NVIDIA TensorRT の主な機能は、ネットワーク定義を処理し、最適なエンジン実行プランに変換することで実現するディープラーニングの推論の高速化です。 TensorRT Engine Explorer (TREx) は、 TensorRT エンジン プランとそれに関連する推論プロファイリングデータを探るための Python ライブラリと Jupyter Notebook のセットです。
TREx は、生成されたエンジンの可視性を提供し、要約された統計、チャート作成ユーティリティ、およびエンジン グラフの可視化を通じて新しい洞察を得ることができるようにします。TREx は、2 つのバージョンのネットワークの性能を比較するなど、ハイレベルなネットワーク性能の最適化とデバッグに有効です。詳細なパフォーマンス分析には、 NVIDIA Nsight Systems が推奨されるパフォーマンス分析ツールです。
この投稿では、TREx のワークフローを要約し、データと TensorRT エンジンを調べるための API 機能を紹介します。
TREx の仕組み
TREx の主要な抽象化機能は trex.EnginePlan で、エンジンに関連するすべての情報をカプセル化しています。EnginePlan は複数の入力 JSON ファイルから構成され、それぞれがデータ依存関係グラフやプロファイリング データなど、エンジンの異なる側面を記述しています。EnginePlan の情報は、Pandas DataFrame という使い慣れた、強力で便利なデータ構造でアクセスすることができます。
TREx を使用する前に、エンジンのビルドとプロファイリングを行う必要があります。TREx は、これを行うためのシンプルなユーティリティ スクリプト process_engine.py を提供しています。このスクリプトは参考として提供されるものであり、あなたが選択した方法でこの情報を収集することができます。
このスクリプトは、trtexec を用いて ONNX モデルからエンジンを構築し、エンジンのプロファイリングを行います。また、エンジン構築とプロファイリング セッションの様々な側面を記録するいくつかの JSON ファイルを作成します。
Plan-graph の JSON ファイル
plan-graph JSON ファイルは、エンジンのデータフロー グラフを JSON 形式で記述したものです。
TensorRT エンジン プランとは、 TensorRT エンジンのシリアル化されたフォーマットです。最終的な推論グラフに関する情報が含まれており、推論ランタイムの実行のためにデシリアライズすることができます。
TensorRT 8.2 では、エンジンのレイヤー、その構成、およびデータの依存関係を調べる機能を提供する IEngineInspector API が導入されました。IEngineInspector では、シンプルな JSON フォーマット スキーマを使用してこの情報を提供しています。この JSON ファイルは、TREx trex.EnginePlan オブジェクトへの主要な入力であり、必須です。
プロファイリング JSON ファイル
プロファイリング JSON ファイルは、各エンジン レイヤーのプロファイリング情報を提供します。
trtexec コマンドライン アプリケーションは IProfiler インターフェイスを実装し、各レイヤーのプロファイリング記録を含む generates JSON ファイルを生成します。このファイルは、エンジンの構造を調べるだけで、関連するプロファイリング情報を必要としない場合は、オプションとして使用できます。
タイミング レコード JSON ファイル
JSON ファイルには、各プロファイリングのイテレーションのタイミング レコードが含まれています。
trtexec では、エンジンのプロファイリングを行うために、エンジンを何度も実行し、測定ノイズを平滑化しています。各エンジン実行のタイミング情報は、タイミング JSON ファイルに個別のレコードとして記録することができ、平均測定値はエンジン レイテンシとして報告されます。このファイルはオプションで、一般にプロファイリング セッションの品質を評価する際に役立ちます。
エンジンのタイミング情報に過度のばらつきが見られる場合は、 GPU 専用機能を使用し、演算クロックとメモリ クロックがロックされていることを確認するとよいでしょう。
メタデータ JSON ファイル
メタデータ JSON ファイルには、エンジンのビルダー設定と、エンジンの構築に使用された GPU に関する情報が記述されています。この情報は、エンジン プロファイリング セッションにより意味のあるコンテキストを提供し、特に 2 つ以上のエンジンを比較するときに便利です。
TREx のワークフロー
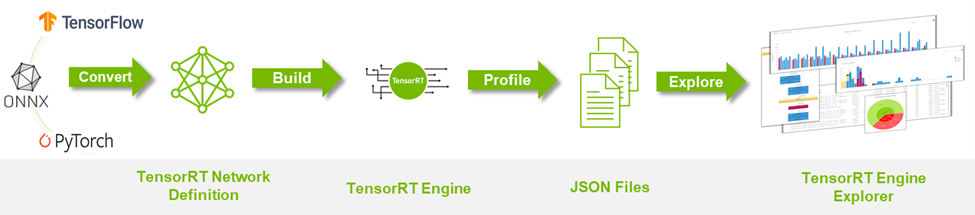
図 1 は、TREx のワークフローをまとめたものです。
- まず、ディープラーニング モデルを TensorRT ネットワークに変換することから始めます。
- エンジンのビルドとプロファイリングを行いながら、付随する JSON ファイルを生成します。
- TREx をスピンアップして、ファイルの中身を調査します。
TREx の機能と API
すべてのプロファイリング データを収集した後、EnginePlan インスタンスを作成することができます。
plan = EnginePlan(
"my-engine.graph.json",
"my-engine.profile.json",
"my-engine.profile.metadata.json")
trex.EnginePlan インスタンスでは、 Pandas DataFrame オブジェクトを通してほとんどの情報にアクセスすることができます。DataFrame の各行は、計画ファイルの 1 つのレイヤーを表し、その名前、タクト、入力、出力、およびレイヤーを説明するその他の属性が含まれます。
# Print layer names
plan = EnginePlan("my-engine.graph.json")
df = plan.df
print(df['Name'])
エンジン情報を DataFrame で抽象化すると、多くの Python 開発者が知っている API であると同時に、データをスライス、ダイシング、エクスポート、グラフ化、印刷する機能を備えた強力な API でもあるので便利です。
例えば、エンジンの中で最も遅い 3 つのレイヤーをリストアップするのは簡単です。
# Print the 3 slowest layers
top3 = plan.df.nlargest(3, 'latency.pct_time')
for i in range(len(top3)):
layer = top3.iloc[i]
print("%s: %s" % (layer["Name"], layer["type"]))
features.16.conv.2.weight + QuantizeLinear_771 + Conv_775 + Add_777: Convolution
features.15.conv.2.weight + QuantizeLinear_722 + Conv_726 + Add_728: Convolution
features.12.conv.2.weight + QuantizeLinear_576 + Conv_580 + Add_582: Convolution
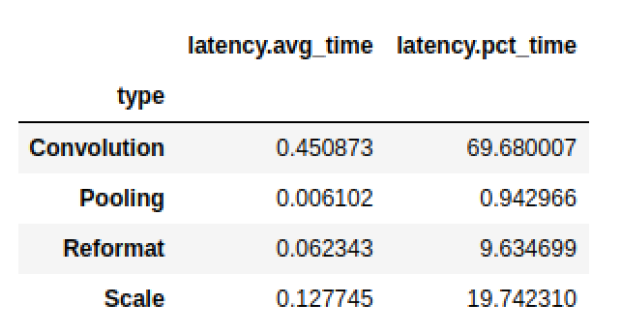
私たちはしばしば、情報をグループ化したいと思います。例えば、各レイヤー タイプごとのレイテンシの合計を知りたい場合があります。
# Print the latency of each layer type plan.df.groupby(["type"]).sum()[["latency.avg_time"]]
Pandas は、データフレームの表示や解析に便利な dtale や, インタラクティブなプロットによるグラフ作成ライブラリの Plotly などのライブラリとうまく混在しています。どちらのライブラリもサンプルの TREx ノートブックに統合されていますが、qgrid、matplotlib、Seaborn などユーザーフレンドリーな代替案も多く存在します.
また、Pandas、Plotly、dtale の薄いラッパーである便利な API もあります。
- データのプロット (
plotting.py) - エンジングラフの可視化 (
graphing.py) - インタラクティブ ノートブック (
interactive.py、notebook.py) - レポート (
report_card.py、compare_engines.py)
最後に、linting API (lint.py) は静的解析を使用して、ソフトウェア リンターに似たパフォーマンス ハザードをフラグを立てます。理想的には、レイヤー リンターは、エンジンの性能を向上させるために行動できる専門的な性能フィードバックを提供します。例えば、最適でない畳み込み入力形状や量子化レイヤーの最適でない配置を使用している場合などです。このリント機能は初期の開発段階にあり、NVIDIA はこの機能を改善する予定です。
TREx には、チュートリアル ノートブックと、1 つのエンジンを分析するためのノートブックと 2 つ以上のエンジンを比較するためのワークフローノートブックも付属しています。
TREx API を使用すると、 TensorRT エンジンを探索、抽出、表示する新しい方法をコード化し、コミュニティと共有することができます。
TREx ウォークスルー例
TREx の動作がわかったところで、TREx の動作を示す例を紹介します。
この例では、量子化された TensorRT エンジンを最適化したものを作成します。 ResNet18 PyTorch モデル を作成し、プロファイリングし、最後に TREx を使用してエンジン プランを検査します。そして、学習結果に基づいてモデルを調整し、性能を向上させます。この例のコードは、 TREx GitHub リポジトリで利用可能です。
まず、 PyTorch ResNet モデルを ONNX 形式でエクスポートします。この時 NVIDIA PyTorch 量子化ツールキット モデル内に量子化レイヤーを追加するためのものですが、精度ではなく性能に集中しているため、キャリブレーションや微調整は行いません。
実際のユース ケースでは、完全な量子化を考慮したトレーニング (QAT) レシピに従うべきです。QAT Toolkit は自動的に Torch モデルに擬似量子化操作を挿入します。これらの操作は QuantizeLinear およびDequantizeLinear ONNX 演算子としてエクスポートされます。
import torch
import torchvision.models as models
# For QAT
from pytorch_quantization import quant_modules
quant_modules.initialize()
from pytorch_quantization import nn as quant_nn
quant_nn.TensorQuantizer.use_fb_fake_quant = True
resnet = models.resnet18(pretrained=True).eval()
# Export to ONNX, with dynamic batch-size
with torch.no_grad():
input = torch.randn(1, 3, 224, 224)
torch.onnx.export(
resnet, input, "/tmp/resnet/resnet-qat.onnx",
input_names=["input.1"],
opset_version=13,
do_constant_folding=False,
dynamic_axes={"input.1": {0: "batch_size"}})
次に、TREx ユーティリティ process_engine.py のスクリプトを使用して、以下のことを行います。
- ONNX モデルからエンジンを作る。
- エンジンプランの JSON ファイルを作成します。
- エンジンの実行をプロファイリングし、その結果をプロファイリング JSON ファイルに保存します。また、タイミング結果をタイミング JSON ファイルに記録します。
python3 <path-to-trex>/utils/process_engine.py /tmp/resnet/resnet-qat.onnx /tmp/resnet/qat int8 fp16 shapes=input.1:32x3x224x224
process_engine.py スクリプトは trtexec を使って重い処理をします。process_engine.py コマンド ラインから trtexec に引数を渡すには、単に引数を -- 接頭辞なしで列挙すれば透過的に渡せます。
この例では、引数 int8、fp16、shapes=input.1:32x3x224x224 は、FP16 と INT8 の精度に最適化し、入力バッチサイズを 32 に設定するよう指示し、trtexec に転送されます。スクリプトの最初のパラメーターは入力 ONNX ファイル (/tmp/resnet/resnet-qat.onnx) で、2 番目のパラメーター (/tmp/resnet/qat) は生成された JSON ファイルを格納するためのディレクトリを指します。
これで最適化されたエンジン ファイルを調べる準備ができましたので、TREx Engine Report Card ノートブックに移動してください。この記事では、この例で役に立ついくつかのセルだけで、ノートブック全体を見ることはしません。
最初のセルでは、エンジン ファイルを設定し、様々な JSON ファイルから trex.EnginePlan インスタンスを作成します。
engine_name = "/tmp/resnet/qat/resnet-qat.onnx.engine"
plan = EnginePlan( f"{engine_name}.graph.json",
f"{engine_name}.profile.json",
f"{engine_name}.profile.metadata.json")
次のセルは、エンジンのデータ依存グラフを可視化したもので、元のネットワークからエンジンへの変換を理解する上で最も有用なものです。 TensorRT では、エンジンを並列化可能なグラフとしてではなく、トポロジ的にソートされたレイヤー リストとして実行します。
デフォルトのレンダリング フォーマットは SVG で、検索可能で、異なるスケールでもシャープな状態を維持し、スペースを取らずに追加情報を提供するホバーテキストをサポートします。
graph = to_dot(plan, layer_type_formatter) svg_name = render_dot(graph, engine_name, 'svg')
この関数は、SVG ファイルを作成し、その名前を表示します。ノートブック内でのレンダリングは小規模なネットワークでも面倒なので、SVG ファイルを別のブラウザー ウィンドウで開いてレンダリングすることも可能です。
TREx のグラフ API は設定可能で、様々な色付けやフォーマットが可能であり、利用可能なフォーマッタは情報満載です。例えば、デフォルトのフォーマッタでは、レイヤーは演算に応じて色分けされ、名前、タイプ、プロファイルされたレイテンシによってラベル付けされます。テンソルはレイヤー間を結ぶエッジとして描かれ、精度に応じて色分けされ、形状やメモリ レイアウトの情報がラベル付けされています。
生成された ResNet QAT エンジンのグラフ (図 3) には、いくつかの FP32 テンソル (赤色) が見えます。INT8 精度を用いてできるだけ多くのレイヤーを実行させたいので、さらに調査してください。INT8 データおよび計算精度を使用することで、スループットが向上し、レイテンシと消費電力が削減されます。

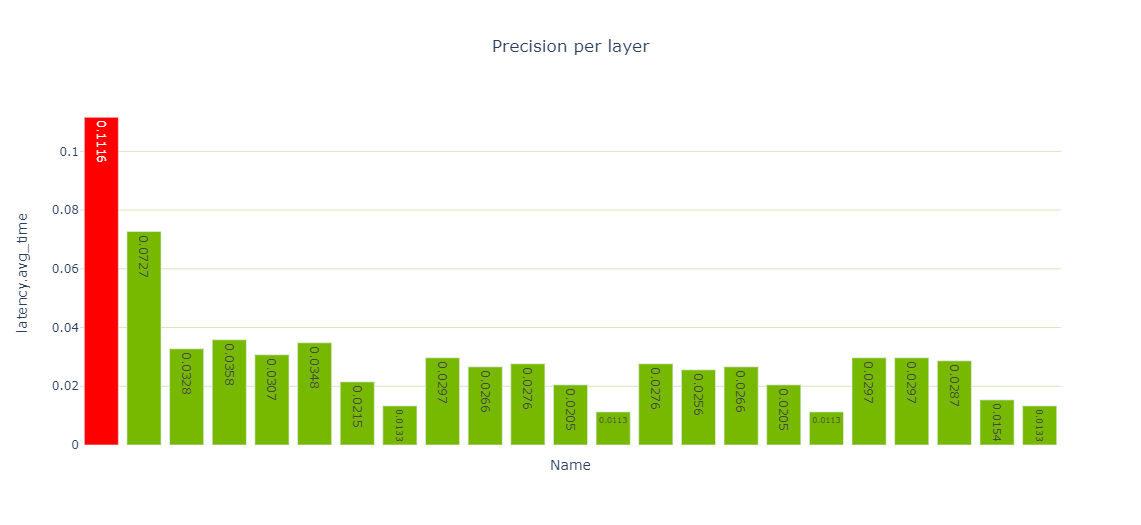
パフォーマンス セルでは、パフォーマンス データのさまざまなビューが提供され、特に precision-per-layer 型 (図 4) では、FP32 と FP16 を使って計算する複数のレイヤーが示されています。Jupyter-Labではデフォルトでセットされた図しか表示されず切り替え処理ができないので Jupyter Notebook を使用してください。
report_card_perf_overview(plan)
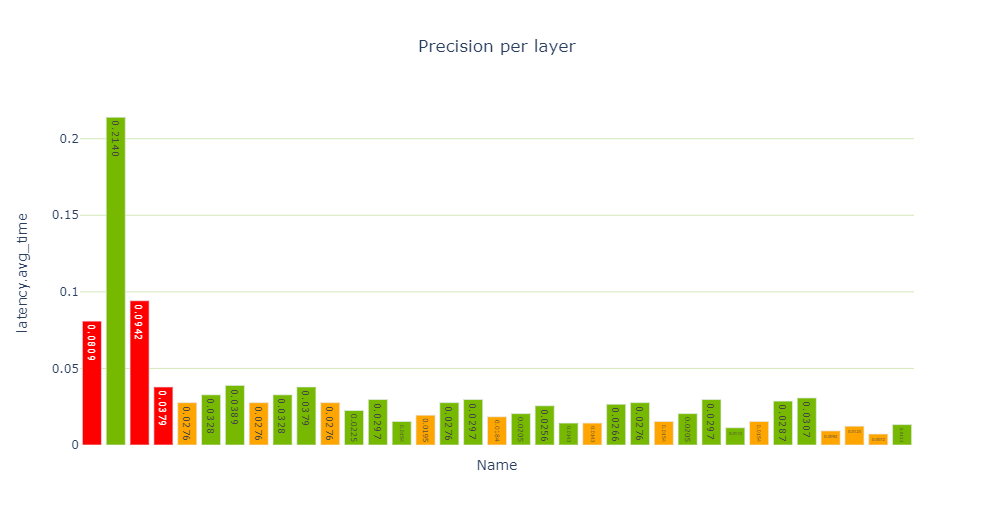
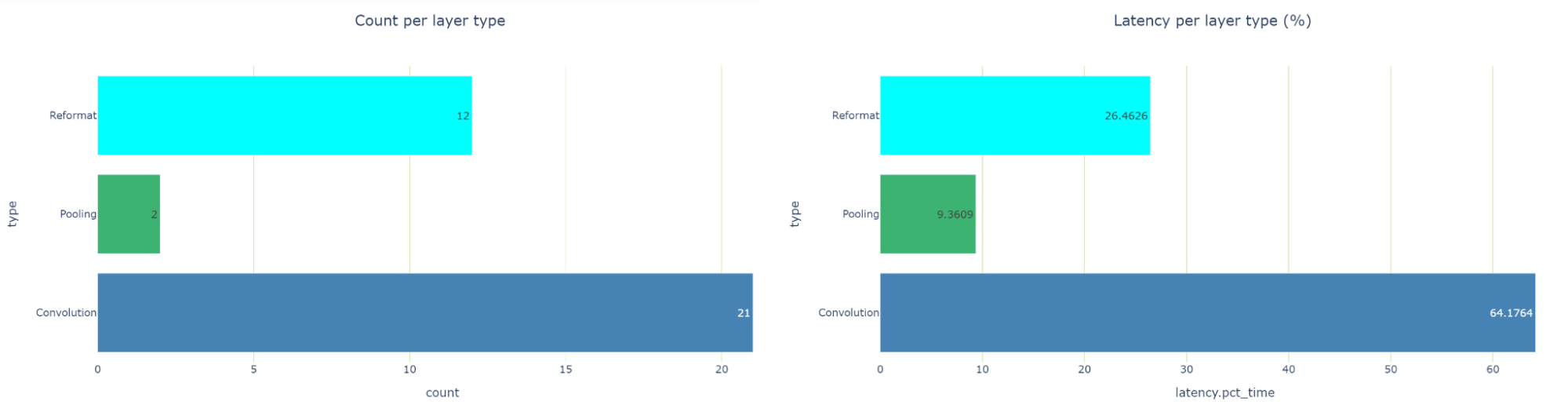
latency-per-layer-type 型の表示で調べると、実行時間の約 26.5 %を占める 12 個の再フォーマット ノードがあることがわかります。これはかなり多いですね。リフォーマット ノードは最適化の際にエンジン グラフに挿入されますが、精度を変換する際にも挿入されます。各リフォーマット層には、その存在理由を記述した origin 属性があります。
もし、精度の変換が多すぎるようであれば、これらの変換を減らすために何かできることがないかを確認する必要があります。TensorRT 8.2では、Q/DQ 操作のためのリフォーマット レイヤーではなく、スケール レイヤーが表示されます。これは、 TensorRT 8.2 と 8.4 で使用されているグラフ最適化ストラテジの違いによるものです。
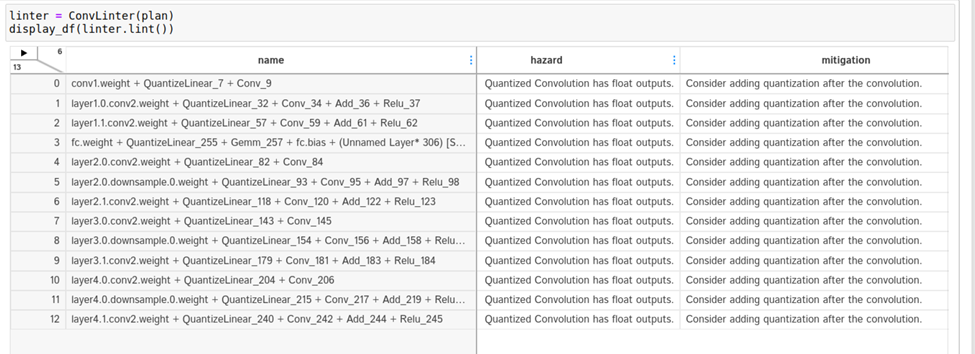
より深く掘り下げるには、linting セルで利用可能なエンジンの linting API に目を向けてください。Convolution と Q/DQ リンターの両方が、いくつかの潜在的な問題にフラグを立てていることがわかります。
Convolution リンターは、INT8 入力と FP32 出力を持つ 13 個の Convolution にフラグを立てます。理想的には、INT8 精度のレイヤーが続く場合、畳み込みが INT8 データを出力するようにしたいものです。
下記コードでは display_df(linter.lint()) を使用しているのですが、動作しないケースがあります。その場合は display(ConvLinter(plan).lint()) を使用してください。
リンターは Convolution の後に量子化演算を追加することを提案しています。なぜこれらの Convolution の出力は量子化されないのでしょうか?
もっと詳しく見てみましょう。エンジン グラフの Convolution を調べるには、リンター テーブルから Convolution の名前をコピーして、グラフ SVG ブラウザー タブで検索してください。これらの Convolution は残差加算演算に関与していることがわかります。
Q/DQ Layer-Placement Recommendations を参照した後、 PyTorch モデルの残差接続に Q/DQ レイヤーを追加する必要があると結論付けたかもしれません。残念ながら、QAT ツールキットはこれを自動的に実行することができないので、PyTorch モデルのコードに手動で介入する必要があります。詳細については、 TensorRT QAT Toolkit (resnet.py) の例を参照してください。
次のコード例は、BasicBlock.forward 方式です。
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
if self._quantize:
out += self.residual_quantizer(identity)
else:
out += identity
out = self.relu(out)
return out
PyTorch コードを変更した後、モデルを再生成し、変更後のモデルを使用してノートブックのセルを再び反復処理しなければなりません。現在では、3 つの再フォーマット層が全レイテンシの約 20.5 %の割合になり (26.5% から減少)、ほとんどの層が INT8 精度で実行されるようになりました。
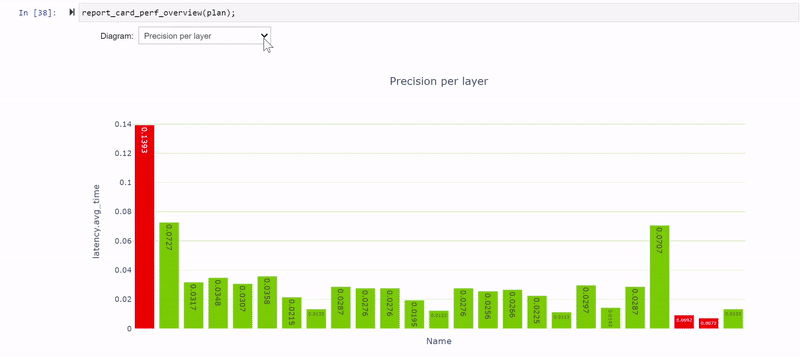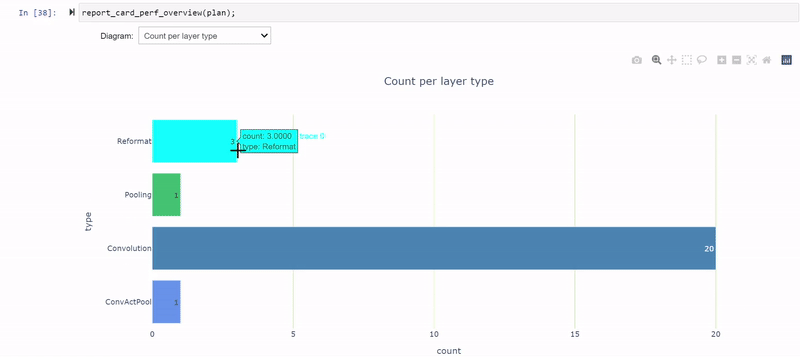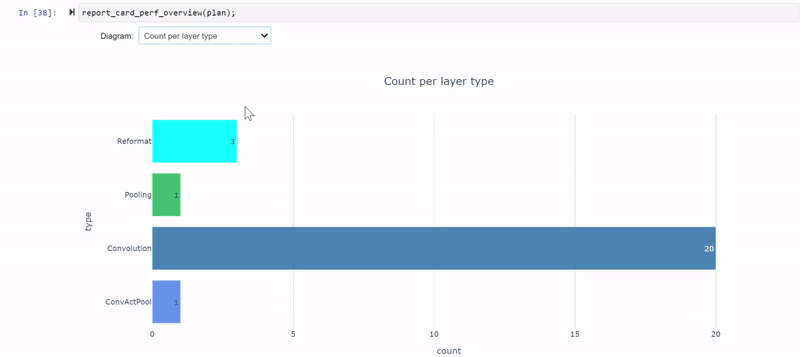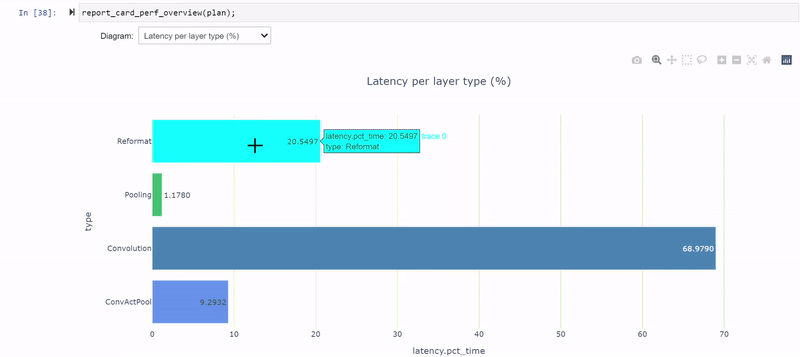
残りの FP32 層は、ネットワークの末端にある Global Average Pooling (GAP) 層を取り囲んでいます。GAP 層を量子化するために再度モデルを修正します。
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self._quantize_gap:
x = self.gap_quantizer(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
新しいモデルを使用して、ノートブックのセルを最後にもう 1 度反復します。これで、再フォーマット レイヤーは 1 つだけになり、他のすべてのレイヤーが INT8 で実行されるようになりました。成功です!
最適化が終わったので、 エンジン比較ノートブック を使って 2 つのエンジンを比較することができます。このノートブックは、今回のようにネットワークのパフォーマンスを積極的に最適化する場合だけでなく、次のような場合にも有効です。
- 異なる GPU HW プラットフォームや異なる TensorRT バージョン用に作られたエンジンを比較したい場合。
- 異なるバッチサイズに対してレイヤーのパフォーマンスがどのように変化するかを評価したい場合。
- エンジン間の精度の不一致が、 TensorRT レイヤーの精度選択の違いに起因しているかどうかを把握する。
Engine Comparison ノートブックは、エンジンを比較するために表形式とグラフ形式の両方のビューを提供し、必要な詳細レベルに応じて、どちらも適用可能です。図 8 は、 PyTorch ResNet18 モデル用に構築した 5 つのエンジンのレイテンシの積み上げたものを示したものです。簡潔さのために、FP32 と FP16 エンジンの作成については説明しませんでしたが、これらは TREx GitHub リポジトリで試すことができます。
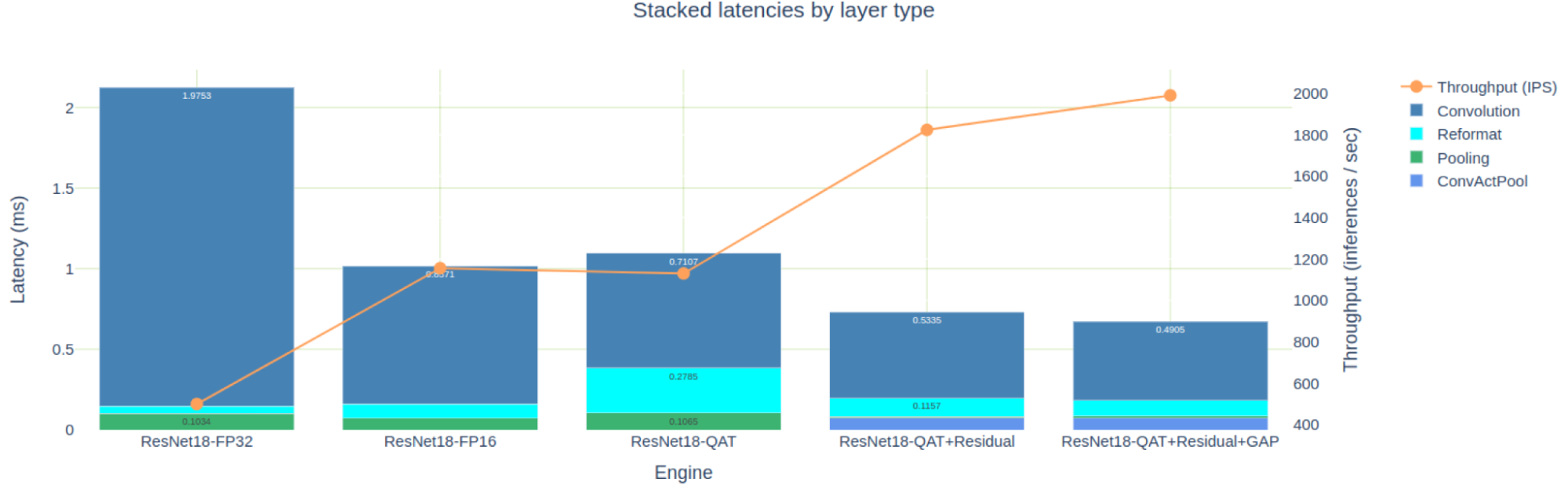
FP16 精度に最適化されたエンジンは、FP32 エンジンより約 2 倍高速ですが、私たちが最初に試みた INT8 QAT エンジンより高速でもあります。先に分析したように、これは FP16 データを出力した後、INT8 に明示的に量子化し直すために再フォーマット層を必要とする多くの INT8 Convolution が影響しています。
この投稿で最適化された 3 つの QAT エンジンのみに注目すると、残差接続に Q/DQ を追加することで、11 個の FP16 エンジン層が削除されたことがわかります。また、GAP レイヤーを量子化することで、さらに 2 つの FP32 レイヤーが削除されました。
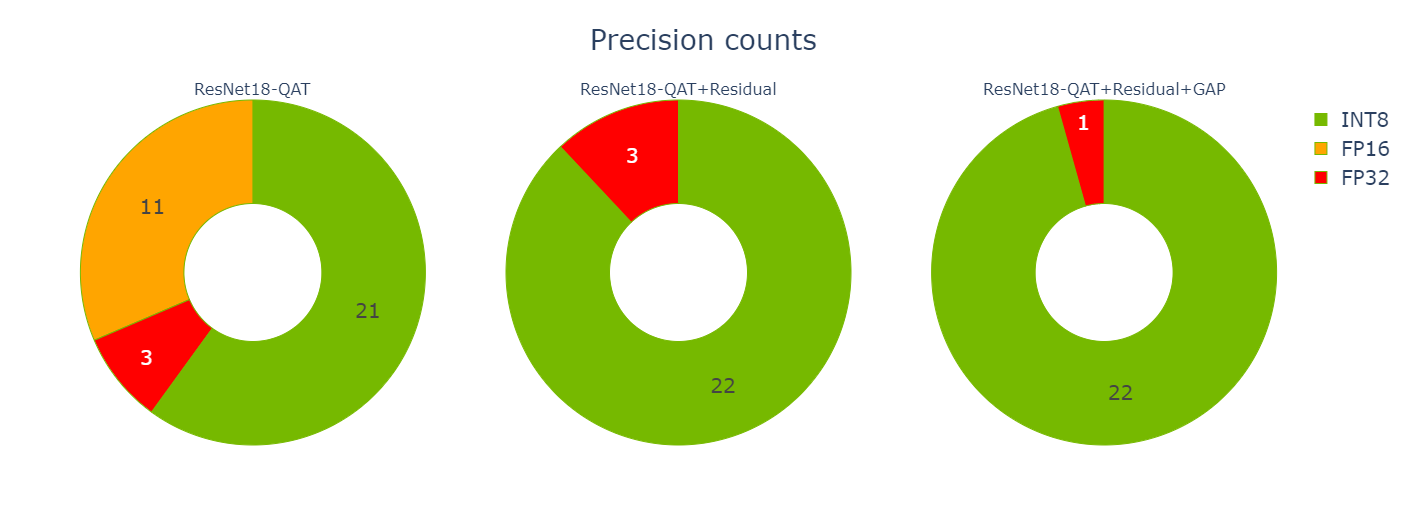
また、最適化が 3 つのエンジンのレイテンシにどのような影響を与えたかを見ることができます (図 10)。
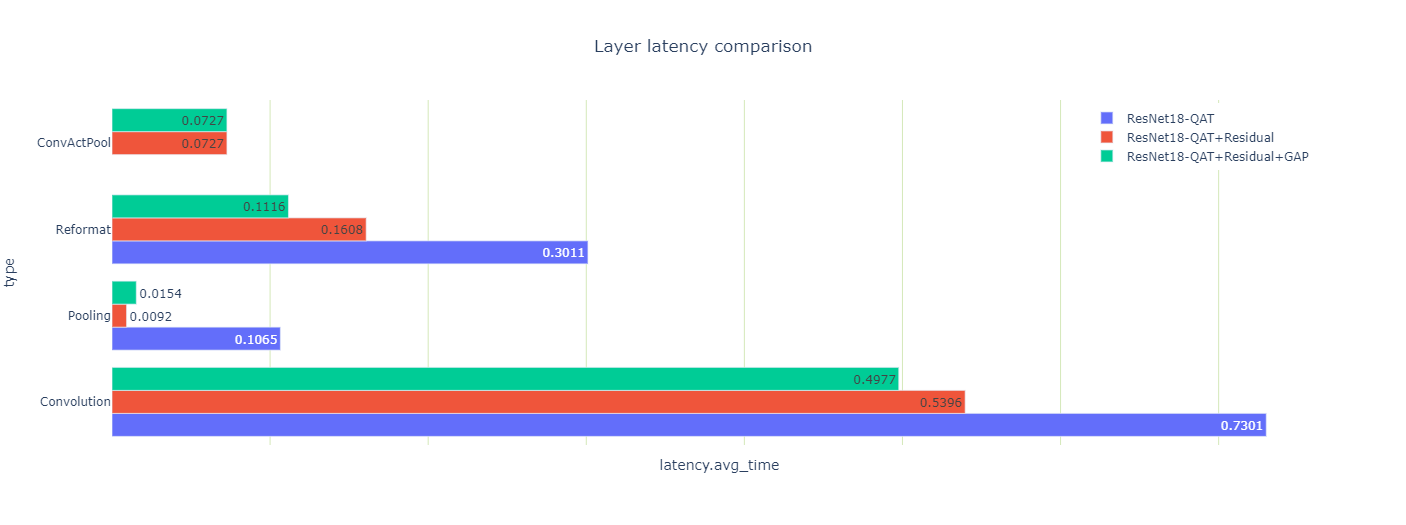
プーリングレイヤーのレイテンシの結果が、いくつか奇妙に見えるかもしれません。残差接続を量子化するとプーリング レイテンシの合計は 10 倍になり、GAP レイヤーを量子化すると 70% 増加します。
どちらの結果も直感に反しているので、もっとよく見てみてください。2 つのプーリング層があり、最初の Convolution の後に大きなものがあり、最後の Convolution の前にもう 1 つ小さなものがあります。残差結合を量子化した後、最初のプーリング層と Convolution 層は INT8 精度で出力を使って実行することができます。これらは、ConvActPool 層に挟まれたReLUと融合されますが、この融合は浮動小数点型ではサポートされません。
なぜ GAP 層は量子化されるとレイテンシが増加したのでしょうか? この層の活性化のサイズは小さく、各 INT8 入力係数は高精度を用いて平均化するために FP32 に変換されるからです。最後に、その結果を INT8 に戻しています。
このレイヤーのデータ サイズも小さく、高速な L2 キャッシュに存在するため、余分な精度変換の計算が相対的に高価になります。それでも、GAP 層を取り巻く 2 つの再フォーマット層を取り除くことができたので、(本当に重要な) エンジン全体の待ち時間は短縮されました。
まとめ
この投稿では、 TensorRT Engine Explorer を紹介し、その API と機能を簡単にレビューし、TREx が TensorRT engine のパフォーマンスを最適化する際に役立つことを示す例を通して説明しました。TREx は TensorRT の GitHub リポジトリの experimental tools ディレクトリで利用可能です。
ぜひ API を試して、2 つのワークフローノートブックにとどまらず、新しいワークフローを構築してください。
翻訳に関する免責事項
この記事は、「Exploring NVIDIA TensorRT Engines with TREx」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。