Once you have built, trained, tweaked and tuned your deep learning model, you need an inference solution that you need to deploy to a datacenter or to the cloud, and you need to get the maximum possible performance. You may have heard that NVIDIA TensorRT can maximize inference performance on NVIDIA GPUs, but how do you get from your trained model to a TensorRT-based inference engine in your datacenter or in the cloud? The new TensorRT container can help you solve this problem.
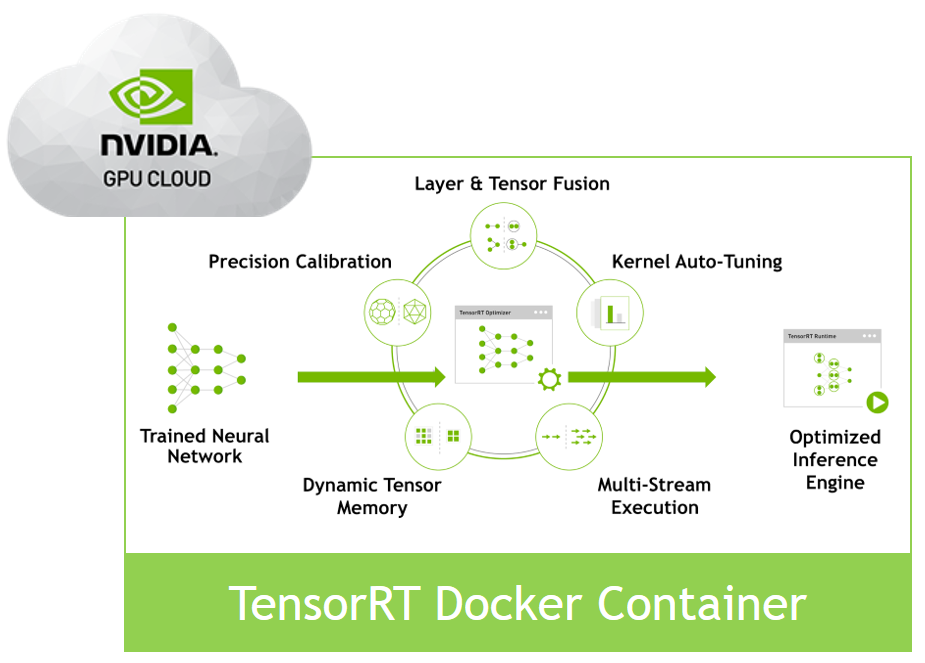
Based on NVIDIA Docker, the TensorRT container encapsulates all the libraries, executables and drivers you need to develop a TensorRT-based inference application. In just a few minutes you can go from nothing to having a local development environment for your inference solution that can also act as the basis for your own container-based datacenter or cloud deployment.
A new NVIDIA Developer Blog post introduces the TensorRT container and describes the simple REST server included in the container, which can act as a basis or inspiration for your own deployment solution.
RESTful Inference with the TensorRT Container and NVIDIA GPU Cloud

Dec 05, 2017
Discuss (0)
AI-Generated Summary
- To maximize inference performance on NVIDIA GPUs, you can use NVIDIA TensorRT to deploy your deep learning model to a datacenter or the cloud.
- The new TensorRT container, based on NVIDIA Docker, provides all necessary libraries, executables, and drivers to develop a TensorRT-based inference application.
- This container allows you to quickly set up a local development environment that can also serve as a basis for your own container-based datacenter or cloud deployment.
AI-generated content may summarize information incompletely. Verify important information. Learn more