
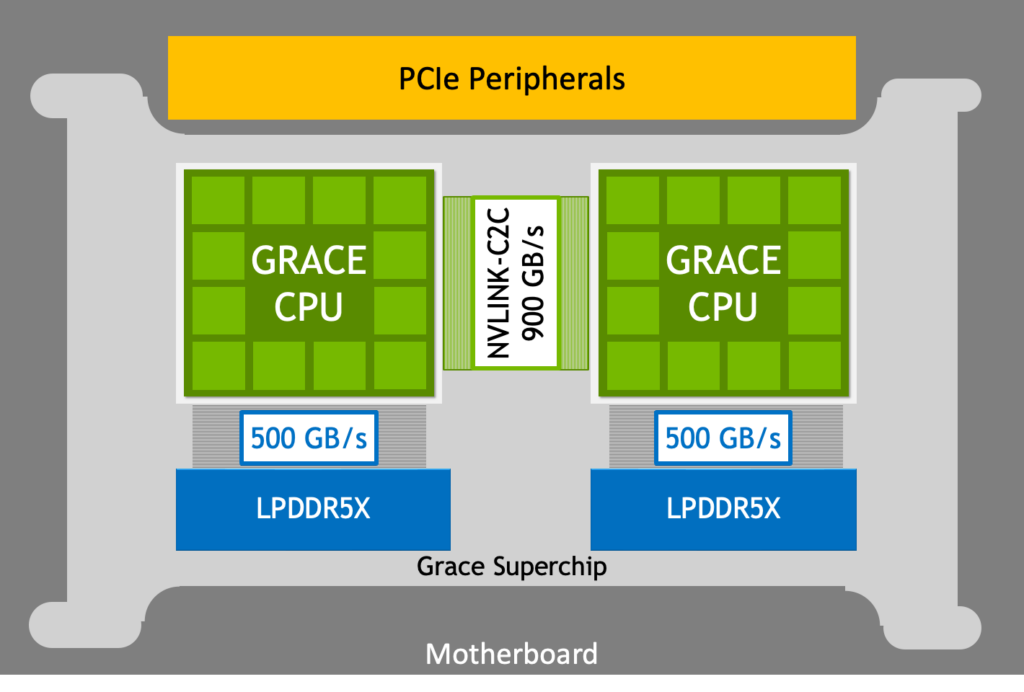
NVIDIA Grace CPU は、NVIDIA が開発した初のデータ センター向け CPU です。NVIDIA Grace CPU は、NVIDIA の専門知識と Arm プロセッサ、オンチップ ファブリック、システムオンチップ (SoC) 設計、および耐障害性の高い高帯域幅低電力メモリ技術を組み合わせることで、世界初のコンピューター用スーパーチップを生み出すために一から構築されました。スーパーチップの心臓部には、NVLink Chip-2-Chip (C2C) があり、NVIDIA Grace CPU は、スーパーチップ内の別の NVIDIA Grace CPU または NVIDIA Hopper GPU と 900 GB/s の双方向帯域幅で通信することができます。
NVIDIA Grace Hopper Superchip は、電力効率に優れた高帯域幅の NVIDIA Grace CPU と、強力な NVIDIA H100 Hopper GPU を、NVLink-C2C を使用して組み合わせ、Strong Scaling のハイ パフォーマンス コンピューティング (HPC) や巨大な AI ワークロードに対する機能を最大限に引き出します。詳細については、NVIDIA Grace Hopper Superchip Whitepaper をご覧ください。
NVIDIA Grace CPU Superchip は、NVLink-C2C を使用して接続された 2 つの Grace CPU を使って構築されています。このスーパーチップは、既存の Arm エコシステムに基づき、HPC、要求の厳しいクラウド ワークロード、高性能で電力効率に優れた高密度のインフラストラクチャを実現するための、妥協のない初の Arm CPU を構築しています。
この記事では、NVIDIA Grace CPU Superchip と、NVIDIA Grace CPU の性能と電力効率を実現する技術について解説します。詳細については、NVIDIA Grace CPU Superchip Architecture Whitepaper を参照してください。
HPC や AI のワークロードのために開発されたスーパーチップ
NVIDIA Grace CPU Superchip は、2 ソケット x86-64 サーバーやワークステーションのフラッグシップ プラットフォームが提供する性能レベルを単一のスーパーチップに統合することにより、コンピューティング プラットフォーム設計における革命を体現しています。効率的な設計により、より低い消費電力で 2 倍の計算密度を実現します。
| NVIDIA Grace CPU Superchip アーキテクチャの特徴 | |
| コア アーキテクチャ | Neoverse V2 コア: 4x128b SVE2 搭載 Armv9 |
| コア数 | 144 |
| キャッシュ | L1: コアあたり 64 KB I-cache + 64 KB D-cache L2: コアあたり 1 MB L3: スーパーチップあたり 234 MB |
| メモリ技術 | ECC 搭載 LPDDR5X、Co-Packaged |
| メモリ帯域幅 | 最大 1 TB/s |
| メモリ サイズ | 最大 960 GB |
| FP64 ピーク | 7.1 TFLOPS |
| PCI express | PCIe Gen 5 x16 インターフェイス x 8。 オプションで分岐可能、合計 1T B/s の PCIe 帯域幅。 管理用低速 PCIe 接続を追加。 |
| 電力 | 500 W TDP (メモリ使用時) 、電源電圧 12 V |
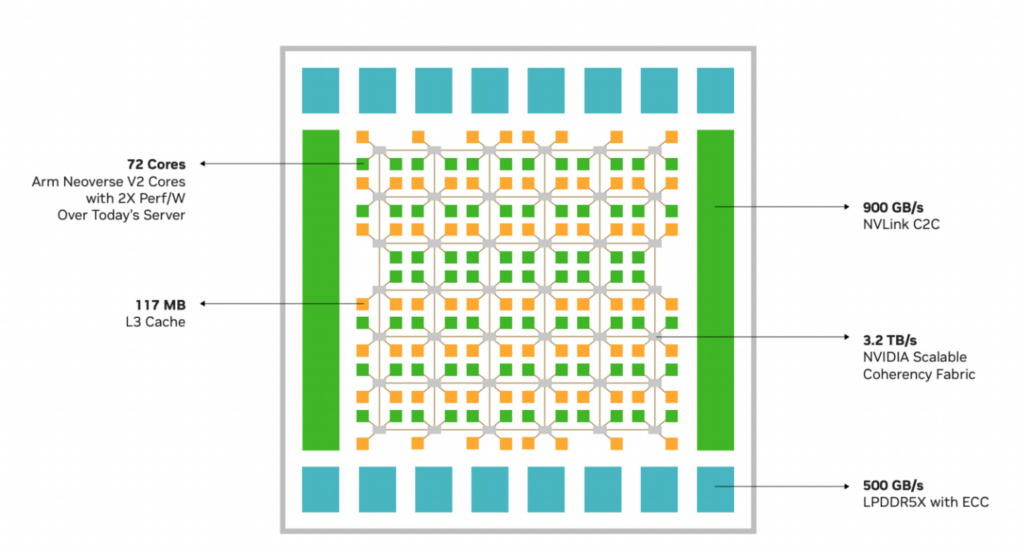
NVIDIA Grace CPU は、高いシングルスレッド性能、高いメモリ帯域幅、優れたデータ移動能力を、ワットあたりで最高の性能を発揮するように設計されました。NVIDIA Grace CPU Superchip は、900 GB/s の双方向帯域幅 NVLink-C2C で接続された 2 つの NVIDIA Grace CPU を組み合わせ、144 個の高性能 Arm Neoverse V2 コアと、エラー訂正コード (ECC: Error Correction Code) メモリを備えたデータ センター クラスの LPDDR5X メモリが持つ最大 1 TB/s 帯域幅を提供します。
NVLink-C2C インターコネクトによるボトルネックの軽減
Arm Neoverse V2 コアを 144 個まで拡張し、両方の CPU 間でデータを移動するために、NVIDIA Grace CPU Superchip は CPU 間の高帯域幅接続を必要としていました。そこで NVLink C2C インターコネクトが、2 つの NVIDIA Grace CPU 間に高帯域幅の直接相互接続を提供し、NVIDIA Grace CPU Superchip を作ります。
NVIDIA Scalable Coherency Fabric でコアと帯域幅を拡張
最近の CPU ワークロードは、高速なデータ移動を必要とします。NVIDIA が設計した Scalable Coherency Fabric (SCF) は、コア数と帯域幅を拡張できるように設計されたメッシュ ファブリックと分散キャッシュ アーキテクチャです (図 3) 。SCF は、CPU コア、NVLink-C2C、メモリ、およびシステム IO 間でデータを流し続けるために、合計 3.2 TB/s 以上のバイセクション帯域幅を提供します。
CPU コアと SCF キャッシュ パーティションはメッシュ全体に分散され、キャッシュ スイッチ ノードはファブリックを介してデータを転送し、CPU、キャッシュ メモリ、システム IO 間のインターフェイスとして機能します。NVIDIA Grace CPU Superchip は、2 つのチップにまたがる 234 MB の分散 L3 キャッシュを備えています。
LPDDR5X
電力効率とメモリ帯域幅は、どちらもデータ センター用 CPU の重要な要素です。NVIDIA Grace CPU Superchip は、最大 960 GB の ECC 付きサーバークラスの低消費電力 DDR5X (LPDDR5X) メモリを使用しています。この設計は、大規模な AI および HPC ワークロードのための帯域幅、エネルギー効率、容量、およびコストの最適なバランスを打ち出します。
8 チャンネル DDR5 設計と比較して、NVIDIA Grace CPU LPDDR5X メモリ サブシステムは、同等のコストで、ギガバイトあたり 8 分の 1 の消費電力で最大 53% の帯域幅を提供します。HBM2e メモリ サブシステムは、かなりのメモリ帯域幅と優れたエネルギー効率を提供しますが、ギガバイトあたりのコストは 3 倍以上、利用できる最大容量は LPDDR5X の 8 分の 1 だけです。
LPDDR5X の低消費電力は、システム全体の電力要件を軽減し、より多くのリソースを CPU コアに投入することができます。コンパクトなフォーム ファクターにより、一般的な DIMM ベースの設計の 2 倍の密度を可能にします。
NVIDIA Grace CPU I/O
NVIDIA Grace CPU Superchip は、IO 接続のために最大 128 レーンの PCIe Gen 5 をサポートします。8 つの PCIe Gen 5 x16 リンクはそれぞれ最大 128 GB/s の双方向帯域幅をサポートし、さらに接続性を高めるために 2 つの x8 に分岐することができます。また、NVIDIA GPU、NVIDIA DPU、NVIDIA ConnectX SmartNIC、E1.S および M.2 NVMe デバイス、モジュール型 BMC オプションなどをすぐにサポートし、さまざまな PCIe スロット フォーム ファクターをサポートできます。
NVIDIA Grace CPU コア アーキテクチャ
ワークロードを最大限に高速化するために、高速で効率的な CPU はシステム設計にとって重要な要素です。Grace CPU の心臓部には、Arm Neoverse V2 CPU コアが搭載されています。Neoverse V2 は、Arm V シリーズの最新のインフラストラクチャ CPU コアで、従来の CPU と比較して、優れたエネルギー効率を提供しながら、優れたスレッドあたりの性能を提供するように最適化されています。

Arm アーキテクチャ
NVIDIA Grace CPU Neoverse V2 コアは、Armv8-A アーキテクチャで定義され Armv8.5-A まで拡張された Armv9-A アーキテクチャを実装しています。Armv8 から Armv8.5-A までのアーキテクチャ向けに構築されたアプリケーション バイナリは、NVIDIA Grace CPU 上で実行できます。これには、Ampere Altra、AWS Graviton2、AWS Graviton3 などの CPU をターゲットにしたバイナリが含まれます。
SIMD 命令
Neoverse V2 は、Scalable Vector Extension version 2 (SVE2) と Advanced SIMD (NEON) という 2 つのSingle Instruction Multiple Data (SIMD) ベクトル命令セットを 4 × 128 ビット構成で実装しています。4 つの 128 ビット機能ユニットは、それぞれ SVE2 命令と NEON 命令のいずれかをリタイアすることができます。この設計により、より多くのコードで SIMD 性能をフルに活用できるようになりました。SVE2 は、機械学習、ゲノミクス、暗号化などの主要な HPC アプリケーションを高速化することができる高度な命令により、SVE ISA をさらに拡張します。
アトミック演算
NVIDIA Grace CPU は、Armv8.1 で初めて導入された Large System Extension (LSE) をサポートしています。LSE は低コストのアトミック演算を提供し、CPU 間通信、ロック、ミューテックスなどのシステム スループットを向上させることができます。これらの命令は、整数データに対して操作することができます。NVIDIA Grace CPU をサポートするすべてのコンパイラは、GNU Compiler Collection の __atomic ビルトインや std::atomic などの同期関数でこれらの命令を自動的に使用するようになります。Load-Exclusive と Store-Exclusive の代わりに LSE アトミックを使用した場合、最大で 1 桁の改善が期待できます。
Armv9 の追加機能
NVIDIA Grace CPU は、暗号化の高速化、柔軟性に優れたプロファイリングの拡張、仮想化の拡張、フルメモリの暗号化、セキュア ブートなど、汎用データ センター CPU に有用性をもたらす Armv9 ポートフォリオの複数の主要機能を実装しています。
NVIDIA Grace CPU ソフトウェア
NVIDIA Grace CPU Superchip は、ソフトウェア開発者に標準準拠のプラットフォームを提供するために構築されています。
NVIDIA Grace CPU は、Arm Server Base System Architecture (SBSA) に準拠しており、標準準拠のハードウェアおよびソフトウェア インターフェイスを実現します。さらに、Grace CPU ベースのシステムで標準的なブート フローを可能にするため、Grace CPU では Arm Server Base Boot Requirements (SBBR) に対応するように設計されています。すべての主要な Linux ディストリビューションと、それらが提供する膨大なソフトウェア パッケージのコレクションは、NVIDIA Grace CPU 上で変更することなく完璧に動作します。
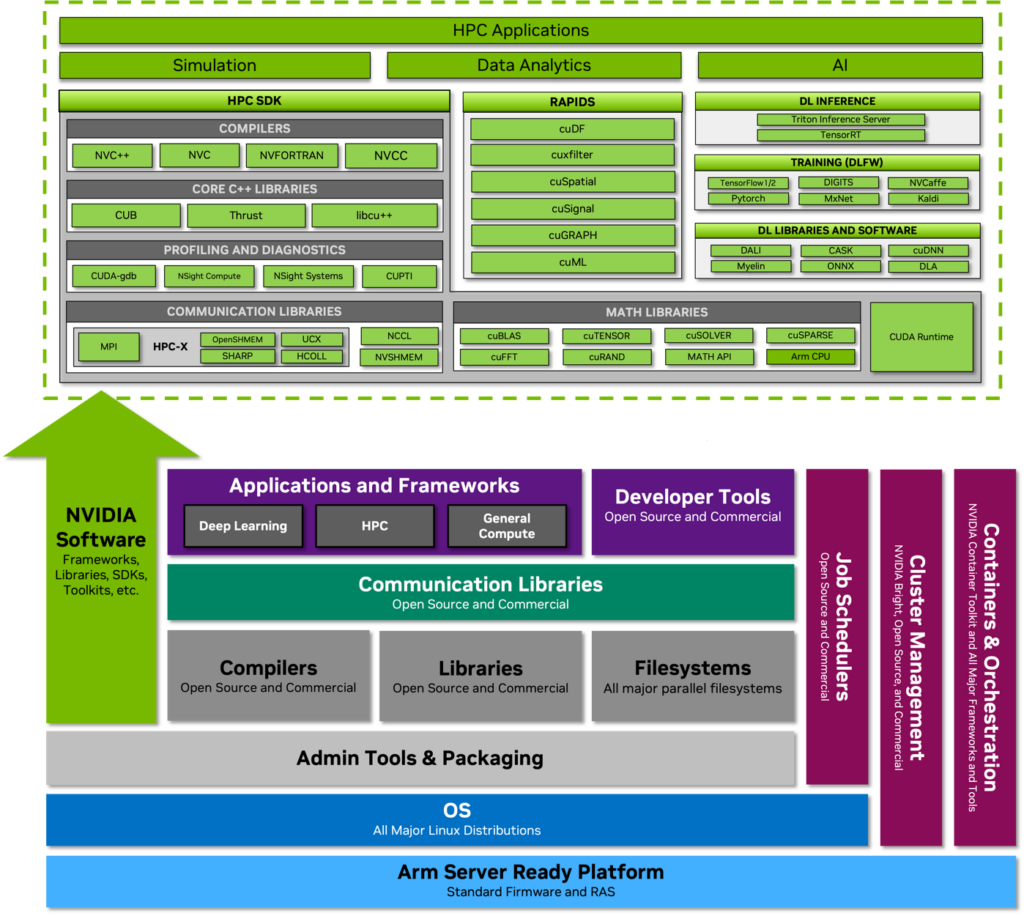
コンパイラ、ライブラリ、ツール、プロファイラー、システム管理ユーティリティ、およびコンテナー化と仮想化のためのフレームワークは現在入手可能であり、他のデータ センター CPU と全く同様に NVIDIA Grace CPU にインストールして使用することができます。さらに、NVIDIA Grace CPU では、NVIDIA ソフトウェア スタック全体が利用できます。NVIDIA HPC SDK とすべての CUDA コンポーネントには、Arm ネイティブのインストーラーとコンテナーがあります。NVIDIA GPU Cloud (NGC) は、Arm 用に最適化されたディープラーニング、機械学習、HPC コンテナーも提供しています。NVIDIA Grace CPU は、主流 CPU の設計原理に従い、他のサーバー CPU と同様にプログラムされています。
性能の効率化を提供
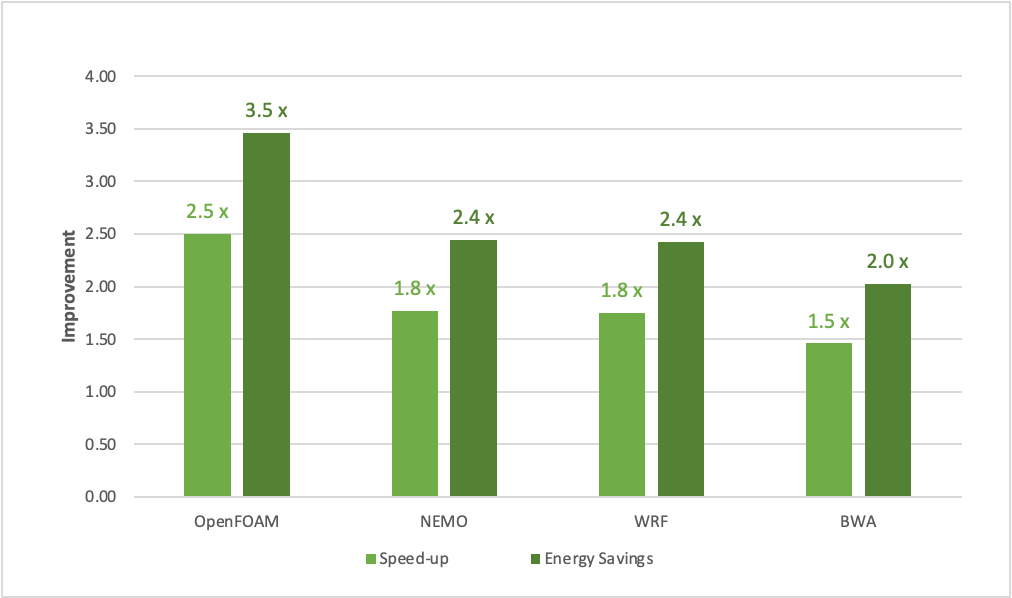
NVIDIA Grace Superchip Architecture Whitepaper では、この投稿で取り上げた内容をさらに詳しく説明しています。このホワイトペーパーでは、図 1 に示すような優れた性能を NVIDIA Grace CPU がどのように実現しているのか、また、その性能の背景にある技術革新についても詳しく説明しています。
謝辞
Thomas Bradley、Jonah Alben、Brian Kelleher、Nick Stam、Jasjit Singh、Anurag Chaudhary、Giridhar Chukkapalli、Soumya Shyamasundar、Ian Karlin、Suryakant Patidar、Alejandro Chacon、Matthew Nicely、Steve Scalpone、Polychronis Xekalakis、その他この投稿に協力してくれた多くの NVIDIA アーキテクチャおよびエンジニアの皆さんに感謝します。
翻訳に関する免責事項
この記事は、「NVIDIA Grace CPU Superchip Architecture In Depth」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。