NVIDIA TensorRT
고성능 딥 러닝 추론을 위한 SDK인 NVIDIA® TensorRT™에는 추론 애플리케이션에 짧은 지연 시간과 높은 처리량을 지원하는 딥 러닝 추론 옵티마이저와 런타임이 포함되어 있습니다.
지금 다운로드 하기 시작하기
NVIDIA TensorRT는 어떤 솔루션인가요?

추론 속도를 36배 향상
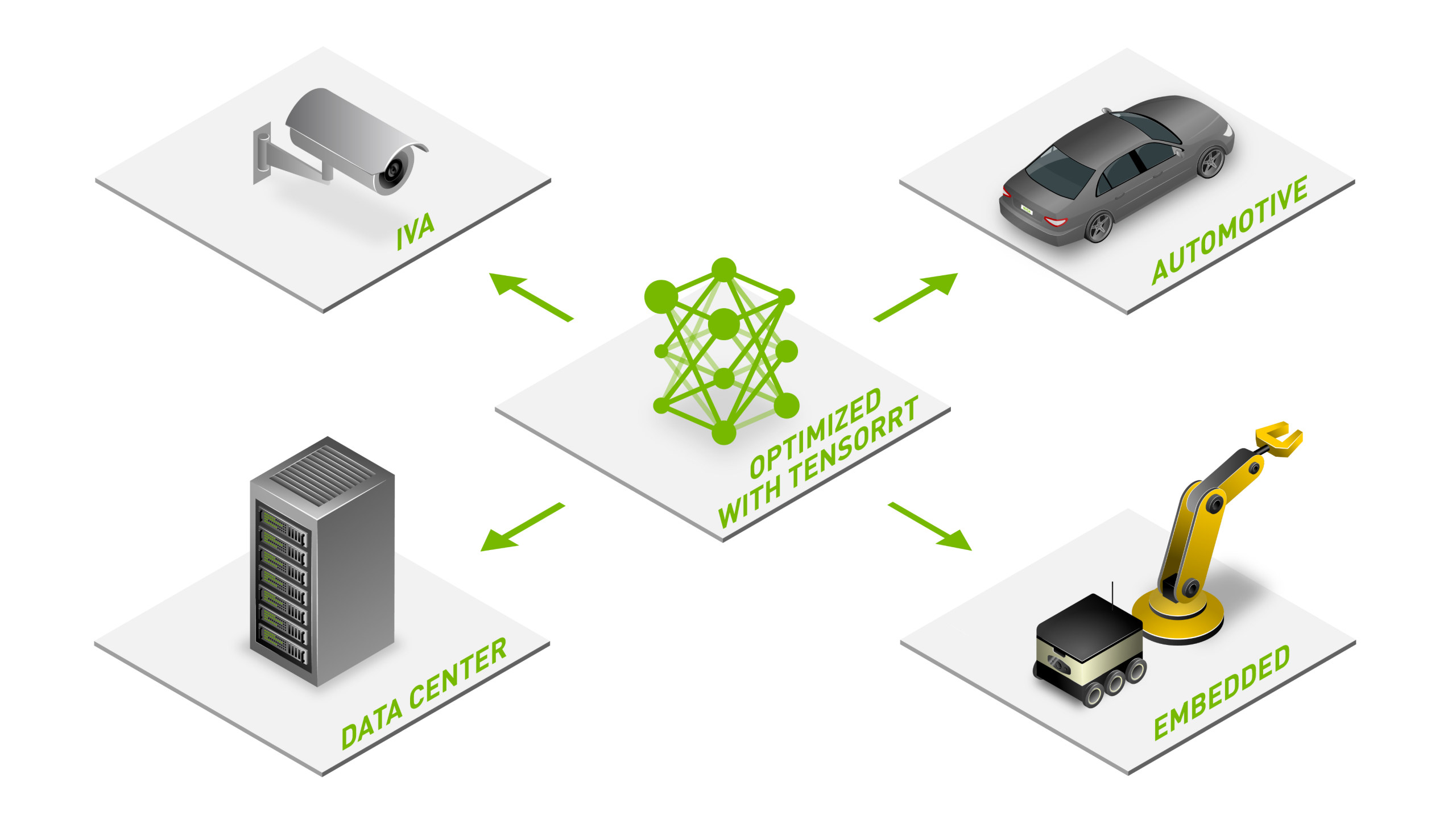
NVIDIA TensorRT 기반 애플리케이션은 CPU 전용 플랫폼보다 추론 속도가 최대 36배 더 빠르기 때문에 모든 주요 프레임워크에서 훈련된 신경망 모델을 최적화하고, 저정밀 추론을 높은 정확도로 보정하며, 하이퍼스케일 데이터 센터, 임베디드 플랫폼 또는 자동차 제품 플랫폼에 추론을 배포할 수 있습니다.

추론 성능 최적화
NVIDIA CUDA® 병렬 프로그래밍 모델을 기반으로 하는 TensorRT를 사용하면 NVIDIA AI, 오토노머스 머신, 고성능 컴퓨팅 및 그래픽에서 라이브러리와 개발 툴 및 기술을 활용해 추론을 최적화할 수 있습니다. 또한 NVIDIA Hopper™ 및 NVIDIA Ampere Architecture GPU에서 희소 Tensor Core를 사용해 성능을 추가로 강화합니다.

모든 워크로드 가속화
TensorRT는 비디오 스트리밍, 추천, 사기 탐지, 자연어 처리 등의 딥 러닝 추론 애플리케이션을 배포할 수 있도록 양자화 인식 훈련과 훈련 후 양자화 및 FP16 최적화를 사용하여 INT8을 제공합니다. 추론의 정밀도가 낮아지면 지연 시간이 크게 줄어드는데, 이는 실시간 서비스와 오토노머스 및 임베디드 애플리케이션에 필요한 요소입니다. .

Triton을 통한 배포, 실행 및 확장
백엔드 중 하나로 TensorRT를 포함하고 있는 오픈 소스 추론 지원 소프트웨어인 NVIDIA Triton™을 사용해 TensorRT에 최적화된 모델을 배포, 실행 및 확장할 수 있습니다. Triton을 사용하면 동적 배칭과 동시 모델 실행을 비롯해 모델 앙상블, 스트리밍 오디오/비디오 입력 등의 기능을 사용하여 처리량을 늘릴 수 있다는 장점이 있습니다.
세계 최고의 추론 성능
MLPerf Inference를 위한 업계 표준 벤치마크에서 NVIDIA가 모든 성능 테스트를 통과한 것은 바로 TensorRT 덕분입니다. 또한 컴퓨터 비전, 자동 음성 인식, 자연어 이해(BERT), 텍스트 음성 변환 및 추천 시스템에서 데이터 센터와 에지 전반에 걸쳐 모든 워크로드를 가속합니다.
대화형 AI
컴퓨터 비전
추천 시스템
모든 주요 프레임워크 지원
TensorRT는 PyTorch 및 TensorFlow에 통합되기 때문에 단 한 줄의 코드만으로 추론 속도를 6배 높일 수 있습니다. 독점 또는 커스텀 프레임워크에서 딥 러닝 훈련을 수행 중인 경우에는 TensorRT C++ API를 사용해 모델을 가져오고 가속할 수 있습니다. TensorRT 문서에서 자세한 내용을 확인하세요.
시작 방법에 대한 정보와 함께 몇 가지 통합 기능이 아래에 나와 있습니다.
모든 추론 플랫폼 가속화
TensorRT는 애플리케이션을 최적화하여 이를 데이터 센터와 임베디드 플랫폼 및 자동차 플랫폼에 배포할 수 있으며, NVIDIA TAO, NVIDIA DRIVE™, NVIDIA Clara™, NVIDIA Jetpack™과 같은 주요 NVIDIA 솔루션을 지원합니다.
또한 NVIDIA DeepStream, NVIDIA Riva, NVIDIA Merlin™, NVIDIA Maxine™, NVIDIA Modulus, NVIDIA Morpheus, Broadcast Engine과 같은 애플리케이션별 SDK에도 통합 되어 개발자가 프로덕션 환경에 지능형 비디오 분석과 음성 AI 배포, 추천 시스템, 화상 회의, AI 기반 사이버 보안 및 스트리밍 앱을 배포하는 데 필요한 통합 경로를 제공합니다.
Triton 커뮤니티에 가입하여 최신 기능 업데이트, 버그 수정 등에 대한 최신 정보를 확인하세요.
성공 사례 읽기


고객사
입문자용 리소스 찾아보기
엔터프라이즈 지원 서비스가 필요하신가요? NVIDIA AI 소프트웨어 제품군에는 TensorRT에 대한 NVIDIA 글로벌 지원 서비스가 제공됩니다.