复制开销。有时CPU的压力也很大,因为CPU可能会运行其他前后处理操作,因此使用CUDA基础的TLG解码可以缓解CPU上的压力。TLG解码的优势在于精度相比CTC更好,虽然速度可能稍慢一些,因此可以根据需要选择是否使用基于CUDA的TLG解码。如果想尝试,可以在WeNet的开源方案中找到相关信息。
- NST训练方法优化
在算法方面,我们聚焦于半监督的ASR训练,采用了NST方法。

首先介绍一下NST的训练过程:先使用有监督数据训练teacher模型,然后使用该模型在无监督数据上运行,生成伪标签。通过筛选,选择有用或合理的带有伪标签的数据,与有监督数据一起训练student模型。训练完成后,student模型成为新的teacher模型,进行反复迭代。这种方式充分利用了有监督和无监督数据,得到了我们需要的ASR模型。
然而,NST方法面临的一个主要挑战就是噪声。如果有监督和无监督数据集的Domain相似,该方法产生的模型精度是可靠的。但如果Domain之间存在较大差异,模型在某些领域上表现较差。为了解决领域差异问题,我们提出了一种语言模型筛选的方法。
该方法的核心思想是我们通过大量实验发现CER Hypo (带目标domain语言模型的解码识别结果与不带语言模型解码方式识别的结果之间的CER) 与CER Label (带目标domain语言模型的解码识别结果与无标注数据的真实标签之间的CER)总是呈正相关性的,一般前者高后者也会较高,前者低后者也会较低。由于我们实际上并没有无标注数据的真实标签,因此我们可以用前者的大小来估计后者,从而判断teacher模型生成的伪标签是否可靠。
这样一来,我们可以为CER Hypo一个阈值,据此来筛选无监督数据,剔除那些CER Hypo较高(也意味着CER Label较高)的数据。经过这一筛选过程,使用剩下的数据进行学生模型的训练,以提高在无监督数据集上的模型精度。
在实验中,我们观察到使用LM filter后,CER在不同数据集上都有显著下降,分别为11.13% (AIshell1有标注数据+WenetSpeech无标注数据)和15.86% (AIShell2有标注数据+WenetSpeech无标注数据)。这表明LM filter对于降低无监督数据中的噪声、提高模型性能起到了积极的作用。
- 基于Tensor-LLM的Whisper模型加速推理
第四方面的工作是关于ASR 大模型的推理加速,其中 Whisper 模型在多语种 ASR 领域取得了显著进展。尽管 Encoder-Decoder 算法在很久以前就存在,但是 Whisper 模型证明了大语言模型在 ASR 领域的强大能力,能够使用单一模型准确预测多种不同语言的 ASR 任务。然而,使用 Whisper 进行 ASR 推理面临一些挑战,主要包括模型的大小带来的推理速度下降和对 GPU 显存的大量消耗。
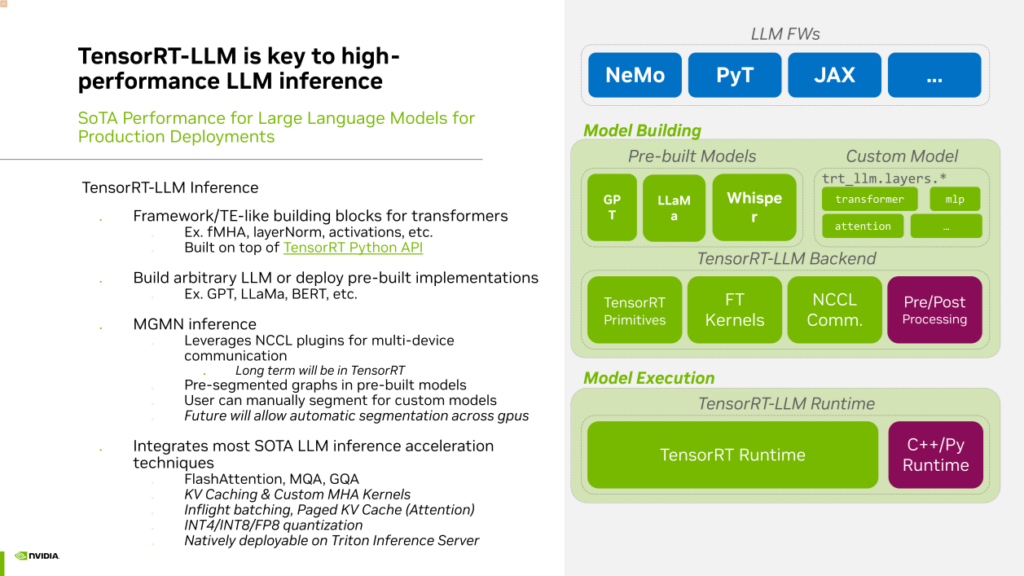
为了尽可能加速大语言模型的推理,解决当前使用现有框架进行 Whisper 推理可能会遇到的问题,在今年十月,NVIDIA推出了大语言模型推理加速框架,名为TensorRT-LLM(TensorRT Large Language Model)。TensorRT-LLM 是建立在TensorRT基础上的,专门用于加速大语言模型推理的开源框架。使用TensorRT-LLM 进行推理,可以利用其中提供的各种layer或OP的 API 来构建自己的网络结构。
在TensorRT-LLM中,我们提供了许多预先构建的模型示例,包括GPT、LLAMA、百川、chatGLM等主流模型。当然,TensorRT-LLM也天然地支持Whisper。TensorRT-LLM用于大型语言模型的推理,具有多项优势,有助于提高效率。如果需要进行多机多卡推理,TensorRT-LLM具有内置的通信组件,支持Tensor并行和流水线并行。
此外,我们还整合了社区中几乎所有的大型语言模型推理加速技术,如Flash Attention、MQH、GQA、KV Cache,以及用于服务端优化的Inflight Batching (Continuous Batching)和Paged Attention等。还采用低精度量化技术,如INT4、INT8、FP8,以提高推理速度。
最后,TensorRT-LLM是原生支持与Triton Inference Server结合使用的,通过TensorRT-LLM加速的大型语言模型,可以轻松在Triton上进行服务部署。这是NVIDIA提出的一种非常实用且目前性能最先进的大型模型推理框架。

在TensorRT-LLM中,我们利用了一些特性来提升Whisper模型的推理速度。
首先是对Whisper的encoder & decoder的GPU kernel进行了优化。利用TensorRT-LLM中的Fused MHA kernel,应用Flash Attention的优化技术,加速处理输入是一个长序列的多头注意力推理速度。在解码器生成token的过程中,利用Masked Multi-Head Attention(MHA)的高性能GPU kernel,用于处理解码过程中的Q等于1,而KV相对较长的情况。除了多头注意力之外,还针对推理过程中的一些矩阵运算、Layernorm等操作,专门实现了高性能的GPU kernel,以替代PyTorch中相对低效的原生kernel。此外,我们对op与op之间,layer和layer之间进行了一些融合操作,以提高运行效率。
其次,是对大语言模型推理中KV Cache的优化。在Whisper中,有两种类型的Key / Value缓存由TensorRT-LLM管理。第一种是self attention的缓存,它在解码器迭代生成token的过程中持续生成。第二种是cross attention的key和value,在编码器完成后,通过几个线性层获取cross attention的key和value的缓存,这也被缓存以用于后续的每个token生成。
此外,TensorRT-LLM还支持对Whisper进行INT 8的量化。它将权重量化到INT 8的精度,但计算时仍然使用FP 16。这种做法的优势包括节省显存和减少weight从显存复制到寄存器的IO开销。
这些优化使得Whisper在V100上的推理速度比Faster Whisper提高了近40%,同时保持更低的识别错误率。TensorRT-LLM还支持批量推断,而Faster Whisper不支持。
这些优势使得TensorRT-LLM成为Whisper推理的高效框架,而且我们还在逐步实现其他一些功能,包括Inflight batching、Paged attention和Speculative decoding等等。

使用TensorRT-LLM加速Whisper,步骤如下:
首先,需要一个经过训练的Whisper模型,然后使用TensorRT进行模型初始化。由于Whisper是在TensorRT中原生支持的,所以只需运行初始化步骤,读取权重并构建网络即可。对于不是原生支持的模型,需要使用Python API重新构建模型,但Whisper不需要。
完成初始化后,进入第二步,即engine building过程,这是一个编译的过程,根据Whisper网络结构为每个操作和每个层找到最高效的kernel实现,并进行一些kernel fusion或layer fusion的优化操作。
最终得到TensorRT-LLM的Whisper engine后,可以使用TRT-LLM提供的C++或Python运行,或直接部署到Triton Inference Server上运行。这个流程相对简单。如果在生产中使用Whisper模型,建议使用TensorRT-LLM进行高性能加速,可显著提升Whisper推理速度并节省成本。
▌基于GPU的TTS解决方案介绍
- 基于FastPitch+Hifi-GAN的Streaming TTS 效果优化
NVIDIA在 TTS 领域也做了一些供大家参考的工作,例如提供了高效的流式 TTS 部署方案,利用 TensorRT 加速模型推理速度,并通过 Triton Inference Server 实现了高效的流水线。今年,我们对流式 TTS 的效果进行了提升,主要集中在两个方面。
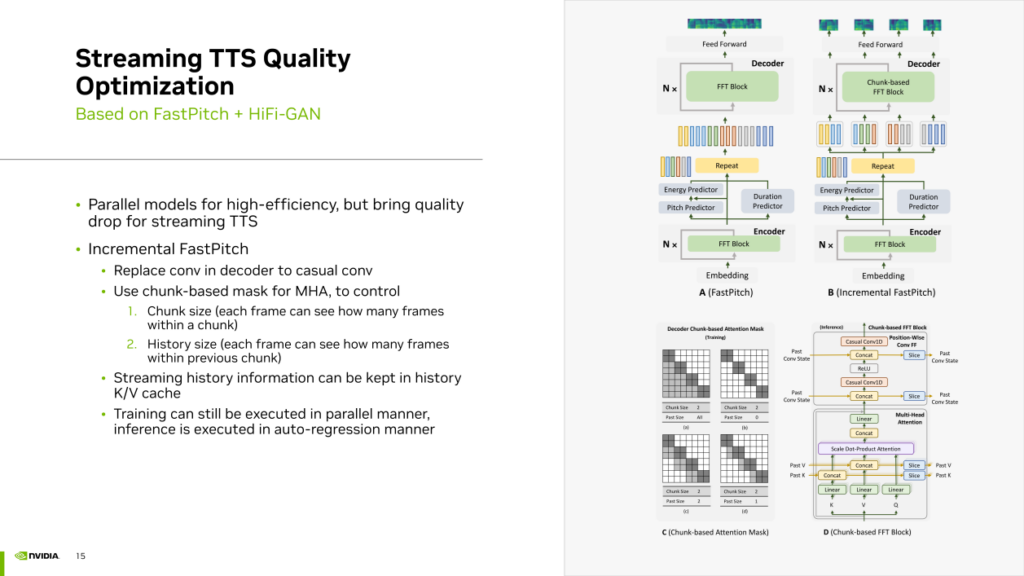
首先,我们发现许多 TTS 模型采用并行模型,其结构通常是非自回归的,并使用卷积等网络层一次性生成所有音频帧。然而,这种并行模型并不适合流式 TTS 合成。尤其在 chunk 之间的接缝处可能存在抖动瑕疵。因此,我们引入了一种Incremental FastPitch的方法,将完全并行的 FastPitch 转换为基于 chunk 的 FastPitch。通过使用casual卷积替代常规普通卷积,并采用基于 chunk 的mask MultiHeadAttention,可以控制 chunk size 和 history size。这种Mask使得每个 chunk 内的帧不仅可以看到chunk内的其他真,还能够看到之前chunk的帧,通过这种方式实现了基于 chunk 的 FastPitch并且使得chunk之间的信息可以互相关联提升流式TTS的质量。Incremental FastPitch的训练过程仍然可以利用带mask的注意力机制来实现并行运算。在推理过程中,可以逐个 chunk 地生成,实现类似迭代的自回归生成过程,从而在流式生成中考虑到历史信息,提升生成效果。
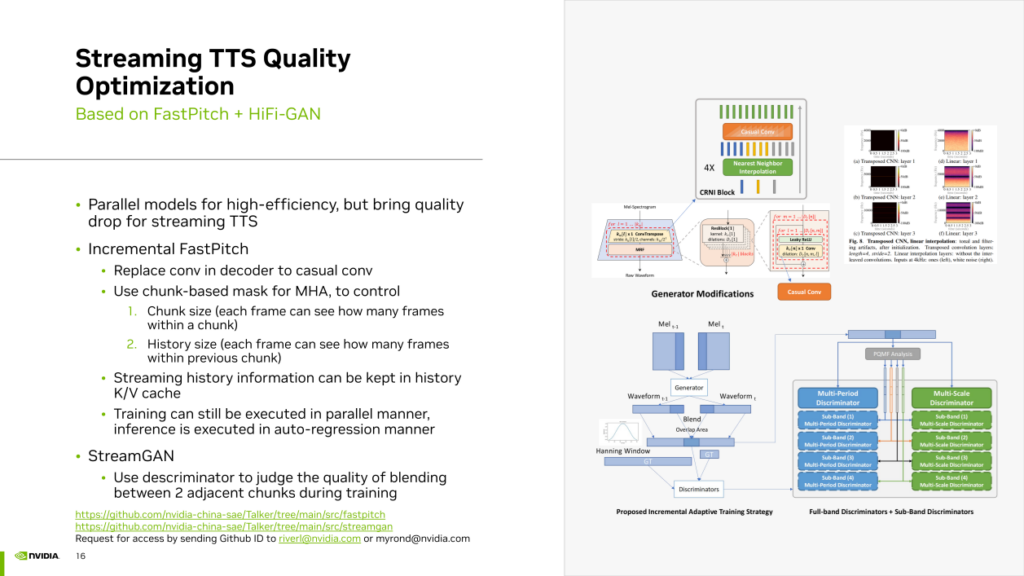
其次,我们采用了 stream GAN 逻辑,即在 Hifi GAN 的训练中,利用 discriminator 强制学习如何让Generator生成两个能够良好拼接的连续音频 chunk。
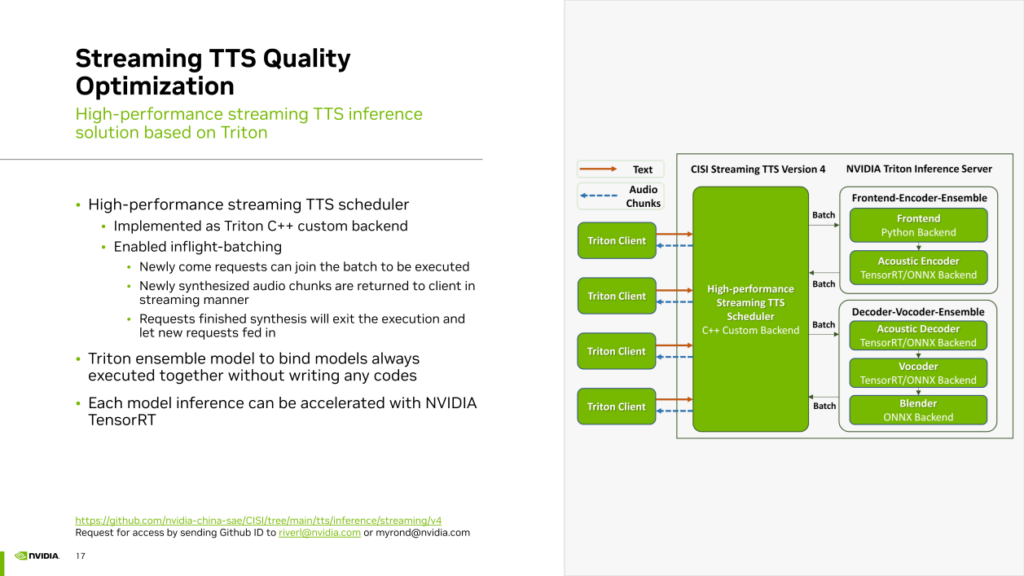
基于先前提到的两种流式 TTS 优化方案,我们开发了相应的推理服务框架,同样基于 Triton Inference Server 加上 TensorRT。
在这个框架中,使用 Triton 的 C++ custom backend实现了高性能的 TTS 调度器。该调度器负责组织整个 TTS 管线的各个模块,并在这个过程中实现了“Inflight batching”,即连续批处理。新进来的请求可以随时加入到正在执行的batch中。新合成的音频 chunk 会以流式方式返回给 Triton Client。已完成的请求会立即终止,为新到达的请求腾出slot。
此外,我们使用 Triton 的 Ensemble Model 功能以零代码的方式组合了需要同时运行的多个模块,如Front End、声学模型的编码器总是要对输入的文本共同做一次处理。我们使用 Triton Ensemble 将它们无缝组合在一起,而无需编写任何串联代码,实现了零代码的模型串联功能。对于声学模型的解码器、vocoder以及最后的 Chunk 拼接的 Blender,同样使用 Triton ensemble 功能以零代码的方式将它们组合在一起。最后,对于每个模型,包括声学模型的encoder和vocoder,都使用 TensorRT 来加速推理。
- 关于声音克隆的参考工作
关于声音克隆的工作
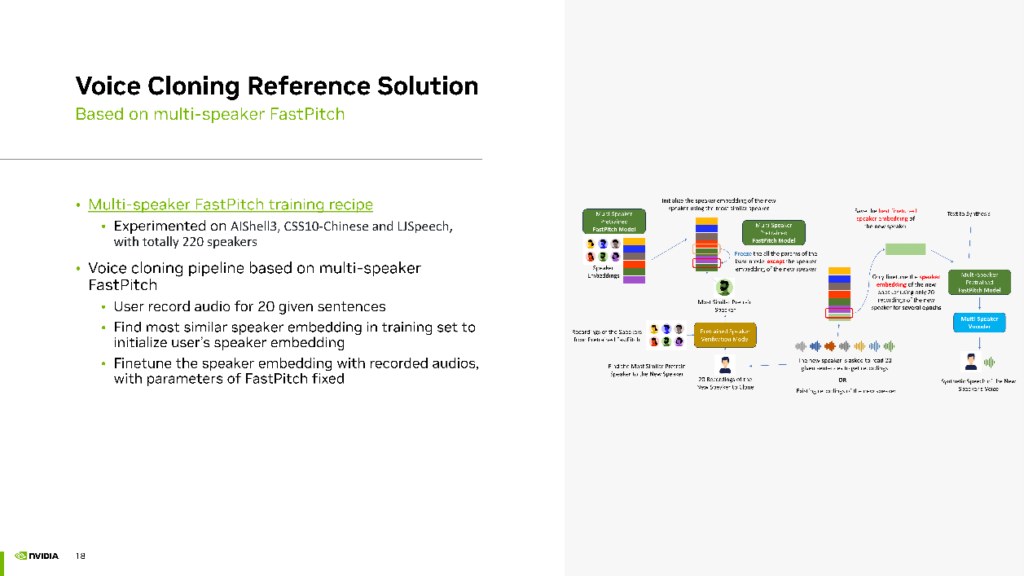
首先,我们开发了一个 Multi-speaker FastPitch 的训练方案,并在开源项目中提供了这个解决方案。在我们的实验中,混合了三个开源数据集(AIShell 3、CSS 10 Chinese、LJSpeech),共计 220 个Speaker,进行了训练。
获得了多说话人的FastPitch模型后,则可进入声音克隆的Finetuning阶段。用户首先录制 20 句话。接着,根据用户的声音在训练集中找到一个与之最相似的Speaker,用其声音的embedding初始化用户的Speaker Embedding。然后,使用用户上传的 20 句话进 finetuning,保持 FastPitch 不变,但 finetuning Speaker的Embedding。最终,该模型使用 Multi-speaker FastPitch 生成与用户声音相似的音频效果。
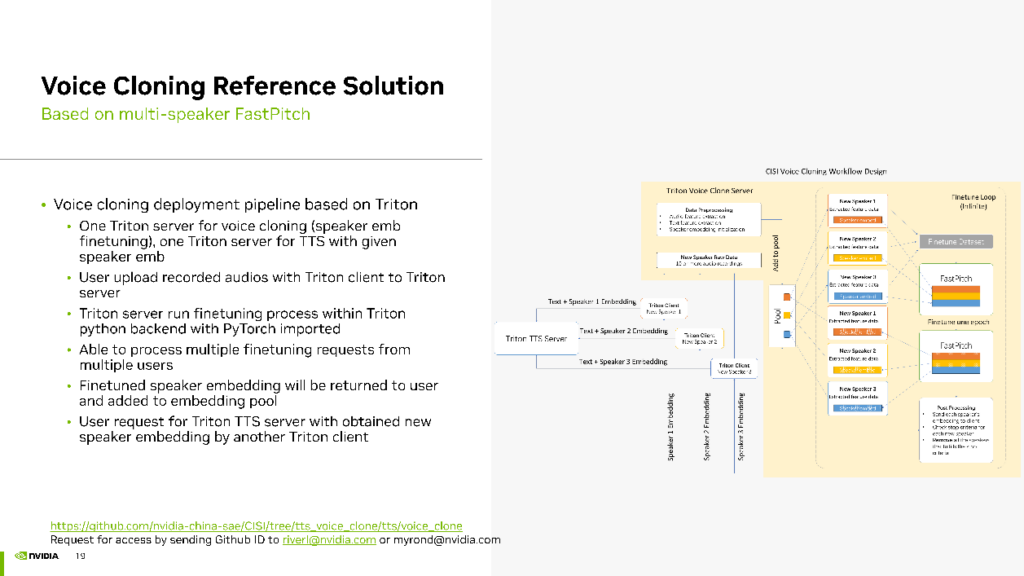
为了实现这一思路的工程化,我们同样采用 Triton Inference Server 进行部署。在此我们配置了两个 Triton Server,一个用于声音克隆,另一个用于 TTS 生成。用户录制的 20 句话可以通过 Triton 的客户端上传到声音克隆 Triton Server。在声音克隆 Triton Server 上,运行声音克隆的 finetuning 过程,使用 Triton 的 Python backend,在其中引用PyTorch包来 实现finetuning 流程。在这个管线中,能够同时处理多个用户的请求,以 batch 的方式进行finetuning提高 GPU 利用率和并发效率。
最后,将每个Speaker的Embedding返回给客户端,并将 finetuning 完成的Speaker Embedding存储在Embedding Pool中。用户想要生成自己的声音只需获取返回的Speaker Embedding,并访问我们的 Triton TTS Server,即我们部署的 Multi-speaker TTS 模型。该模型使用 fine-tuning 完成的Speaker Embedding生成与用户声音相似的音频。这就是我们的声音克隆工作的流程。
▌未来规划

最后分享一下我们对未来工作的规划。
- ASR方面
首先,不断优化Whisper的推理,利用新的一些技术实现加速;使用TensorRT-LLM + Triton作为Whisper部署方案;提供更多的Whisper finetuning方案。
另外,我们正在做的一项工作是code-switched AST训练方案。之前在NeMo中已经实现了基于字符的方法,现在正在尝试基于拼音的东亚语言的方案。
- TTS方面
首先是提供针对其他SOTA模型的加速方案;
第二是提供多语种的TTS方案;
第三是基于LLM的TTS方案。
以上就是本次分享的内容,谢谢大家。