


CUDA Fundamentals

What Is CUDA?
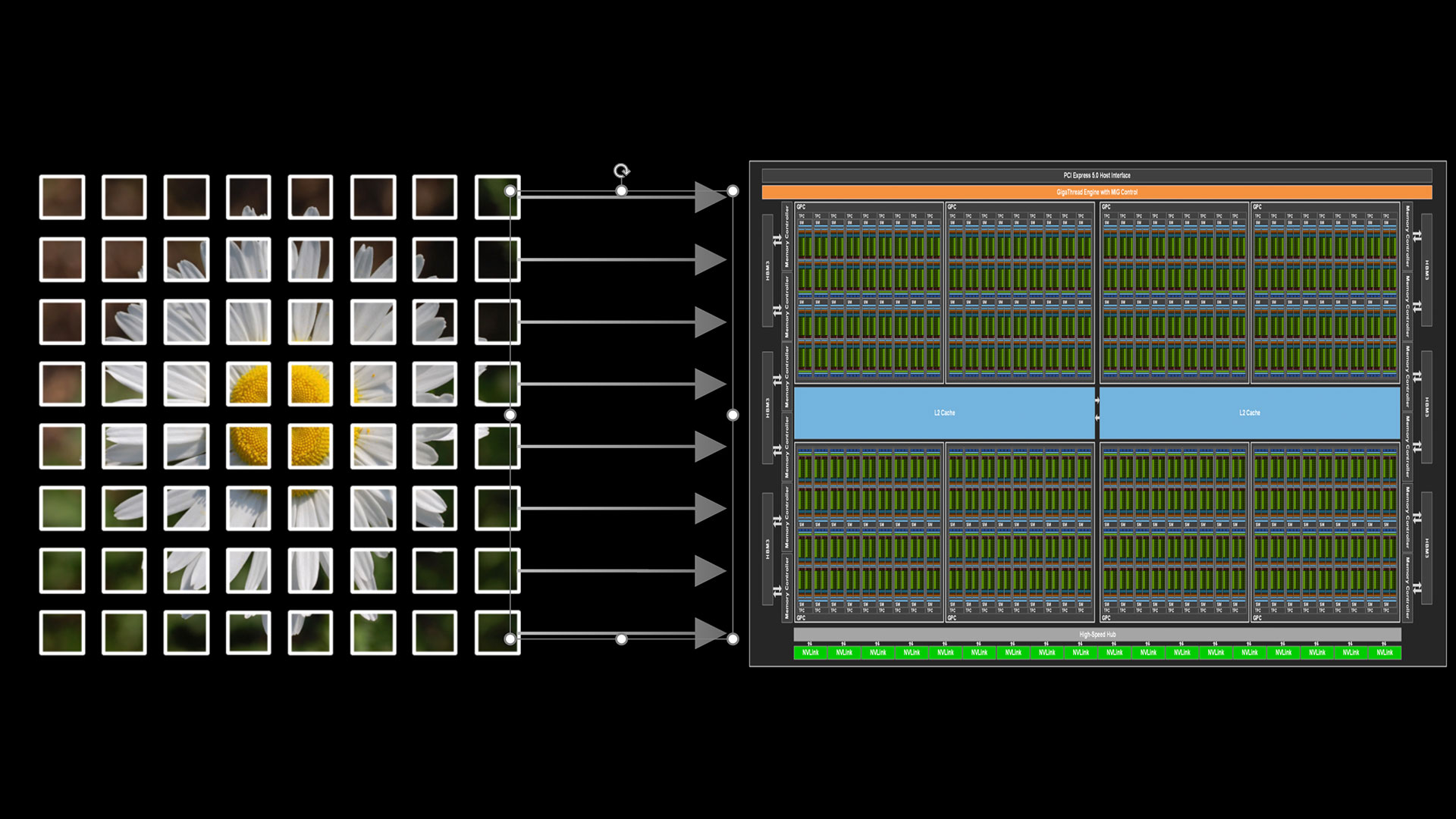
CUDA is NVIDIA's platform for accelerated computing, providing the software layer that enables applications to harness the power of GPUs. Developers can program in languages such as C++, Python, and Fortran or leverage GPU-accelerated libraries and frameworks like PyTorch. This flexibility lets developers integrate GPU computing into any layer of their software stack to achieve optimal functionality and performance.
The CUDA Toolkit, an integral component of the CUDA platform, provides the compiler, libraries, and developer tools required to develop GPU applications.
What’s CUDA All About Anyway?
Learn about the CUDA ecosystem that helps developers solve real-world challenges.
Learn CUDA C++
Learn the fundamentals of CUDA C++ with a collection of guided notebooks.
Learn CUDA Python
Get started with GPU development using Python with a collection of guided notebooks.
How to Write a CUDA Program
Learn about the CUDA ecosystem and how to write CUDA programs.