In this blog post, we take a closer look at chunked prefill, a feature of NVIDIA TensorRT-LLM that increases GPU utilization and simplifies the deployment experience for developers. This builds on our previous post discussing how advanced KV cache optimization features in TensorRT-LLM improve performance up to 5x in use cases that require system prefills.
Challenges with traditional prefill and decode inference approaches
When a user submits a request to a model, it goes through two distinct computational phases: prefill and decode. Each phase uses GPU compute resources differently.
During the prefill phase, the system processes all input tokens to compute the KV cache, which is then used to generate the first token of the output. This phase is computationally demanding and can effectively use a GPU’s vast parallel compute resources.
In the decode phase, the system generates output tokens individually, updating the intermediate states from the prefill phase with each new token. Since the heavy computational work for intermediate state calculations is done in the prefill phase, the decode phase primarily involves processing only the newly generated token. As a result, this phase is less computationally intensive.
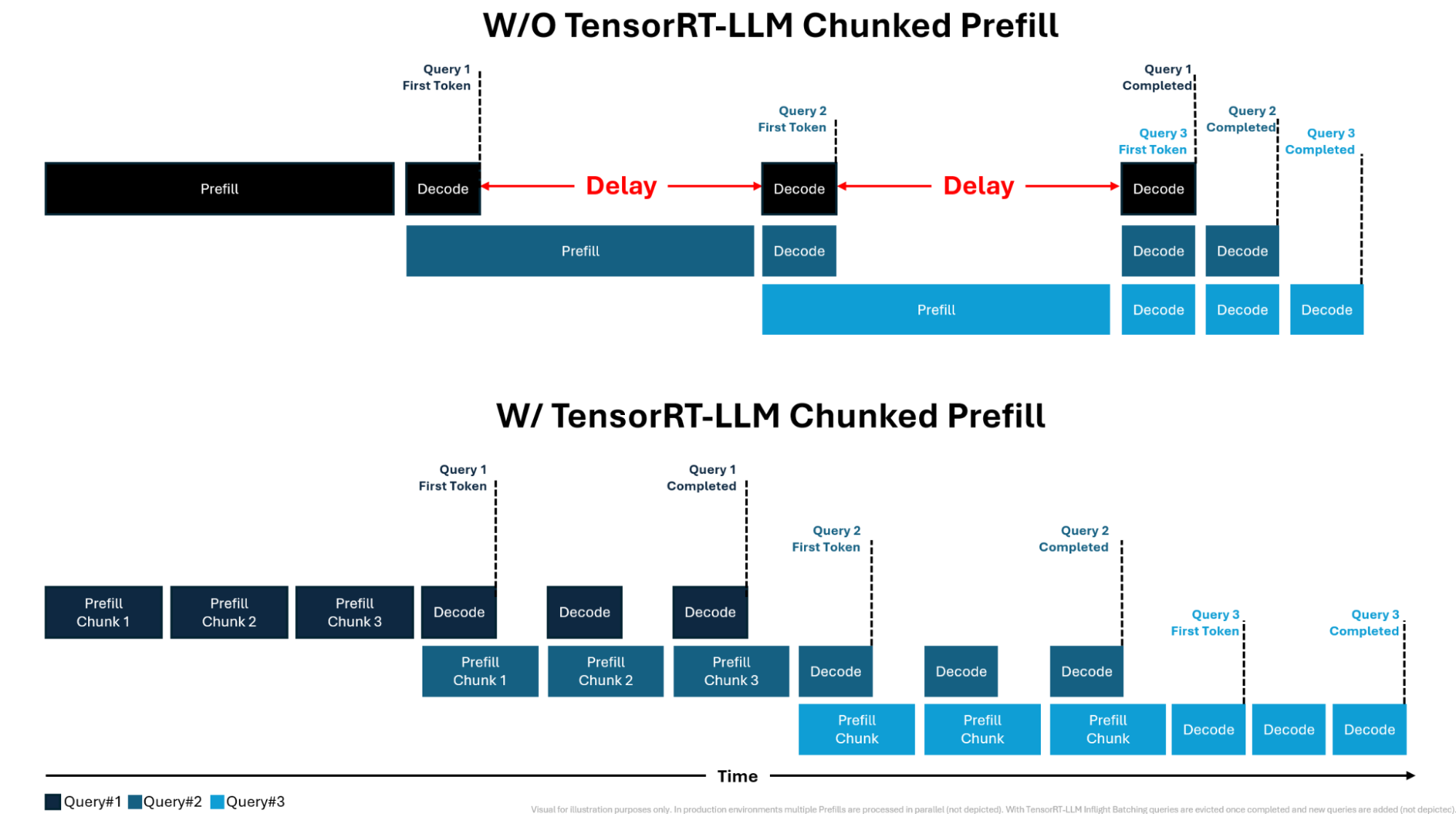
TensorRT-LLM supports in-flight batching where multiple requests are handled in parallel, enabling prefill and decode stage processing simultaneously. While more efficient than phased batching, in which decode requests are paused to process prefill requests, this approach can introduce latency as the decode phases are delayed until the prefill requests are completed. The top portion of Figure 1 illustrates this concept.
Balancing prefill and decode phases with chunked prefill
With TensorRT-LLM chunked prefill, the tokens are divided into smaller units, or chunks, for faster processing. This prevents the prefill phase from becoming a bottleneck, enables more parallelization with decode phase tokens, and increases GPU utilization. The bottom portion of Figure 1 illustrates this concept.
Additionally, using TensorRT-LLM chunked prefill enables GPU systems to handle longer contexts and higher concurrency levels. Since memory usage depends on the number of tokens processed during each iteration, using prefill chunks decouples memory consumption from the context length of incoming requests. The system can then process larger context lengths without increasing memory demands.
Simplifying TensorRT-LLM engine creation with dynamic chunk sizing
Figure 1 shows how chunk size can impact user interactivity and overall system throughput, requiring a trade-off based on the desired user experience and available GPU resources. Using a large chunk size lowers the number of iterations required to process prefill sequences, reducing time to first token (TTFT).
However, it also increases the time taken to complete the decode phase of ongoing requests, increasing query completion time and reducing output tokens per second (TPS). Finding the right balance can sometimes be time-consuming for developers. TensorRT-LLM deploys dynamic chunk sizing, providing ideal recommendations for the user based on GPU utilization metrics.
An additional advantage of dynamic prefill chunk sizing is the simplification of the TensorRT-LLM engine build process. In the past, developers had to supply a maximum input sequence length from which activation buffers were computed during engine build time. To ensure the activation buffers could handle the most complex user queries, developers were required to set the maximum sequence length expected for their use case. This approach optimized GPU resources for outlier and worst-case scenarios, leading to inefficient memory usage.
With dynamic prefill chunk sizing developers no longer need to specify the maximum input length manually. Instead, activation buffer sizes are automatically determined by the chunk size, which is configured by TensorRT-LLM. This eliminates manual configuration and leads to more efficient memory usage during execution.
Getting started with TensorRT-LLM chunked prefills
Using TensorRT-LLM chunked prefill significantly improves both system performance and utilization. Breaking down the traditionally sequential prefill phase into smaller, more manageable chunks, enables better parallelization, with the decode phase, reducing bottlenecks and accelerating query completion.
The dynamic adjustment of chunk size also simplifies the TensorRT-LLM engine configuration process, eliminating the need for developers to manually set activation buffer sizes, which previously resulted in inefficient memory usage. Dynamic chunk sizing optimizes memory use and ensures that the system adapts seamlessly to varying LLM user demands.
Check out our GitHub documentation, to start using TensorRT-LLM chunked prefills. Learn more about NVIDIA AI Inference solutions and stay up-to-date with the latest AI inference performance updates.
