
GPU の性能が年々向上する一方で、世の中には様々な規模の処理が存在しています。その中には、高性能な GPU を使い切るには至らない、比較的軽い処理も存在します。本日は、NVIDIA Ampere Architecture から導入された MIG (Multi-Instance GPU) と、MIG を活用した性能向上の例として、日本語 NLP 用ライブラリである GiNZA のベンチマーク結果について紹介していきます。
なお本記事は、GiNZA の開発者である、株式会社リクルート Megagon Labs 松田 寛様との共同記事となります。
GiNZA について
GiNZA は、複数の言語を横断して一貫した構文構造のアノテーションなどを可能にするためのフレームワークである Universal Dependencies に基づいて開発された、日本語の解析機能を備えた初めてのオープンソース ライブラリです。様々な文章の文法的構造の解析や、文の中での単語間の関係性の分類などを行うことができます。GiNZA は、Universal Dependencies の解析系として世界で広く利用されている spaCy をフレームワークとして用いることで、使い方がわかりやすく、また、高精度な学習済みモデルを利用できることが大きな特徴です。同時に商用利用可能なライセンス体系下 (MIT License) でモデルが配布されている点も注目すべき特徴です。これにより、産業応用において、安心して利用できるライブラリの一つとなっています。さらに、GiNZA の解析モデルは spaCy と互換性があり、spaCy が提供する英語など 18 以上の言語の解析モデルと簡単に切り替えて使用することができます。利用例は公式の GitHub が詳しいですが、例えば以下のように解析対象の文を入力してみます。
import spacy
nlp = spacy.load("ja_ginza_electra")
sentences=["NVIDIA A100 TensorコアGPUはあらゆる規模で前例のない高速化を実現し、世界最高のパフォーマンスを誇るエラスティックデータセンターにAI、データ分析、HPCのためのパワーを与えます。", \
"対話型AIといった次のレベルの課題に挑むAIモデルは、爆発的に複雑化しています。"]
docs = nlp.pipe(sentences)
for doc in docs:
for sent in doc.sents:
for token in sent:
print(
token.i,
token.orth_,
token.lemma_,
token.norm_,
token.morph.get("Reading"),
token.pos_,
token.morph.get("Inflection"),
token.tag_,
token.dep_,
token.head.i,)
print("EOS")
print("")
すると、解析結果として以下のように、品詞などの情報が得られます。
0 NVIDIA NVIDIA NVIDIA ['エヌビディア'] PROPN [] 名詞-固有名詞-一般 nmod 2
1 A a a ['アール'] NOUN [] 名詞-普通名詞-助数詞可能 compound 2
2 100 100 100 ['イチレイレイ'] NUM [] 名詞-数詞 compound 3
3 Tensor tensor tensor ['テンソル'] NOUN [] 名詞-固有名詞-一般 ROOT 3
4 コア コア コア ['コア'] NOUN [] 名詞-普通名詞-形状詞可能 compound 5
…
EOS
0 対話型 対話型 対話型 ['タイワガタ'] NOUN [] 名詞-普通名詞-一般 compound 1
1 AI AI AI ['エーアイ'] NOUN [] 名詞-普通名詞-一般 nmod 9
2 と と と ['ト'] ADP [] 助詞-格助詞 case 1
3 いっ いう 言う ['イッ'] VERB ['五段-ワア行;連用形-促音便'] 動詞-一般 fixed 2
4 た た た ['タ'] AUX ['助動詞-タ;連体形-一般'] 助動詞 fixed 2
…
EOS
内部的には構文解析モデルによる推論が実行されていますが、特に transformers ベースのモデルが利用される場合、spacy.require_gpu() を呼び出しておくことで、GPU によるさらに高速な実行が可能になります。
モデル自体の学習にも注力されており、バージョン 5 では上記の例でも使われている transformers ベースの学習済みモデル ( ja-ginza-electra ) が追加され、解析精度がさらに向上しています。この ja-ginza-electra の学習には NVIDIA が提供している ELECTRA 実装と Google Cloud の NVIDIA A100 インスタンスが利用されています。
一方で、transformers ベースのモデルが導入されたことからもわかるかと思いますが、解析精度を優先すると、必然的に計算量が増えてしまう状況にあります。そのため、GPU などの計算機をより効率的に扱えることは、重要度を増しています。
MIG について
こうした状況の中、NVIDIA は 2 年前の 2020 年に、新しい GPU となる NVIDIA A100 を発表しました。A100 には様々な機能が搭載されていますが、中でもGPU の利用効率を上げるための重要な機構として、MIG (Multi-Instance GPU) が挙げられます。
MIG は、単一の GPU 上で複数のプロセスを安全に同時実行できるようにする機構で、A100 の場合、1 つの GPU を最大で 7 分割することができます。この分割はハードウェア的に実現されているため、各分割単位に割り当てられたプロセスは互いに干渉することなく独立して処理を実行でき、GPU のコアを隙間なく動作させることがより簡単になります。実際には、1 つの GPU 上で動作するアプリケーションで発生したエラーを、同じ GPU 上のほかのアプリケーションに波及させないようにするエラー隔離など、従来にない重要な機能も MIG には多く含まれますが、この記事では割愛します。また、先日発表された H100 での第二世代 MIG については、H100 の製品ページから参照できる whitepaper や、NVIDIA Hopper Architecture In-Depth (日本語版) などの記事をご覧ください。
MIG そのものの詳細な使い方等は、NVIDIA Multi-Instance GPU User Guide に詳しく記載されていますが、大きく、
- MIG が有効になっていなければ有効化する
- 必要なサイズの GPU Instance および Compute Instance を作成
という 2 ステップで利用可能になります。このとき、最大分割である 7 分割をすると、最小の MIG デバイスは 1g.5gb という単位となります。これは 5GB のメモリと、14 個の streaming multiprocessor (SM) からなる 1 つの Graphics Processing Cluster (GPC) を持つ単位で、逆に MIG 有効時の最大単位は 7g.40gb となります。この場合、フルの 40GB メモリと、7 つの GPC (=98 SM) を一体として利用できます。(注. 今回の実験で使用するような A100 80GB 版の場合は、メモリ サイズが倍になります)
今回この記事では、MIG を利用して、GiNZA の言語解析処理をどこまでスケールさせることができるか、ということについて検証していきます。
性能測定方法と条件
この計測では、GiNZA 公式のベンチマーク コードを利用し、単位時間当たりの処理文数 (=スループット) を計算し比較評価します。比較する条件として、以下の全組み合わせで実行し、かかった処理時間を記録、そこからスループットを算出して評価します。
- モデル:
ja_core_news_md,ja_core_news_trf,ja_ginza,ja_ginza_electraの 4 パターンja_core_news_mdおよびja_ginzaは比較的計算負荷の低いモデルja_core_news_trfおよびja_ginza_electraは計算負荷の高いモデル
- バッチ サイズ: 1, 2, 4, 8, 16, 32, 64, 128 の 8 パターン
- GPU/MIG: 1x7g.80gb、1x7g.80gb (7process)、7x1g.10gb、1x1g.10gb の 4 パターン
- 1x7g.80gb: MIG 有効時の最大サイズ (=分割なし) で 1 プロセスだけ実行
- 1x7g.80gb (7process): 同じく分割なしだが 7 プロセス同時に実行
- 7x1g.10gb: MIG 有効状態で 7 分割し 7 プロセス同時に実行
- 1x1g.10gb: 同じく 7 分割だが、1 プロセスだけ実行
MIG のパターンがわかりづらいと思いますので図にしてみました。内部構造は簡略化していますが、おおむね以下のようなイメージです。1x1g.10gb の場合、プロセスが割り当てられていない残りの 6 つについては一切の処理が動いておらず、遊んでいる状態となります。

最後に、実験に利用したマシンの構成とライブラリ等のバージョンは以下の通りです。
マシン構成 (DGX A100)
- CPU: AMD EPYC 7742 64-Core Processor x 2
- GPU: NVIDIA A100 SXM @ 80GB
- System memory: 2 TB
ライブラリ バージョン
- NGC PyTorch container image 21.10 (PyTorch 1.10.0a0+0aef44c, CUDA 11.4.2, cuBLAS 11.6.5.2, cuDNN 8.2.4.15)
- spaCy 3.2.1
- GiNZA 5.1.0
測定結果
MIG によるスケーリング性能を見る前に、まず MIG を有効化していない GPU 上の単一プロセスで、各モデルの推論を実行したときの GPU 使用率を見てみます。以下のグラフは各モデルについて、バッチ サイズ 128 で、ウォームアップとして 5 回推論実行した後に、10 回推論実行した際の平均 GPU 使用率を示しています。
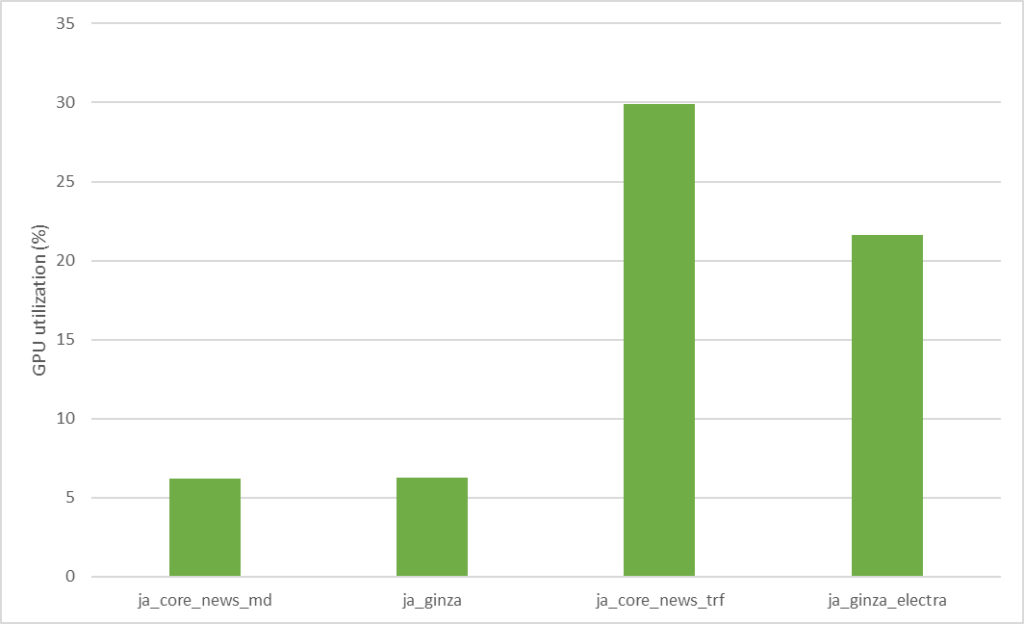
このグラフからもわかる通り、負荷の高い 2 つのモデル (ja_core_news_trf & ja_ginza_electra) でも、GPU 使用率は 30% を下回っており、まだまだ各モデルとも GPU に余力がありそうです。バッチ サイズを上げることで、より負荷を高めて性能を向上させられそうに思われますが、少なくとも今回のケースでは、MIG を利用したほうが効率的です。(この一例については後述)
上記の結果を踏まえて、複数プロセスを同時に実行することで性能が向上するか、測定結果を確認してみましょう。以降の各グラフは、モデルごとの測定結果を示します。最初の 2 つが計算負荷の低いモデル (ja_core_news_md & ja_ginza) での結果、残りの 2 つが計算負荷の高いモデル (ja_core_news_trf & ja_ginza_electra) での結果です。横軸はバッチ サイズを表します。折れ線グラフはいずれもスループット (sentences / sec) で、棒グラフは、1 プロセスのみ実行した場合と、7 プロセスでスケールさせた場合との性能比を示します。これは、MIG による分割有無によって、プロセスの同時実行性能がどのような影響を受けたのかを確認するものとなります。
まず計算負荷の低いモデル 2 つですが、棒グラフに表れている通り、MIG による分割を行うことで良くスケールしており、多少のばらつきはあるものの、安定して 7 倍近いスループットが得られています。一方 MIG による分割をしない場合は、バッチ サイズが大きくなるにつれてスケールするようになるものの、プロセスを増やしただけの向上率には届かない状況です。MIG を利用して GPU を分割していないことにより、プロセス間の干渉が発生することが要因と考えられます。
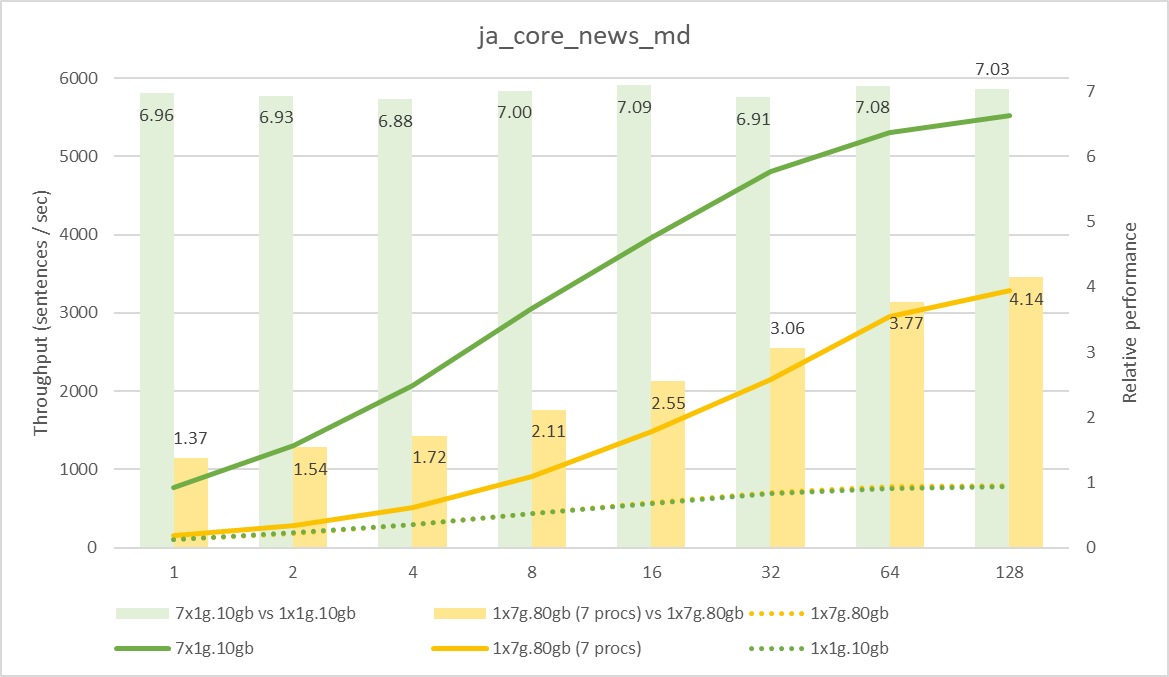
ja_core_news_md の測定結果
ja_ginza の測定結果続いて計算負荷の高いモデルです。
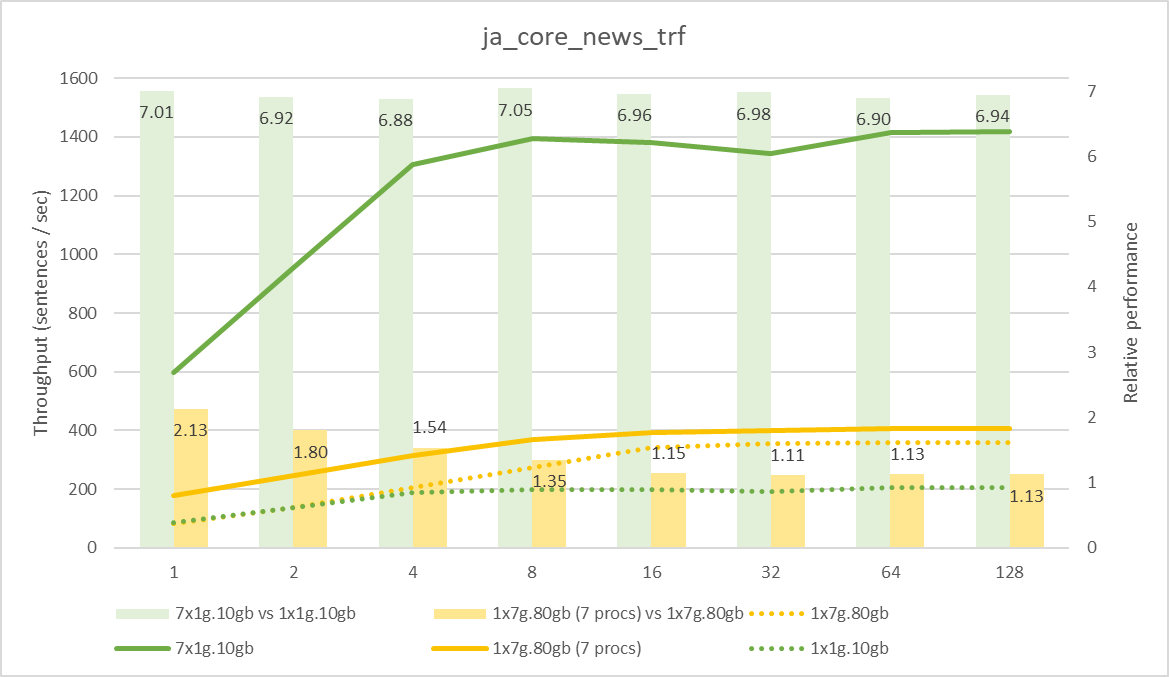
ja_core_news_trf の測定結果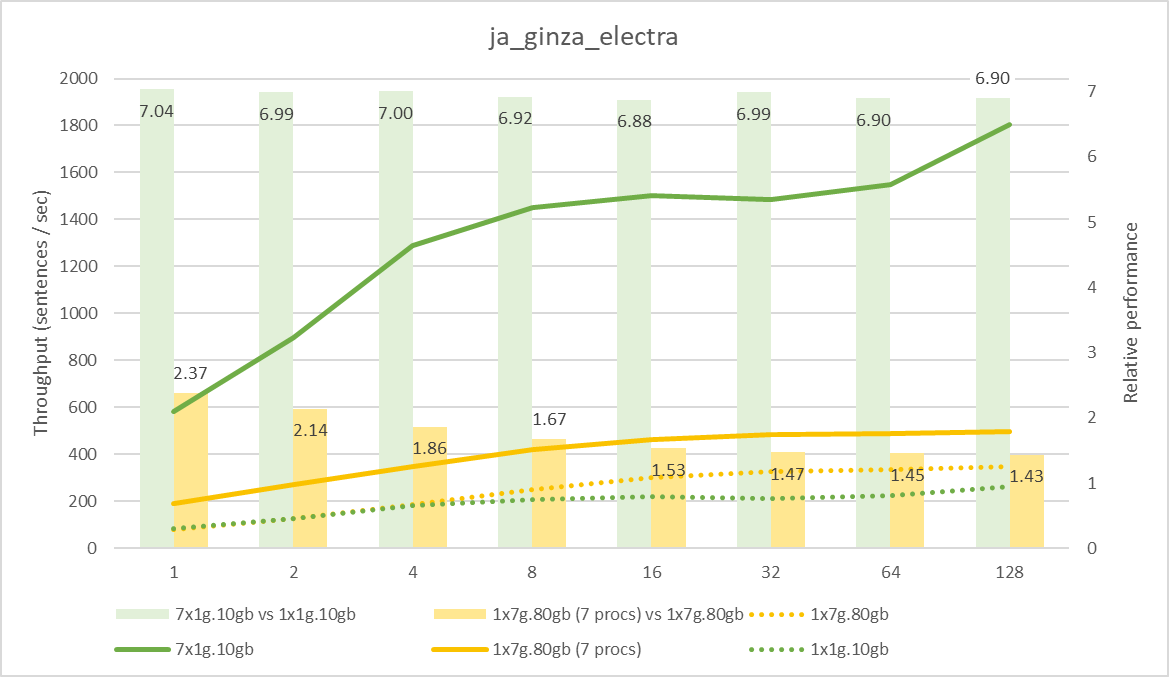
ja_ginza_electra の測定結果こちらはさらに顕著です。MIG による分割を行わない場合、仮に同時に実行するプロセス数を増やしたとしても、トータルの性能は向上しないことがわかります。MIG で分割することで、安定して処理をスケールさせることができ、結果として GPU の使用効率を高めることが可能となります。
ただし、ここで 1 つ、「MIG を使わない場合でも、1 プロセスのバッチ サイズを 7 倍にしたら同じくらいの性能に到達するのでは?」という疑問が出てくるかもしれません。そこで追加実験として、7 プロセスそれぞれがバッチ サイズ 128 の場合と、1 プロセスで 7 倍に相当するバッチ サイズ 896 で実行した場合とを比較してみます。これにより、全体として同じサイズの問題を与えられた時の MIG による貢献度合いが明確になるかと思います。また、このセクション冒頭でも記述した、「バッチ サイズを上げれば性能が上がるのでは?」という想定への答えにもなっています。結果のグラフは以下の通りです。
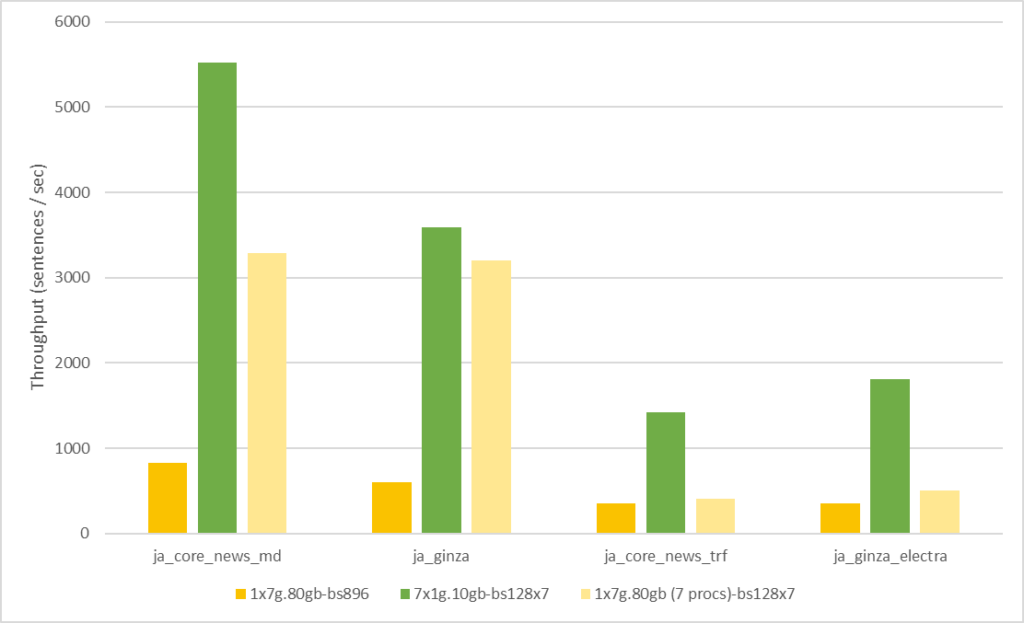
濃い黄色のバーが、GPU 全体を利用してバッチ サイズ 896 の処理を 1 プロセスで実行した場合の結果を示し、緑色のバーは、MIG の分割ありで 7 プロセスそれぞれでバッチ サイズ 128 の処理を実行した結果です。薄い黄色のバーは参考としての、MIG 分割なしの場合の 7 プロセス実行の結果です。この結果から、単純にバッチ サイズを増やす以上に、MIG により分割された GPU 上で複数プロセスを用いて推論実行するケースの方が、安定して性能を向上させられることが読み取れます。
まとめ
日本語処理ライブラリである GiNZA を例に、MIG により処理性能がうまくスケールするかどうかを検証しました。結果として、MIG を利用して GPU を分割することにより、安定して、かつ、単一プロセスでは到達しない領域にまでスループットを向上させられることを確認しました。この記事が、今後の GPU 利用に対し、1 つの指針となれば幸いです。
謝辞
本記事の執筆に際し、佐々木邦暢、村上真奈の両氏には、記事のレビューで有益なコメントをいただきました。加えて、記事の執筆にご協力いただいたすべての NVIDIA 関係者に感謝いたします。