As large language models (LLMs) power more agentic systems capable of performing autonomous actions, tool use, and reasoning, enterprises are drawn to their flexibility and low inference costs. This growing autonomy elevates risks, introducing goal misalignment, prompt injection, unintended behaviors, and reduced human oversight, making the incorporation of robust safety measures paramount.
In addition, fragmented risk postures with dynamic regulatory shifts escalate liability. Trust considerations introduce unknown risks such as hallucinations, prompt injections, data leakage, and offensive model responses that can undermine the security, privacy, trust, and compliance goals of an organization. These factors collectively impede the use of open models to power enterprise AI agents.
This post introduces the NVIDIA AI safety recipe, which hardens every stage of the AI lifecycle through NVIDIA open datasets, evaluation techniques, and post-training recipes. At inference time, NVIDIA NeMo Guardrails help address emerging risks, such as adversarial prompting to bypass content moderation, prompt injection attacks, and compliance violations.
This holistic approach empowers policy managers, risk owners such as CISOs and CIOs, and AI researchers to proactively manage safety threats, enforce enterprise policies, and confidently scale agentic AI applications responsibly.
Why do agentic workflows need a safety recipe?
Advanced open-weight models don’t always align with a company’s safety policies, and evolving environments introduce risks that outpace the capabilities of traditional safeguards like content filters and benchmarks. This may leave AI systems exposed to advanced prompt injection attacks due to a lack of continuous, policy-aware monitoring.
The agentic AI safety recipe provides a comprehensive, enterprise-grade framework that enables organizations to build, deploy, and operate AI systems that are trustworthy and aligned with internal policies and external regulatory demands.
Key benefits include:
- Evaluation: Ability to test and measure against defined business policies and risk thresholds in production models and infrastructure.
- End-to-end AI safety software stack: Core building blocks for enterprise AI systems enable monitoring and enforcement of safety policies throughout the AI lifecycle.
- Trusted data compliance: Access to open-licensed safety training datasets to build transparent and reliable AI systems.
- State-of-the-art risk mitigation: Techniques that offer systematic safety across critical dimensions such as:
- Content moderation: Tackling content safety, including mitigating violent, sexual, or harassing content.
- Security: Protecting against jailbreak and prompt injection attacks by improving system resilience to manipulative prompts like Do Anything Now (DAN) that attempt to extract harmful information.
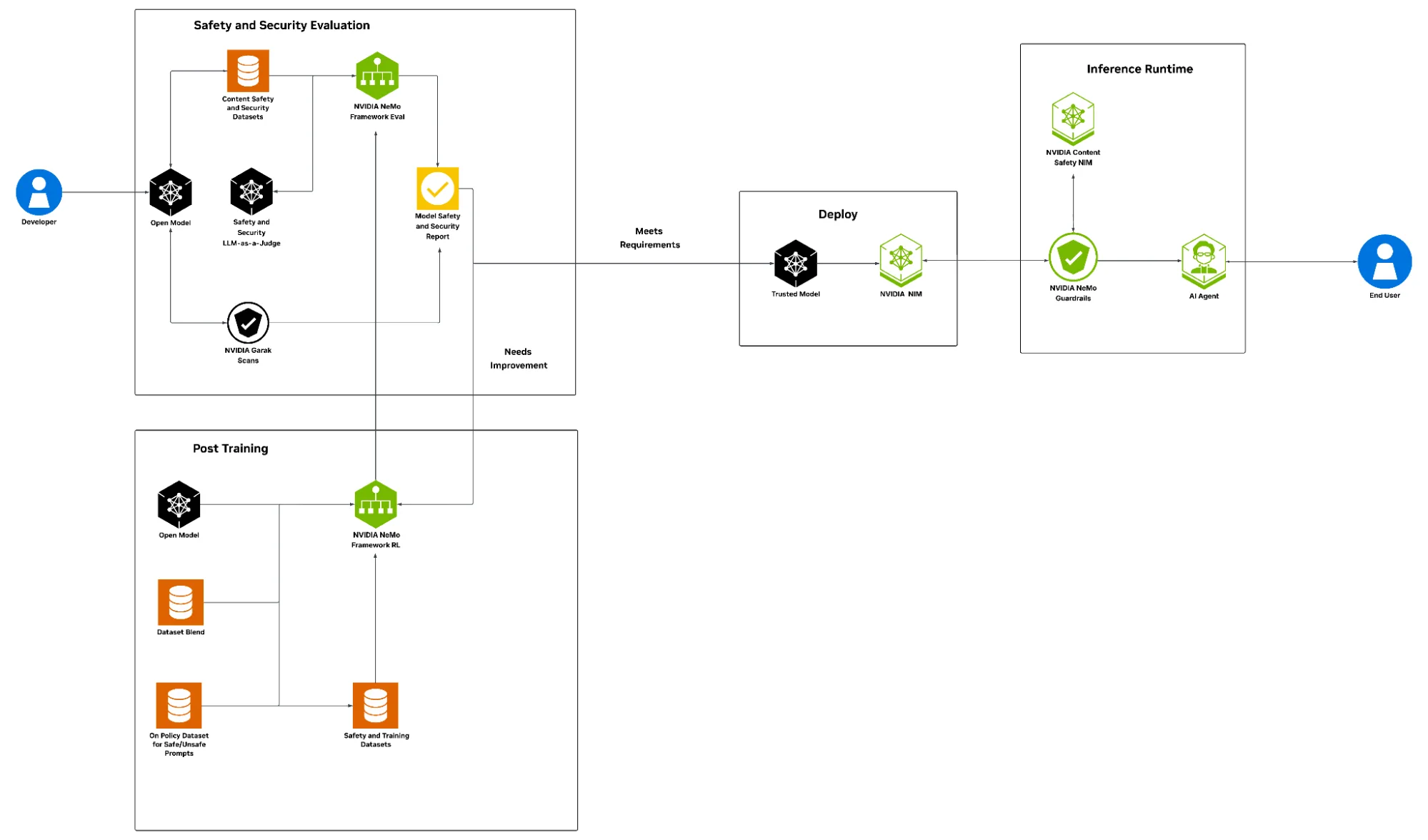
Apply defense at build, deploy, and run
During the build phase, model evaluation, and alignment are crucial steps to ensure that the model’s outputs align with enterprise-specific purpose, security, trust, users’ privacy expectations, and regulatory compliance standards. NVIDIA provides a set of evaluation tools, such as NVIDIA NeMo framework model evaluation using open datasets and content moderator models.
Nemotron Content Safety Dataset v2 with the Llama Nemotron Safety Guard v2 model and WildGuardMix Dataset with the AllenAI WildGuard model rigorously screen for harmful outputs, reinforcing content integrity and alignment with enterprise policies. In addition, the garak LLM vulnerability scanner probes for product security vulnerabilities to ensure robustness against adversarial prompts and jailbreak attempts, and tests the system for resilience.
The NeMo framework RL enables developers to apply state-of-the-art post-training techniques with supervised fine-tuning (SFT) and reinforcement learning (RL). It also provides open licensed datasets to build transparent and reliable AI systems. Users prepare on-policy dataset blends for safety and use them for post-training models.
Following the post-training, a thorough review of the model’s safety and security report is generated, ensuring that it conforms to enterprise-specific policies and adheres to required standards. A reevaluation of task-specific accuracy is also crucial at this stage. After validating that all evaluations meet the business and safety thresholds, the model can be considered trusted for deployment. Next, the LLM NIM microservice is used to deploy this trusted model for inference across multiple environments at scale.
In the real world, threats don’t end at post-training; there is always residual risk. Insights gained from the garak evaluation and post-training, in conjunction with NeMo Guardrails, provide ongoing, programmable safety and protection during inference runtime.
The Llama 3.1 Nemoguard 8B Content Safety NIM prevents biased or toxic outputs, the Llama 3.1 Nemoguard 8B Topic Control NIM ensures interactions remain within approved business or compliance domains, and the Nemoguard Jailbreak Detect NIM helps defend against malicious prompt engineering designed to bypass model safeguards.
Achieving leading model safety and security benchmarks
The industry-leading benchmarks highlight the safety and security gap between the baseline open-weight model and the same model enhanced through the post-training safety recipe.
The model evaluation for content safety was accomplished using a combination of content moderation benchmarks using the Nemotron Content Safety Dataset v2 test set, along with the Nemotron Safety Guard v2 judge model, and an external community benchmark using the WildGuardTest dataset with the WildGuard judge model.
Product safety improved from the baseline open-weights model of 88% to 94% by applying the NVIDIA AI safety recipe using the safety dataset, achieving a 6% improvement in content safety with no measurable accuracy degradation. This was accomplished using on-policy safety training, where responses are generated by the target model or a closely related one aligned with the same intended behavior.
Product security improved from the baseline open-weights model of 56% to 63%, a 7% improvement in security with no measurable accuracy loss, safeguarding against adversarial prompts, jailbreak attempts, and harmful content generation using garak to measure resilience score, evaluated as a percentage of probes that the model performs above average.
The NVIDIA AI safety recipe helps organizations confidently operationalize open models from development to deployment, enabling safeguards and responsible adoption of enterprise-grade agentic AI systems. Leading cybersecurity and AI safety companies are integrating these NVIDIA AI safety building blocks into their products and solutions.
Active Fence enables enterprises to safely deploy agents with real-time guardrails, ensuring safer generative AI interactions.
Cisco AI Defense integrates with NeMo to assess model vulnerabilities using algorithmic red teaming and provide complementary safety, security, and privacy guardrails for runtime applications.
CrowdStrike Falcon Cloud Security works with the NeMo training lifecycle, allowing customers to incorporate learnings from its ongoing prompt monitoring and threat intelligence data from models at runtime, into further model post-training.
Trend Micro is integrating with the NeMo model development pipeline to ensure model safety mechanisms scale reliably and securely across enterprise environments.


Get started improving your AI system safety
The safety recipe for agentic AI provides a structured reference designed to evaluate and align open models early, enabling increased safety, security, and compliant agentic workflows. The recipe is available as a Jupyter notebook to download or with a deploy on cloud launchable option using NVIDIA Brev from build.nvidia.com.
Acknowledgments
Thank you to all those who contributed to this post, including Yoshi Suhara, Prasoon Varshney, Ameya Sunil Mahabaleshwarkar, Zijia Chen, Makesh Narasimhan Sreedhar, Aishwarya Padmakumar, Pinky Xu, Negar Habibi, Joey Conway, Christopher Parisien, Erick Galinkin, Akshay Hazare, Jie Lou, Vinita Sharma, Vinay Raman, Shaona Ghosh, Katherine Luna, and Leon Derczynski.