
本番環境で大規模言語モデル (LLM) をデプロイする際に、ユーザーのインタラクティブ性の強化と、システムのスループット向上との間で難しいトレードオフを迫られることがよくあります。ユーザーのインタラクティブ性を強化するには、最初のトークンが出力されるまでの時間 (TTFT: Time To First Token) を最小限に抑える必要がありますが、スループットを向上するには、1 秒あたりのトークン数を増やす必要があります。一方の側面を改善すると、もう一方の側面が悪化することが多いため、データ センター、クラウド サービス プロバイダー (CSP)、AI アプリケーション プロバイダーにとって、適切なバランスを見つけることが困難になっています。
NVIDIA GH200 Grace Hopper Superchip を活用すると、こうしたトレードオフを最小限に抑えることができます。この投稿では、IT リーダーやインフラの意思決定者の方が、NVIDIA GH200 Grace Hopper Superchip のコンバージド メモリ アーキテクチャを活用して、システム スループットを犠牲にすることなく、x86 ベースの NVIDIA H100 サーバーと比較して、人気の高い Llama 3 70B モデルでマルチターンでユーザーとのやり取りする場合、TTFT を最大 2 倍に向上させる方法について解説します。
Key-value キャッシュのオフロード
LLM モデルは、質問応答、要約、コード生成など、さまざまな用途で急速に採用が進んでいます。ユーザーの要求に応答する前に、これらのモデルは、検索拡張生成 (RAG) の場合のように、推論要求中に取得した入力シーケンスと追加情報の文脈を理解する必要があります。
このプロセスでは、ユーザーの要求をトークンに変換し、次に高密度のベクトルに変換し、その後、広範なドット積演算を行い、プロンプト内のすべてのトークン間の関係を数学的に表現します。この演算は、モデルの異なるレイヤーで繰り返し実行されます。プロンプトの文脈理解を生成するために必要な計算量は、入力シーケンス長さに比例して二乗のオーダーで増加します。
この計算負荷の高いプロセスでは、Key-value キャッシュ (KV キャッシュ) が生成されますが、このプロセスは出力シーケンスの最初のトークンの生成時にのみ必要となります。これらの値は、後続の出力トークンが生成される際に再利用できるよう保存され、必要に応じて新しい値が追加されます。これにより、新しいトークンの生成に必要な計算量を大幅に削減でき、最終的には、LLM が出力を生成するのにかかる時間を大幅に短縮し、ユーザー体験を向上することができます。
KV キャッシュを再利用すると、ゼロから再計算する必要がなく、推論時間と計算リソースを削減することができます。ただし、LLM ベースのサービスとユーザーとのやり取りが断続的である場合、または複数の LLM ユーザーが同じ KV キャッシュと異なるタイミングでやり取りする必要がある場合、KV キャッシュを長期間 GPU メモリに保存することになり、新しいユーザー リクエストの処理に割り当てられる貴重なリソースが無駄になり、システム全体のスループットが低下することがあります。
KV キャッシュを GPU メモリから、より大容量で低コストの CPU メモリにオフロードし、アイドル状態のユーザーが活動を再開したり、新しいユーザーが同じコンテンツとやり取りしたりするタイミングでGPU メモリに再ロードすることがで、この課題に対処する事ができます。KV キャッシュ オフロードと呼ばれるこの方法では、貴重な GPU メモリを占有することなく、KV キャッシュを再計算する必要がなくなります。
マルチターンでユーザーとのやり取りする際に生じる課題に対処
KV キャッシュ オフロードは、新しいユーザーごとに KV キャッシュを再計算することなく、複数のユーザーが同じコンテンツ (ニュース記事の要約など) に対して相互に情報共有することで、生成 AI 機能をプラットフォームに統合するコンテンツ プロバイダーにメリットをもたらします。ニュース記事の KV キャッシュを 1 回計算し、CPU メモリにキャッシュし、複数のユーザーに再利用することで、コストとユーザー体験の大幅な最適化を実現できます。
この技術は、コード生成のユース ケース、特に LLM 機能を組み込んだ統合開発環境 (IDE) でも役立ちます。このシナリオでは、1 人または複数の開発者が、1 つのコード スクリプトと長時間にわたってやり取りする複数のプロンプトを送信できます。最初の KV キャッシュ計算を CPU メモリにオフロードし、その後のやり取りのために再ロードすることで、再計算を繰り返すことなく、貴重な GPU とインフラ リソースを節約することができます。KV キャッシュのオフロードと再利用に関する詳細な利用方法については、NVIDIA TensorRT-LLM ドキュメントをご覧ください。
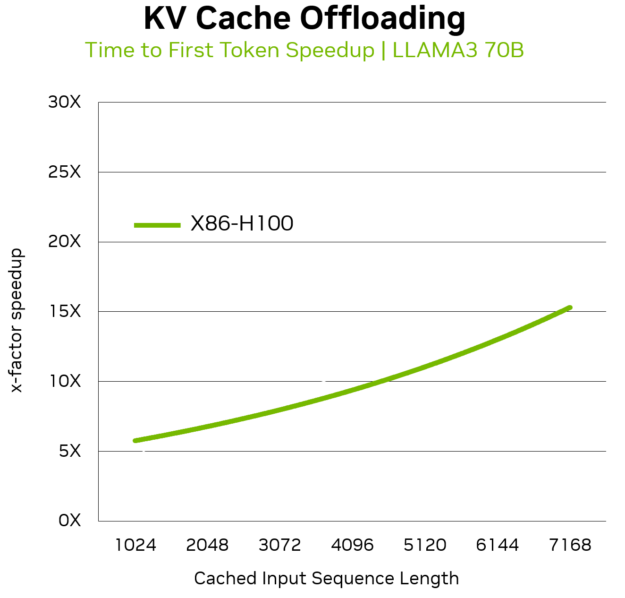
PCIe を介して NVIDIA H100 Tensor コア GPU を x86 ホスト プロセッサに接続したサーバーで動作する Llama 3 70B モデルでは、KV キャッシュ オフロードによって、TTFT を最大 14 倍高速化できます。このため、有意義なユーザー体験を維持しながら、LLM をコスト効率良く提供したいと考えているデータ センター、CSP、アプリケーション プロバイダーにとって魅力的なデプロイ戦略となります。
NVIDIA GH200 コンバージド CPU-GPU メモリによる KV キャッシュ オフロードの高速化
従来の x86 ベースの GPU サーバーでは、KV キャッシュのオフロードは、128 GB/秒の PCIe 接続を介して行われます。複数のマルチターン ユーザー プロンプトを含む大規模なバッチ サイズの場合、低速の PCIe インターフェイスは、パフォーマンスを妨げる可能性があり、TTFT が、通常リアルタイムのユーザー体験に関連付けられる 300 ミリ秒 ~ 500 ミリ秒の閾値を超えてしまいます。
NVIDIA GH200 Grace Hopper Superchip は、低速 PCIe インターフェイスのこの課題を克服することができます。NVIDIA GH200 は、NVLink-C2C 相互接続技術を使用して、ARM ベースの NVIDIA Grace CPU と NVIDIA Hopper GPU アーキテクチャを統合した新しいクラスのスーパーチップです。NVLink-C2C は、CPU と GPU 間で最大 900 GB/秒の合計帯域幅を提供します。これは、従来の x86 ベースの GPU サーバーで見られる標準的な PCIe Gen5 レーンよりも 7 倍広い帯域幅です。さらに、GH200 では、CPU と GPU がプロセスごとに 1 つのページ テーブルを共有し、すべての CPU スレッドと GPU スレッドが、物理 CPU または GPU メモリに格納できるシステムによって割り当てられたメモリにアクセスできるようにします。

GH200 の Llama 3 70B モデルの KV キャッシュをオフロードすると、マルチターン シナリオで x86-H100 のオフロードと比較して、TTFT が最大 2 倍高速化されます。これにより、マルチターンのユーザーとのやり取りが頻繁に行われる場所に LLM をデプロイする組織は、システム全体のスループットを犠牲にすることなく、組織はユーザーのインタラクティブ性を向上させることができます。

NVIDIA Grace Hopper と NVLink-C2C による Llama 3 の優れた推論
KV キャッシュ オフロードは、システム全体のスループットを低下させることなく、マルチターンのユーザーとのやり取りで TTFT を改善できるため、CSP、データ センター、AI アプリケーション プロバイダーの間で注目を集めています。NVIDIA GH200 Superchip の 900 GB/秒 NVLink-C2C を活用することで、人気の高い Llama 3 モデルの推論を、システム スループットを低下させることなく、最大 2 倍高速化することができます。これにより、企業はインフラ投資を追加することなく、ユーザー体験を向上させることができます。
現在、NVIDIA GH200 は、世界中の 9 台のスーパーコンピューターに搭載されており、幅広いシステム メーカーから提供され、Vultr、Lambda、CoreWeave などのクラウド プロバイダーでオンデマンドでアクセスできます。NVIDIA LaunchPad を通じて、NVIDIA GH200 を無料でテストすることもできます。
関連情報
- GTC セッション: Grace Hopper のディープラーニング アプリケーション向けスーパーチップ アーキテクチャとパフォーマンスの最適化
- GTC セッション: FlashAttention: IO を意識した高速かつメモリ効率の高い正確なアテンション
- NGC コンテナー: Llama-3-Swallow-70B-Instruct-v0.1
- NGC コンテナー: Llama-3.1-Nemotron-70B-Instruct
- ウェビナー: データの洞察を引き出す