Modern AI workloads, ranging from large-scale training to real-time inference, demand dynamic access to powerful GPUs. However, Kubernetes environments have limited native support for GPU management, which leads to challenges such as inefficient GPU utilization, lack of workload prioritization and preemption, limited visibility into GPU consumption, and difficulty enforcing governance and quota policies across teams.
In containerized environments, orchestrating GPU resources effectively helps maximize performance and efficiency. NVIDIA Run:ai simplifies this process with intelligent GPU resource management, enabling organizations to scale AI workloads with speed, agility, and governance.
In this blog, we’ll explore how NVIDIA Run:ai, now generally available on the Microsoft Marketplace, helps organizations streamline AI infrastructure on Azure. You’ll learn how it optimizes GPU utilization, enforces governance and quotas, and dynamically schedules AI workloads across teams and projects. We’ll also cover its seamless integration with Azure Kubernetes Service, support for hybrid cloud environments, and the tools it provides for managing clusters, node pools, and the full AI lifecycle. By the end, you’ll see how NVIDIA Run:ai simplifies AI orchestration, boosts performance, and enables scalable, cost-efficient AI operations.
Managing AI workloads with NVIDIA Run:ai
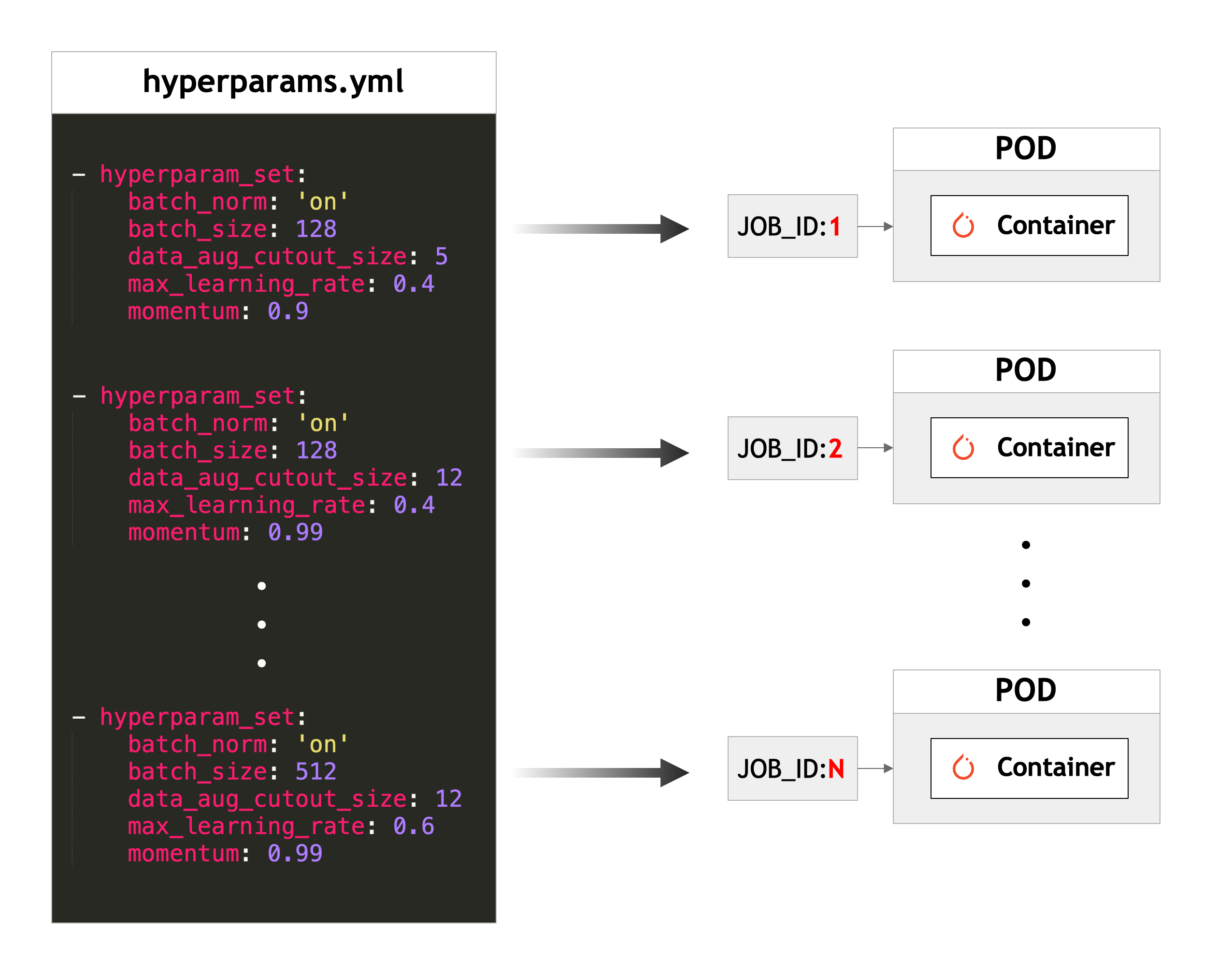
NVIDIA Run:ai offers a Kubernetes-native AI orchestration platform designed specifically for managing AI and machine-learning workloads. It provides a flexible layer that enables dynamic, policy-based scheduling of GPU resources across teams and workloads. This platform optimizes GPU utilization while enforcing governance, quotas, and workload prioritization.
Key capabilities include:
- Fractional GPU allocation: Share a single GPU across multiple inference jobs or development environments, improving utilization.
- Dynamic scheduling: Allocate full or fractional GPUs based on job priority, queueing, and availability.
- Workload aware orchestration: Differentiate scheduling policies for training, tuning, and inference workloads to maximize efficiency.
- Team based quotas and isolation: Guarantee GPU resources for teams or projects using fairshare or guaranteed quotas.
- Unified AI infrastructure: Centralized orchestration simplifies management across hybrid and multi-cloud environments.
How NVIDIA Run:ai works on Azure
NVIDIA Run:ai integrates seamlessly with Microsoft Azure’s GPU-accelerated virtual machine (VM) families, optimizing performance and simplifying the management of AI workloads.
Azure offers a broad selection of GPU-enabled VM families tailored to distinct needs: the NC-family, optimized for compute-intensive and high-performance computing (HPC) tasks; the ND-family, purpose-built for deep learning and AI research; the NG-family, designed for cloud gaming and remote desktop experiences; and the NV-family, focused on visualization, rendering, and virtual desktop workloads. Together, these GPU-powered families provide the flexibility and performance required to accelerate innovation across AI, graphics, and simulation workloads.
These VMs leverage NVIDIA GPUs, including the T4, A10, A100, and H100, H200 and GB200 Grace Blackwell Superchip. Many of these VMs are equipped with high-speed NVIDIA Quantum InfiniBand networking to deliver the low-latency, high-throughput performance required for advanced AI and deep-learning applications.
On the software side, NVIDIA Run:ai tightly integrates with Azure’s cloud infrastructure to provide a seamless experience for AI workloads. NVIDIA Run:ai leverages Azure Kubernetes Service (AKS) to orchestrate and virtualize GPU resources efficiently across diverse AI projects.
Additionally, NVIDIA Run:ai works with Azure Blob Storage to handle large datasets and model storage, facilitating smooth data access and transfer between on-premises and cloud resources. This close integration allows organizations to maximize GPU utilization while taking full advantage of Azure’s security and storage capabilities.
Want a visual walkthrough? Watch the demo video for a step-by-step guide to deploying NVIDIA Run:ai on Microsoft Azure.
Running AI workloads with Azure Kubernetes Service (AKS)
Azure Kubernetes Service (AKS) provides a managed Kubernetes environment that simplifies cluster management and scaling. NVIDIA Run:ai enhances AKS by adding an intelligent orchestration layer that dynamically manages GPU resources.
With NVIDIA Run:ai on AKS, AI workloads are scheduled based on real-time priorities and resource availability. This reduces idle GPU time and maximizes throughput by allowing multiple workloads to share GPUs efficiently. It also supports multi-node and multi-GPU training jobs, enabling enterprises to scale their AI pipelines seamlessly.
Teams can use namespaces and quota policies within AKS to isolate workloads, ensuring fair access and governance. Keep reading for tips on getting started.
Supporting hybrid infrastructure for today’s businesses
As organizations grow and AI workloads become more complex, many companies are adopting hybrid strategies that combine on-premises data centers with cloud platforms like Azure. This approach allows businesses to keep sensitive workloads local while leveraging the cloud’s scalability and flexibility for other tasks. Effectively managing resources across these environments is crucial to balancing performance, cost, and control.
Companies like Deloitte and Dell Technologies have observed that blending local infrastructure with cloud resources using a hybrid approach with NVIDIA Run:ai improves GPU utilization and enables smoother sharing of compute capacity across on-site and cloud environments. Similarly, institutions like the Johns Hopkins University Applied Physics Laboratory are using NVIDIA Run:ai, running workloads both on-premise and on Azure, to scale their experiments more efficiently, reduce wait times for GPU resources, and enable faster iteration while maintaining control over sensitive data and specialized tools critical for their work.
Get started on Microsoft Marketplace
NVIDIA Run:ai is available as a private offer on Microsoft Marketplace. The private listing ensures flexible deployment, custom licensing, and seamless integration into your existing enterprise agreement. To request a private offer:
- Visit NVIDIA Run:ai and select “Get Started.”
- Complete the “Contact Us About NVIDIA Run:ai” form.
- An NVIDIA representative will be in touch with you to create a tailored private offer.
- Once the offer has been accepted, you can connect your AKS cluster to NVIDIA Run:ai by following these steps:
- Create an Azure AKS cluster using the instructions provided in the AKS documentation.
- Install the NVIDIA Run:ai control plane.
- Install the NVIDIA Run:ai cluster.
- Access the NVIDIA Run:ai user interface (UI) using your fully qualified domain name and verify that the cluster status shows “Connected.”
Getting started with NVIDIA Run:ai on Azure
Once deployed on your AKS cluster, NVIDIA Run:ai provides a clear and comprehensive overview of all your GPU resources. The dashboard offers real-time insights into cluster health, including GPU availability, active workloads, and pending tasks. For example, a cluster with four nodes, each hosting eight GPUs, lets you instantly see which GPUs are idle or in use.

Once your AKS cluster is connected to the NVIDIA Run:ai control plane, you can access a unified view of all nodes, including CPU and GPU worker nodes. NVIDIA Run:ai supports heterogeneous GPU environments, enabling management of different GPU types such as A100 and H100 within the same cluster.

Optimizing GPU resources across clusters and teams
NVIDIA Run:ai allows you to group similar nodes into node pools, enabling refined, contextual based scheduling of workloads. This grouping ensures that tasks are matched with the most appropriate GPU or machine type. Node pools can also align with Azure scale sets, dynamically adjusting as you add or remove nodes—providing the flexibility your workloads demand.

Allocate GPU resources across teams using projects and quotas to optimize utilization. NVIDIA Run:ai guarantees baseline GPU quotas for each team, such as Teams A, B, and C (as shown in Figure 5 below), while allowing some workloads to burst beyond these limits when resources are available. The scheduler fairly preempts workloads when necessary to ensure guaranteed resource access.

Supporting the full AI lifecycle
NVIDIA Run:ai orchestrates workloads across the entire AI lifecycle, from interactive Jupyter notebooks to single-node and multi-node training jobs, as well as inference workloads. You can run popular frameworks like PyTorch Elastic on dedicated GPU pools or deploy models from Hugging Face and NVIDIA NGC containers natively on the platform. NVIDIA Run:ai also supports NVIDIA Dynamo for dynamic, distributed inference, enabling efficient resource utilization and scalable deployment of AI models across multiple GPUs and nodes.

NVIDIA Run:ai provides detailed usage analytics over various time frames, enabling chargeback or showback to different teams or business units. These insights empower IT and management teams to make informed decisions on scaling GPU infrastructure, ensuring optimal performance and cost-efficiency.

Conclusion
As AI adoption grows, efficient GPU management becomes critical. NVIDIA Run:ai on Azure offers a powerful orchestration platform that simplifies GPU resource management and accelerates AI innovation.
By combining NVIDIA Run:ai’s intelligent scheduling with Azure’s scalable GPU infrastructure and AI tools, organizations gain a unified, enterprise-ready solution that drives productivity and cost efficiency.
Explore NVIDIA Run:ai on Microsoft Marketplace to experience seamless AI infrastructure management and accelerate your AI journey.