
量子コンピューターのアプリケーションやアルゴリズムを開発する上で、量子回路シミュレーションは非常に重要です。既知の量子コンピューターのアルゴリズムやユースケースは破壊的であるため、政府、企業、アカデミアの量子アルゴリズム研究者は、これまでにない大規模な量子システムで新しい量子アルゴリズムを開発し、ベンチマークを実施しています。
大規模でエラー訂正可能な量子コンピューターが存在しないため、これらのアルゴリズムを開発するには、量子回路シミュレーションが最適な方法となります。量子回路シミュレーションは計算量が多く、GPU は量子状態を計算するための自然なツールです。より大規模な量子システムをシミュレーションするためには、スーパーコンピューターの計算能力をフル活用するために、複数の GPU と複数のノードに計算を分散させる必要があります。
NVIDIA cuQuantum は、量子回路シミュレーションを GPU で簡単に加速しスケールできるようにするソフトウェア開発キット (SDK) で、量子的優位性への道筋を探るための新しい能力を促進するものです。
この SDK には、最近リリースされた NVIDIA DGX cuQuantum Appliance (デプロイ可能なソフトウェア コンテナー) が含まれており、マルチ GPU ステート ベクトル シミュレーションをサポートしています。また、一般化されたマルチ GPU API も cuStateVec で利用可能になり、あらゆるシミュレーターに簡単に統合できるようになりました。テンソル ネットワーク シミュレーションでは、cuQuantum の cuTensorNet ライブラリが提供する Slicing API により、テンソル ネットワークの縮約をマルチ ノードやマルチ GPU に分散して高速化することができます。これにより、ユーザーはほぼリニアな強力なスケーリングを持つ DGX A100 システムを利用することができるようになりました。
NVIDIA cuQuantum SDK は、ステート ベクトルとテンソル ネットワーク メソッドのためのライブラリを備えています。この記事では、マルチノード ステート ベクトル シミュレーション用の cuStateVec と DGX cuQuantum Appliance に焦点を当てます。cuTensorNet とテンソル ネットワーク メソッドの詳細については、「Scaling Quantum Circuit Simulation with NVIDIA cuTensorNet」をご覧ください。
マルチノード、マルチ GPU のステート ベクトル シミュレーションとは
ノードとは、ラックに対応したフォーム ファクターを維持しながら、連携して動作するように最適化されタイトに相互接続されたプロセッサで構成される単一パッケージ ユニットのことです。マルチノード マルチ GPU ステート ベクトル シミュレーションは、ノード内の複数の GPU と、複数ノードの GPU を利用することで、解を得るまでの時間を短縮し、他の方法では不可能な大きな問題サイズを扱えるようにします。
DGX により、ユーザーは大容量メモリ、低遅延、高帯域幅を活用することができます。DGX H100 システムは、第 4 世代の NVLink と第 3 世代の NVSwitch を活用し、8 基の H100 Tensor Core GPU で構成されています。このノードは、量子回路シミュレーションで威力を発揮します。
NVIDIA マルチ GPU 対応 DGX cuQuantum Appliance を DGX A100 ノードの 8 基の GPU すべてで実行すると、64 コアのデュアル AMD EPYC 7742 プロセッサと比較して、3 つの一般的な量子計算アルゴリズムで 70 倍から 290 倍のスピードアップを達成することができました。量子フーリエ変換、Shor のアルゴリズム、Sycamore の Supremacy 回路です。これにより、ユーザーは 1 つの DGX A100 ノード (8 GPU) を使用して、フル ステート ベクトル法で最大 36 量子ビットのシミュレーションを行うことができます。図 1 に示す結果は、私たちのチームが実装したソフトウェアのみの機能強化により、この機能のベンチマークは前回発表した時と比較して 4.4 倍向上していることを示しています。
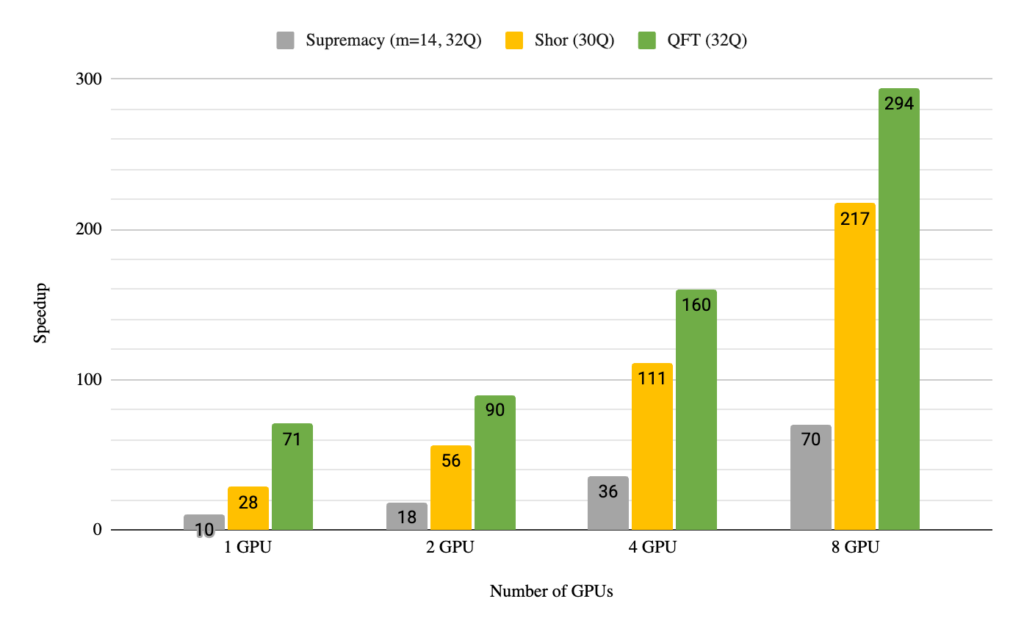
NVIDIA cuStateVec チームは、1 つのノード内の複数の GPU に加えて,複数のノードを活用する性能の高い手段を集中的に調査してきました。ほとんどのゲート アプリケーションは完全な並列処理であるため、ノード内およびノード間の GPU を指揮して、分割統治することができます。
シミュレーションでは、ステート ベクトルを分割して GPU に分散させ、各 GPU はステート ベクトルの一部に対して並列にゲートを適用することができます。多くの場合、これはローカルに処理できますが、高次の量子ビットへのゲート適用には、分散したステート ベクトル間の通信が必要です。
典型的なアプローチとしては、まず量子ビットの並び替えを行い、他の GPU やノードにアクセスすることなく、各 GPU でゲートを適用する方法があります。この並べ替え自体、デバイス間のデータ転送が必要です。これを効率的に行うには、高いインターコネクト バンド幅が非常に重要になります。この並列性を効率的に利用することは、複数ノードにまたがっても自明ではありません。
マルチノード DGX cuQuantum Appliance のご紹介
高効率で任意にスケールするステート ベクトルベースの量子回路シミュレーションの答えがここにあります。NVIDIA は、新しい DGX cuQuantum Appliance で提供されるマルチノード、マルチ GPU 機能を発表できることを嬉しく思います。次のリリースでは、cuQuantum コンテナーのユーザーは誰でも、IBM Qiskit フロントエンドを迅速かつ容易に活用し、世界最大の NVIDIA システム上で量子回路シミュレーションを行うことができるようになる予定です。
cuQuantum の使命は、できるだけ多くのユーザーが量子回路シミュレーションを簡単に高速化し、拡張できるようにすることです。そのために、cuQuantum チームは、NVIDIA マルチノード アプローチを API にする製品の実現に取り組んでおり、来年早々には一般公開される予定です。このアプローチにより、より幅広い NVIDIA GPU ベースのシステムを活用して、ステート ベクトル量子回路シミュレーションを拡張することができるようになります。
NVIDIA マルチノード DGX cuQuantum Appliance は開発の最終段階にあり、NVIDIA DGX SuperPOD システムで得られるクラス最高の性能をまもなく利用できるようになります。これは、Docker と数行のコードにより素早くデプロイ可能な NGC ホストのコンテナー イメージとして提供される予定です。
DGX システムの中で最速の I/O アーキテクチャを備えた NVIDIA DGX H100 は、NVIDIA DGX SuperPOD などの大規模 AI クラスター、柔軟性に優れた AI のための企業向けの青写真、そして今回の量子回路シミュレーション インフラ向けの基礎となるビルディング ブロックです。DGX H100 の 8 基の NVIDIA H100 GPU は、新しく高性能な第 4 世代 NVLink 技術を使用し、4 つの第 3 世代 NVSwitch を介して相互接続します。
第 4 世代の NVLink 技術は、前世代の 1.5 倍の通信帯域幅を実現し、PCIe Gen5 と比較して最大 7 倍高速化されています。GPU 間の総スループットは最大 7.2 TB/秒を実現し、前世代の DGX A100 と比較して約 1.5 倍に向上しています。
8 基の NVIDIA ConnectX-7 InfiniBand / Ethernet アダプター (それぞれ 400 GB/秒で動作) が搭載された DGX H100 システムは、複数のノードに分散したステート ベクトル間のグローバル通信のオーバーヘッドを低減する、強力な高速ファブリックを提供します。マルチノード、マルチ GPU の cuQuantum と、最先端のネットワーキング ハードウェアおよびソフトウェアの最適化を活用した大規模な GPU アクセラレーテッド コンピューティングの組み合わせは、DGX H100 システムが、50 量子ビットを超える大量のステート ベクトルの量子回路シミュレーションなどの大規模な課題に対処するために、数百または数千のノードに拡張できることを意味します。
この成果のベンチマークとして、マルチノード DGX cuQuantum Appliance を、NVIDIA DGX SuperPOD システムのリファレンス アーキテクチャである NVIDIA Selene スーパーコンピューター上で実行しました。2022 年 6 月現在、Selene は HPL (High Performance Linpack) ベンチマークを実行するスーパーコンピューティング システムの TOP500 リストで、63.5 ペタフロップスの性能で 8 位、Green500 リストで 1 ワットあたり 24.0 ギガフロップスの性能で 22 位にランクされています。
NVIDIA は、マルチノードの DGX cuQuantum Appliance を活用して、量子ボリューム、量子近似最適化アルゴリズム (QAOA) 、量子位相推定のベンチマークを実施しました。量子ボリューム回路は、深さ 10 と 30 で実行されました。QAOA は、比較的近い将来の量子コンピューターで、組み合わせ最適化問題を解くために使用される一般的なアルゴリズムです。2 つのパラメーターで実行しました。
弱スケーリングと強スケーリングの両方が、前述のアルゴリズムで示されています。NVIDIA DGX SuperPOD のようなスーパーコンピューターへの拡張は、解決までの時間を短縮し、研究者がステート ベクトル量子回路シミュレーション技術で探索できる位相空間を拡大するために重要であることは明らかです。
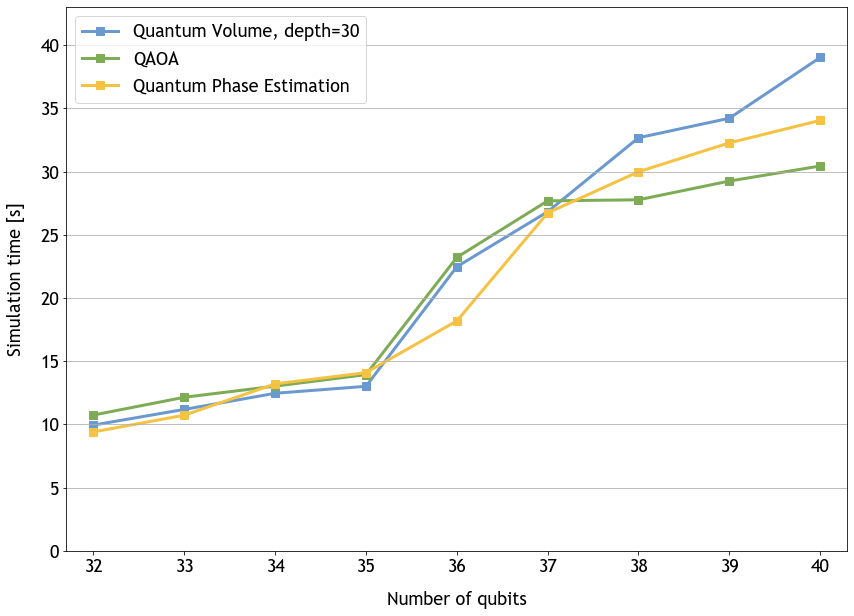
私たちは、アップデートされた DGX cuQuantum Appliance によって、ユーザーがスケーリングを実現することも可能にしています。マルチノード機能を導入することで、1 つの GPU で 32 量子ビットを、1 つの NVIDIA Ampere アーキテクチャのノードで 36 量子ビットを超えることができるようになりました。32 台の DGX A100 ノードで合計 40 量子ビットをシミュレートしています。今後、ユーザーはシステム構成に応じてさらにスケールアウトすることができ、ソフトウェア的には 56 量子ビットまたは数百万の DGX A100 ノードを上限とすることができます。NVIDIA Hopper GPU で行った他の予備テストでは、この数値は私たちの次世代アーキテクチャでさらに向上することが示されています。
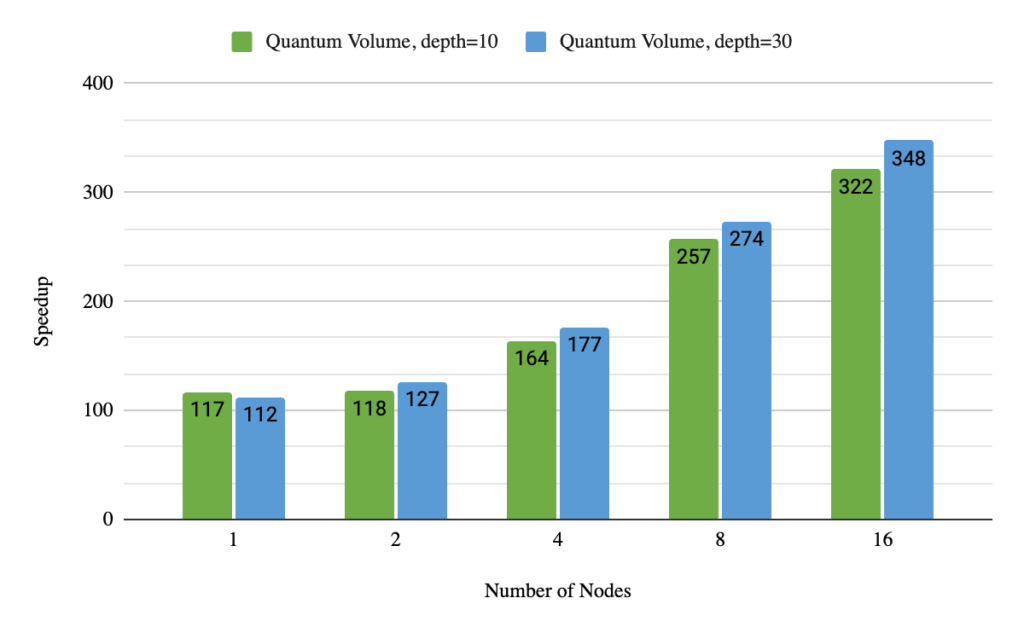
また、マルチノード機能による強スケーリングも測定しています。ここでは、簡単のために量子ボリュームに焦点を当てました。図 3 は、同じ問題を GPU の数を変えながら複数回解いたときの性能です。最新のデュアルソケット サーバー CPU と比較すると、16 台の DGX A100 を活用した場合、320 倍から 340 倍の高速化を達成しました。これは、従来の量子ボリュームの最新の実装 (2 台の DGX A100 ノードで 36 量子ビットの深さ10) と比べても 3.5 倍の高速化です。さらにノードを追加すると、この高速化はより劇的なものとなります。
最大級の NVIDIA システムで量子回路のシミュレーションとスケーリングを実施
NVIDIA の cuQuantum チームは、ステート ベクトル シミュレーションをマルチノード、マルチ GPU に拡張しています。これにより、エンドユーザーは、これまでよりも大きなフル ステート ベクトルの量子回路シミュレーションを行うことができます。cuQuantum は規模だけでなく、性能向上も可能にし、ノード間で弱スケーリングと強スケーリングを示しました。
さらに、cuQuantum は、cuQuantum を搭載した最初の IBM Qiskit イメージを出しました。次のリリースでは、このコンテナーを取得できるようになり、この人気の高いフレームワークによる量子回路シミュレーションの規模拡大がより簡単かつ迅速に行えるようになります。
マルチノード DGX cuQuantum Appliance は現在プライベート ベータ版ですが、NVIDIA は今後数か月の間に一般公開する予定です。cuQuantum チームは、2023 年春までに cuStateVec ライブラリ内のマルチノード API をリリースする予定です。
DGX cuQuantum Applianceの使用開始について
今年後半にマルチノード DGX cuQuantum Appliance が一般提供されると、NGC カタログからコンテナー用の Docker イメージを取得できるようになる予定です。
量子コンピューティング フォーラムを通じて、cuQuantum チームに質問することができます。NVIDIA/cuQuantum GitHub リポジトリで、機能リクエストやバグの報告をお願いします。
詳しくは、以下の資料をご覧ください。
- cuQuantum (cuTensorNet を含む)
- cuQuantum のドキュメント
- NVIDIA/cuQuantum GitHub リポジトリ
- DGX cuQuantum アプライアンス
- 量子コンピューティングとは
- Pennylane と NVIDIA cuQuantum SDK による超高速シミュレーション
- Orquestra と NVIDIA cuQuantum との統合
- NVIDIA cuQuantum と QODA を採用する研究者や科学者が拡大
GTC 2022 と cuQuantum
以下の GTC 2022 のセッションに参加し、NVIDIA cuQuantum やその他の技術の進化について詳細をご覧ください。
- GTC 2022 基調講演
- 最新 HPC ソフトウェア徹底解説
- 量子により加速されたスーパーコンピューターの定義
- 量子アルゴリズムのための cuQuantum による量子回路シミュレーションのスケーリング
- 医薬品研究における量子コンピューティング シミュレーション
- GPU で量子コンピューティング研究を加速する
- 科学のための AI: AI による科学的ブレイクスルーの前触れ
翻訳に関する免責事項
この記事は、「Achieving Supercomputing-Scale Quantum Circuit Simulation with the NVIDIA DGX cuQuantum Appliance」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。