
NVIDIA cuOpt は、複雑なルーティング問題を解決するための高速最適化エンジンです。休憩時間、待ち時間、車両の複数のコスト/時間マトリックス、複数の目標、注文と車両のマッチング、車両の開始位置と終了位置、車両の開始時間と終了時間など、さまざまな側面が含まれる問題を効率的に解決します。
具体的には、cuOpt は 2 つの問題の複数のバリアントを解決します。CVRPTW (容量制約と時間枠のある配送計画問題) と PDPTW (時間枠のある集荷と配達の問題) です。これらの問題の目的は、それぞれの注文において車両数と走行距離合計を最小限に抑えつつ、顧客の依頼にサービスを提供することです。
cuOpt は、SINTEF が検証した最大規模のルーティング ベンチマークにおいて、過去 3 年間で、23 の世界記録を作りました。
この投稿では、最適化アルゴリズムの主要な要素、その定義、業界をリードするソリューションに対して NVIDIA cuOpt のベンチマークを実行するプロセスについて掘り下げ、その比較の重要性に焦点を当てます。この投稿では、CVRPTW の注文と PDPTW 問題の集荷/配達注文ペアに「リクエスト」という用語を使用します。
この分野にはさまざまな制約の問題の次元がありますが、この投稿の範囲は容量制約と時間枠制約に限定してあります。容量制約とは、車両に積まれる商品の合計は常に、車両容量を超えることができないというものです。時間枠制約は、注文には、時間枠の開始よりも早すぎず、時間枠の終了よりも遅すぎない時間で応じなければならないというものです。
組合せ最適化
組合せ最適化問題は世界で最も計算コストが高い問題であり (NP 困難)、探索空間における考えられる状態の数は階乗になります。大規模な問題に対して正確なアルゴリズムを使用することは不可能であるため、解を最適点に近づけるヒューリスティックが使用されます。ヒューリスティックでは、計算コストが高く、計算的な複雑性が二次以上となるさまざまなアルゴリズムを使用して探索空間を探索します。
非常に複雑であること、そして問題の性質上により、大規模並列 GPU を使用してこれらのアルゴリズムを高速化できます。GPU による高速化のおかげで、最適に近い解が妥当な時間で得られます。
進化的なルート最適化アルゴリズムの構築
典型的なルーティング ソルバーは 2 つの段階で構成されます。初期解の生成と解の改善です。このセクションでは、初期解を生成する手順とそれを改善する手順について説明します。
初期解生成アルゴリズム
フリートに制限があるとき、すべての制約を満たす実行可能な初期解を生成することは、それ自体、NP 困難な問題です。私たちのチームは、ルートにリクエストを送信するための GES (Guided Ejection Search/ガイド付き追い出し検索) アルゴリズムを改善し、並列化しました。
GES の中心にある着想はシンプルです。まず、ルートにリクエストを挿入しようとします。そのリクエストを挿入できない場合、1 つまたは複数の「挿入が楽な」リクエストをルートから追い出し、挿入難易度が緩和されたルートにリクエストを挿入します。各リクエストのペナルティ スコア (p スコア) は、そのリクエストをルートに挿入する難しさを示します。このアルゴリズムでは、追い出されたリクエストの p スコアの合計が挿入検討中のリクエストより小さい場合にのみ、リクエストが挿入されます。
追い出しをもってしても、ルートにリクエストを挿入できなければ、その都度、そのリクエストの p スコアを増やし、もう一度試します。未処理のリクエストはすべて追い出しプールに保存され、その追い出しプールが空になるまでこのアルゴリズムが実行されます。つまり、すべてのリクエストが処理されるまで実行されます。
このアルゴリズムの主な欠点は、循環 (解における前のノード セットに戻ること) であり、追い出されるノード数が多いときに、追い出しの組み合わせを見つけるスピードが遅いことであり、そして弱く、ランダムにずれる解のみが考慮されることです。NVIDIA はこうした欠点を取り除き、現在の最先端の手法よりもルート数がはるかに少ない解を生成できるようになりました。
この追い出しアルゴリズムについて詳しく知る前に、タイム ワープ法を利用して実行可能性チェックと解の評価が常に実行されることを理解しておくことが重要です。この手法では計算時間が大幅に減りますが、任意の数の追い出しを探索するとき、その探索で辞書式の順序に従う必要があるため、並列化が難しくなるという面もあります。
追い出すリクエストと、挿入検討中のリクエストを挿入できる場所を見つけることは、計算コストが高くつく問題です。追い出されるリクエストの数に関連して急激に難しくなり、すべてのルートですべての挿入位置をチェックする必要があります。NVIDIA の実験では、少数の追い出しがアルゴリズムの循環を引き起こしていることを示しています。
そのため、大規模な探索を並列で実行するときは、追い出すリクエストを多くても 10 件 (ヒューリスティック) と 5 件にできる手法を NVIDIA は提案します。各ルートからフラグメントを追い出し、これらの一時的なルートをスレッド ブロックで処理することでこの追い出しアルゴリズムを並列化します。次に、挿入検討中のリクエストを、あらゆる挿入可能な位置に並列で挿入することを試みます。
ディープ サーチ アルゴリズムでは、あるルートで、すべてのリクエストの考えられるあらゆる追い出し組み合わせ (順列) が試されます。私たちはリクエストの挿入位置ごとに異なるスレッド ブロックを使用し、辞書式の順序を非依存のサブ順列に分割することで辞書式探索を並列実行します。
GES アルゴリズムは、制限時間がなくなるか、リクエスト プールが空になるまでループします。私たちは、実行可能な挿入が見つかるよう、反復のたびに解をずらして解の状態を改善し、解にすき間を作ります。この「ずらし (Perturbation)」はランダム ローカル探索であり、ルート間ならびにルート内でノードの位置を変えたり、交換したりします。
リクエストを満たす最適な車両数が判明したら、目標を最小化する改善フェーズに移行します。デフォルトでは、これは合計走行距離になりますが、cuOpt で他の目標を構成できます。

進化的プロセスとローカル探索アルゴリズム
改善フェーズは複数の解に作用し、進化的戦略を使用して解を改善します。生成された解は母集団に配置されます。NVIDIA は、十分に多様な初期解に到達するために、生成プロセスでランダム化を使用します。GPU アーキテクチャを利用することで、さまざまな解を並行して生成します。多様な母集団が進化的改善プロセスを通過し、解の最良の特性が新しい世代に残されます。
進化プロセスの 1 ステップで、2 つの解をランダムに選択し、交差演算子を適用します。これにより、両方の親から良い特性を継承する子孫解が生成されます。さまざまな交差演算子を解に適用できますが、一部の交差演算子は子孫を不完全な状態のままにします。解は、重複するノードを追い出し、ルーティングされていないノードを挿入することで修正します。あるいは、実行できない部分を解でローカル探索することで修復し、解を修正します。
たとえば、順序ベースの交差演算子は、ある親解の 1 つまたは複数のルートのノードを、それらが別の親解に現れる順序との関連で並べ替えます。結果的に生成される子孫は、一方の親解のグループ化特性を保持し、もう一方の親解の順序付け特性を保持します。この特定の演算子の結果は、時間制約と容量制約に関連しておそらく実行不可能となる完全な解です。cuOpt には、解でランダムに実行される複数の交差演算子が含まれます。
交差後のローカル探索フェーズは、実行不可能性を減らすか排除し、トータルの目標 (この場合は移動距離) を改善するうえで重要な役割を果たします。ローカル探索の目標の加重値は、最適化には何が重要であるかによって決まります。実行不可能性の加重値を上げれば上げるほど、解は実行可能なところまで戻り、これは通常、大抵の問題に当てはまります。
ローカル探索では、子孫解のローカル最小を見つけます。これは後続の進化ステップに参加します。ローカル探索は高速であることが重要です。与えられた時間内で改善を何回繰り返せるかは主にこの速度で決まります。高速で近似値を見出す大規模な近傍探索アルゴリズムを利用し、パフォーマンスを維持しつつ、良好なローカル最小を見つけます。従来の手法のように固定サイズの近傍ローカル探索を実行する代わりに、簡単な改善を速やかにキャッチする「ネット」と、探索が停滞したときの深度の高い演算子 (Very Deep Operators) を NVIDIA は設計しました。
高速演算子は小さな近傍をすばやく探索し、近似演算子は適用されるたびに異なる動きを評価できます。これは、交差では一部のルートに手が付けられないことが頻繁にあるため、特に重要です。「A GPU Parallel Algorithm for Finding a Negative Subset Disjoint Cycle in a Graph (グラフの中から負の素小集合サイクルを見つけるための GPU 並列アルゴリズム)」で説明されているように、大規模な近傍演算子では、ルート間の移動サイクルとして表現されるひと続きの動きの中でリクエストが動きます。
巡回演算子は、単純な演算子では探索できない非常に大きな周辺を探索します。これは単に、単純な演算子では制約により探索空間の一部の丘を通過できないためです。このワークフローでは、高速演算子の使用頻度を増やし、計算コストの高いディープ演算子の使用頻度を減らすことができます。
GPU 並列化は、各仮説ルートをスレッド ブロックにマッピングすることで行われます。これにより、共有メモリを利用してルート関連データを格納できます。ルート関連データは、移動を探索するときの一時的なデータです。一時的なルートは、元のルートのコピー化、1 つまたは複数のリクエストが追い出されたバージョンになります。スレッド ブロック内のスレッドでは、他のルートから考えられるあらゆるリクエストを、この一時的なルートのすべての位置に挿入しようとします。
すべての移動を見つけて記録したら、それぞれの挿入/追い出しコスト デルタを合計することでルート ペアごとに最適な移動を見つけます。このコスト デルタ (コスト変化量) は、実行できない場合のペナルティ加重値も含む、目標の加重値によって計算されます。移動によって変更されるルートでは、このような移動が互いに排他的になる場合、複数の移動を実行します。

cuOpt のベンチマーク
NVIDIA は cuOpt のパフォーマンスと品質を継続的に改善しています。品質を計測するため、CVRPTW のための Gehring & Homberger や PDPTW のための Li & Lim など、最も研究されているベンチマークで最も知られている解に対してソルバーをテストしています。実際には、望ましい解にソルバーがどのくらい速く到達できるかが会社にとって重要です。
評価の基準と目標
- 精度は、目標に基づき、見つかった解と BKS (Best Known Solutions: 最も知られている解) の間の隔たり (%) として定義されています。この問題の仕様では、最初の目標が車両数、2 番目の目標が走行距離となっています。
- 解決までの時間は、特定の隔たりが BKS または望ましい目標解に達するために必要な時間を指します。解決までの時間は、実際のユース ケースにとって最も重要な基準の 1 つです。与えられた時間内で精度の高い解に到達することが重要です。組み合わせ最適化アルゴリズムにはかなりの時間がかかります。
図 3 と 4 は、ベンチマークの大きなインスタンスからなるサブセットでのソルバーの収束動作を示しています。

(クラスター、ランダム) および (ロング ルート、ショート ルート) インスタンスに基づいてソルバーの全体動作を示すため、各カテゴリ (C1_10_1、C2_10_1、R1_10_1、R2_10_1、RC1_10_1、RC2_10_1) からインスタンスを 1 つ選択しています。1 分おきにサンプリングされる総計が BKS 総計と比較されます。
初めの急な収束は、時間の経過と共に、BKS 総計にゆっくりと近づきます。これらのインスタンス セットでは、BKS の車両総数を一致させることができました。cuOpt ソルバーは、Gehring&Homberger インスタンスのほぼすべてのインスタンスで BKS 車両数を検出できます。ただし、実際のパフォーマンスは、改善フェーズと比較して、最初の解生成に費やした時間に依存します。
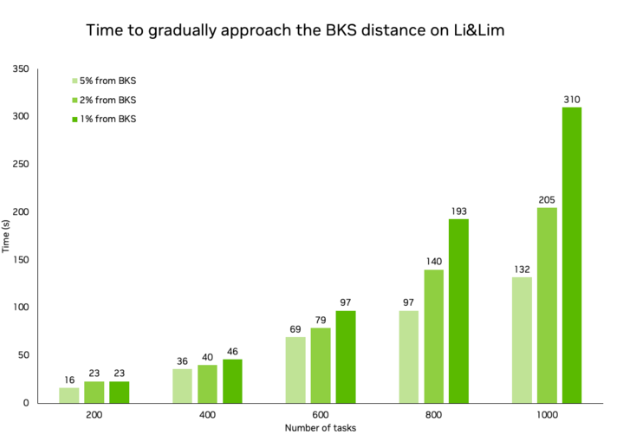
このソルバーは大きなインスタンスではすぐに収束しますが、小さなインスタンスでは桁違いに速く収束します。次の表に、さまざまな問題サイズで BKS に到達するまでにかかる時間と BKS と同じ車両数を達成する時間を示します。
cuOpt が 23 の世界記録を樹立
GPU で高速化するヒューリスティックスと最新の進化戦略からなる新しい手法により、cuOpt は Gehring & Homberger ベンチマークの 15 インスタンスと Li & Lim ベンチマークの 8 インスタンスで記録を打ち立てました。
NVIDIA は現在、過去 3 年間の CVRPTW および PDPTW カテゴリのすべての記録を保持しています。
図 5 では、各エッジのあるタスクから別のタスクへのパスを表しています。緑の線は前のレコードと共通のエッジを表しています。2 つの解の間では青エッジと赤エッジは異なります。進化的戦略のおかげで、cuOpt の解は、考えられる解の探索空間において、まったく別の場所にあります。つまり、たくさんの異なるエッジが存在します。

Gehring & Homberger の場合、BKS との全体的隔たりの平均は、距離の隔たりが -0.07% で、車両数の隔たりが 0.29% です。Li & Lim の場合、BKS との全体的隔たりの平均は、距離の隔たりが 1.22% で、車両数の隔たりが 0.36% です。ベンチマークは 1 個の NVIDIA H100 GPU で 200 分間実行されました。
まとめ
NVIDIA cuOpt は、GPU アクセラレーションと RAPIDS などの NVIDIA テクノロジにより、高品質の解を秒単位で達成します。CPU ベースの実装と比較して、ローカル探索操作で 100 倍の高速化を達成しました。CPU ベースのソルバーでは、同様の解に到達するまでに数時間を要します。
NVIDIA cuOpt の詳細と利用についてはこちらをご覧ください。NVIDIA API カタログと NVIDIA LaunchPad からモデルを試すこともできます。また、cuOpt が、どのように組織の時間と費用の節約に役立つかもご覧ください。 NVIDIA の最適化 AI エンジニアリング マネージャーである Alex Fender が講演した、NVIDIA GTC 2024 セッション「Advances in Optimization AI (最適化 AI の進化)」をご視聴ください。NVIDIA Deep Learning Institute トレーニング「Learn How to Use Our Route Optimization Microservice to Drive Efficiency and Cost Savings (効率化とコスト削減を実現するルート最適化マイクロサービスのご紹介)」の受講もおすすめします。
関連情報
- GTC セッション: Learn How to use a Route Optimization Cloud Service to Drive Efficiency and Cost Savings (効率化とコスト削減を実現するルート最適化クラウド サービスのご紹介)
- GTC セッション: Advances in Optimization AI (最適化 AI の進化)
- GTC セッション: Demystify CUDA Debugging and Performance with Powerful Developer Tools(強力な開発者ツールで CUDA のデバッグとパフォーマンスを解明する)
- NGC コンテナー: cuOpt
- SDK: cuOpt
- ウェビナー: Use Your Own CUDA ROS Node with NITROS on NVIDIA Jetson (NVIDIA Jetson 上の NITROS で独自の CUDA ROS ノードを使う)