
ソブリン AI モデルは、特定の文化的や言語的ニュアンスに合わせて調整されているため、文脈を理解し適切な応答を生成する上でより効果的です。さらに、これらのモデルは地域のイノベーションを支援し、各国がそれぞれのニーズや優先事項に沿った AI 技術を開発することを可能にします。
その結果、世界各国から支持されるソブリン AI モデルを開発しようという動きが高まっています。実際に、各国政府は、研究者や企業が自国民のニーズに特化した AI システムを構築できるようにするための構想を開始し、計算インフラに予算を割り当てています。
最も先進的な日本語 AI モデル
このたび、東京科学大学 (旧・東京工業大学) と産業技術総合研究所 (AIST)は、Llama 3.1 をベースに、日本特有の言語的/文化的ニーズによりよく応えるように設計された独自のソブリン AI モデル「Llama 3.1 Swallow」を共同開発しました。
研究チームでは、CommonCrawl から配布されているアーカイブ全量から、日本語のテキストを独自に抽出/精錬した Swallow Corpus Version 2 という日本語ウェブコーパスを構築し、NVIDIA NeMo でも利用可能な Megatron-LM を使用してモデル学習を行いました。この新しいコーパスは、前バージョンの Swallow model に使用された Swallow Corpus Version 1 よりも約 4 倍大きく、より包括的で文化的に適切な AI 能力を日本向けに強化しています。
最終的な学習データは、ウィキペディアのデータに数学やコーディングなどのコンテンツを混ぜて、約 2,000 億トークンで構成され、モデルの継続事前学習に使用されました。
パフォーマンス
この Llama 3.1 Swallow モデルは、読解、要約、推論、マルチターン会話、コーディングなど、日本語および英語の様々なベンチマークにおいて、最高水準の性能を発揮します。
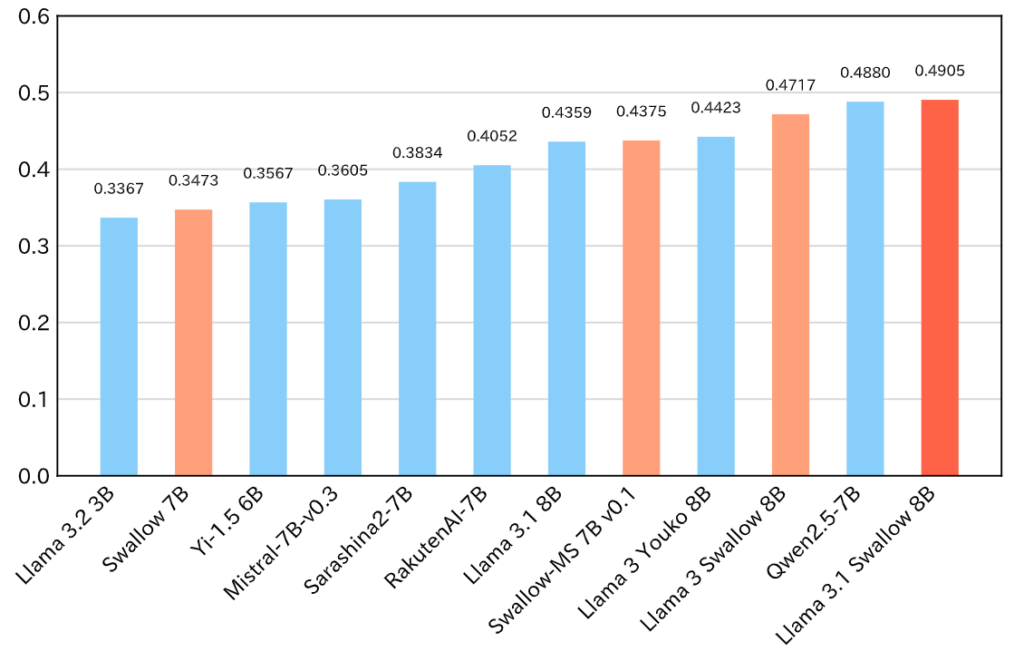
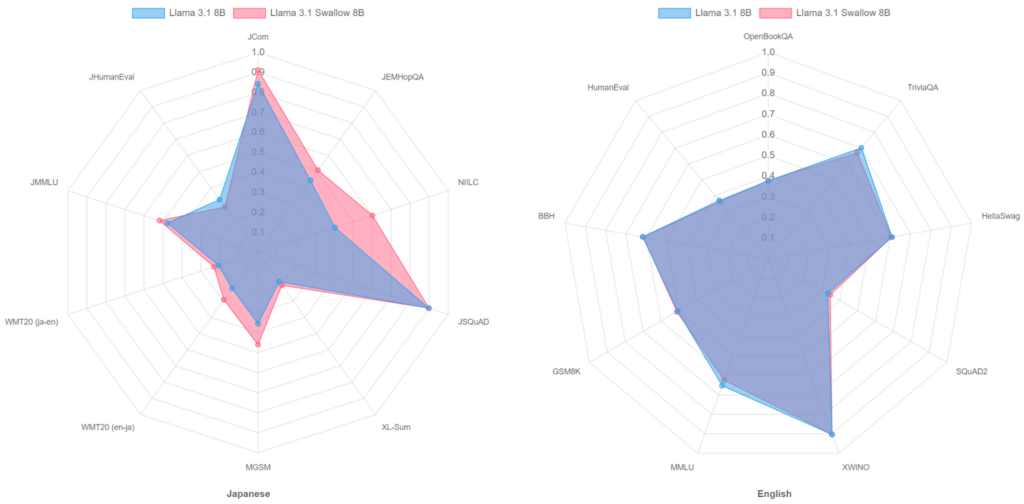
継続事前学習によって大規模言語モデルに新たな機能を追加する場合、ベース モデルがもともと持っていた能力が劣化したり、失われたりすることがあります。Llama 3.1 Swallow のベース モデルである Meta’s Llama 3.1 の英語スキルや算術スキルなどの本来の能力を維持することは、算術推論、一般教養、コード生成など様々なタスクに有効です。英語力などのベース モデルの能力を損なわないようにしながら、モデルの日本語能力を強化することは、挑戦的ではありますが、取り組むべき重要な課題でした。その取り組みの結果、Llama3.1 Swallow は Llama3.1 の英語能力を維持しつつ、日本語能力を向上させることに成功しました。
NVIDIA NIM でデプロイを簡単に
NVIDIA は、東京科学大学および産業技術総合研究所と提携し、Llama 3.1 Swallow 8B および 70B モデルを NVIDIA NIM マイクロサービスとしてパッケージ化することで、GPU アクセラレーション システム間でのシームレスな展開を可能にしました。このコラボレーションにより、日本の研究者や企業は、このソブリン AI モデルを API エンドポイントとして簡単にデプロイし、アプリケーションを更にパワーアップすることが可能になります。
NVIDIA NIM の柔軟性と性能を活用することで、このモデルは生成 AI ワークフローに統合することができ、文化研究から、法律業務、政府サービス、患者ケアをサポートするビジネス アプリケーションまで、幅広いユース ケースで利用できるようになります。
ユース ケースに合わせたファインチューニング
この Swallow モデルを活用することで、例えば、金融機関が地域の規制コンプライアンスを遵守するのに役立ったり、小売業者が文化的ニュアンスを反映したローカライズされたカスタマー サービスを通じて恩恵を得ることができるでしょう。また、 ヘルスケアでは、このモデルによって、ネイティブ スピーカーに英語で説明するのが難しい病状や治療法を簡単に説明することも可能になります。
このモデルが地域的なタスクに対して優れたパフォーマンスを発揮する一方、開発者は、タスク固有のスキル、ドメイン知識、語彙を追加するために、オープン モデルをカスタマイズする必要があります。
NVIDIA NeMo は、カスタム生成 AI を開発するためのエンドツーエンドのプラットフォームであり、モデルのカスタマイズを簡素化します。 高度なファインチューニング機能と、P-Tuning、LoRA (低ランク適応)、QLoRA のような PEFT (Parameter-Efficient Fine-Tuning) 技術によるアライメント サポートにより、大規模なコンピューティング リソースがなくてもカスタム モデルを簡単に作成することができます。
NeMo は SFT や、RLHF、DPO、NeMo SteerLM などのアライメント技術もサポートしています。 これらの技術により、モデルの応答をさらに舵取り可能にし、人間の嗜好に合わせることができるため、LLM をカスタム アプリケーションに統合することができます。
AI アプリケーションを迅速に構築
NeMo は、DGX Cloud 上で生成 AI モデルを構築、カスタマイズ、展開するためのプラットフォームおよびサービスである NVIDIA AI Foundry の一部としても利用可能です。また、NVIDIA AI Enterprise により、エンタープライズグレードのセキュリティ、安定性、サポートを提供し、企業がアプリケーションをより早く市場に投入できるよう支援します。
はじめましょう
ai.nvidia.com からあなたのブラウザーで直接 Swallowモデルを体験できます。 ここでは、Llama3.1 70B、Gemma 2 9B、Mixtral 8X22B などの人気モデルもご覧いただけます。
無料の NVIDIA クラウド クレジットを利用すれば、フルに高速化されたスタック上で実行される NVIDIAホストの API エンドポイントにアプリケーションを接続して、モデルの規模でのテストや実証 (POC) を構築、開始することができます。