Researchers from Google and Stanford have taught their computer vision model to detect the most important person in a multi-person video scene – for example, who the shooter is in a basketball game which typically contains dozens or hundreds of people in a scene.
Using 20 Tesla K40 GPUs and the cuDNN-accelerated Tensorflow deep learning framework to train their recurrent neural network on 257 NCAA basketball games from YouTube, an attention mask selects which of the several people are most relevant to the action being performed, then tracks relevance of each object as time proceeds. The team published a paper detailing more of their work.
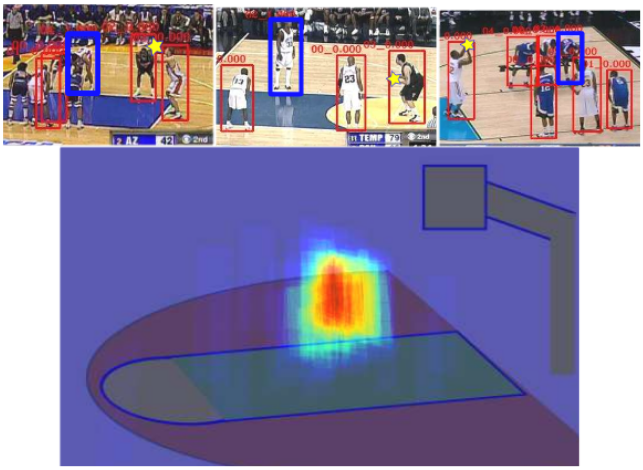
Over time the system can identify not only the most important actor, but potential important actors and the events with which they are associated – such as, the ability to understand the player going up for a layup could be important, but that the most important player is the one who then blocks the shot.
Read more >>
Teaching an AI to Detect Key Actors in Multi-person Videos

Jul 06, 2016
Discuss (0)
AI-Generated Summary
- Researchers from Google and Stanford have developed a computer vision model that can identify the most important person in a video scene with multiple people.
- The model was trained using 20 Tesla K40 GPUs and the cuDNN-accelerated Tensorflow deep learning framework on 257 NCAA basketball games from YouTube.
- The system can track the relevance of each person over time, identifying not only the most important actor but also potential important actors and associated events.
AI-generated content may summarize information incompletely. Verify important information. Learn more