Four years ago, a system known as PilotNet became the first NVIDIA system to steer an autonomous car along a roadway. This system represents a departure from the classical approach for self-driving in which the process is manually decomposed into a series of modules, each performing a different task. In contrast, PilotNet is a single deep neural network (DNN) that takes pixels as input and produces a desired vehicle trajectory as output.
As examples of what PilotNet can do, see the following images. Figure 1 shows PilotNet providing a trajectory on a snowy road where the lane markings are obscured and without the use of maps. PilotNet was able to drive here, though it would have been an extreme challenge for a handcrafted rules-based system. The green highlighted regions were most salient in determining the proper trajectory (yellow curve). Figure 2 shows still images from a test drive from North Carolina to New Jersey with greatly varying weather and lighting conditions.


What is PilotNet?
In PilotNet, there are no distinct internal modules connected by human-designed interfaces. Handcrafted interfaces ultimately limit performance by restricting information flow through the system. A learned approach, in combination with other artificial intelligence systems that add redundancy, ultimately leads to better overall performing systems. NVIDIA continues to conduct research toward that goal.
This post describes the PilotNet lane-keeping project, carried out over the past five years by the NVIDIA PilotNet group in Holmdel, New Jersey. This post presents a snapshot of the system status in mid-2020 and highlights some of the work done by the PilotNet group.
PilotNet’s core is a DNN that generates lane boundaries or the desired trajectory for a self-driving vehicle. PilotNet works downstream of systems that gather and preprocess live video of the road. A separate control system, when fed trajectories from PilotNet, can steer the vehicle. All systems run on the NVIDIA DRIVE AGX platform.
Using a single front-facing camera, the current version of PilotNet can steer an average of about 500 km on highways before a disengagement is required. This result was obtained without using lidar, radar or maps and is thus not directly comparable to most other published measurements. This post suggests that an approach like PilotNet can enhance overall safety when employed as a layer in systems that use additional sensors and maps, not just as a standalone system.
For more information, see The NVIDIA PilotNet Experiments (arXiv).
Evolution of PilotNet
The original PilotNet research system was created by NVIDIA in 2015–2016 and is described in some depth in End to End Learning for Self-Driving Cars. PilotNet drew on ideas developed by Dean Pomerleau (ALVINN) in 1989, and later by Yann LeCun, Urs Muller, Jan Ben, Eric Cosatto, and Beat Flepp (DAVE) in 2006. In both ALVINN and DAVE, recorded images of the view from the front of a vehicle were simultaneously logged along with the steering commands of a human driver creating input-target pairs. These pairs were then used for training a multi-layer neural network.
Having previously worked on the DAVE project, Muller and Flepp joined NVIDIA in February of 2015, forming the core of the PilotNet team. They realized that creating a DAVE-like system that ran on real cars on public roads entailed great technical risk and success was far from assured. Open questions included:
- Can an end-to-end approach scale to production?
- Does the training signal obtained by pairing human steering commands with video of the road ahead contain enough information to learn to steer a car autonomously?
- Can an end-to-end neural network outperform more traditional approaches?
The first step was to see if the DAVE concepts could be applied to on-road driving. With the addition of new hires and a pair of summer interns, driving data collection began.
In creating ALVINN, Pomerleau noted the need for augmenting the training set so that the autonomous system could drive even if the vehicle strayed beyond the range of the training data. Thus, the training set was augmented with transformed images that showed what the vehicle camera might record if it had drifted away from the center of the road. These images were coupled with a steering angle that would direct the vehicle back to the center.
To gather training data for PilotNet, three cameras were secured to a roof rack that was mounted on a data-collection car: on the left, on the right and centered. As the car drove, it simultaneously recorded video from the cameras as well as the steering wheel angle. Figure 3 shows early versions of the data-collection cars.

In PilotNet, the left and right cameras were used to provide augmented training data. These cameras recorded a view that was equivalent to that of the center camera as if the vehicle had been shifted left or right in the driving lane. In addition, all the camera images were viewpoint transformed over a range so that data was created corresponding to arbitrary shifts. These shifted images were paired with steering commands that would guide the vehicle back to the center of the lane.
Using data gathered in this way, a DNN was trained to output a steering angle when presented with an image of the road ahead. The system was tested and debugged using a Husky robot driving on a protected path as a surrogate for a full-size car.
In February 2016, a Lincoln MKZ was modified by the company AutonomouStuff for drive-by-wire operation. Also that month, the NVIDIA team moved to BellWorks, the new name for the former Bell Labs building in Holmdel where much of today’s machine learning theory and technology was created. The BellWorks complex features a garage for the MKZ as well as a few miles of private roads which are ideal for close-course testing of a self-driving car.
During the next month, the MKZ had cameras and an NVIDIA DRIVE PX board were installed along with some support electronics. A rudimentary self-driving system coupled PilotNet with the MKZ adaptive cruise control (ACC) for speed control. The car performed well on internal roads. Of course, as in all our tests, all relevant rules and regulations were observed, including having a safety driver who was always on the alert to take full control of the car if needed. The next day the car drove on Middletown Road, adjacent to BellWorks. This is a twisty, hilly road that runs for a few miles and at the time was poorly paved. Again, the car drove credibly. The next day the self-driving MKZ, with a few interventions, took team members to a nearby restaurant to celebrate. The system was first shown to the public at GTC San Jose in spring 2016 and later at GTC Europe in fall 2016 .
Over the next nine months, the PilotNet self-steering system was rapidly improved, culminating in a public demonstration on a closed course at the 2017 Consumer Electronics Show (CES) in Las Vegas.

Learning a trajectory
Early PilotNet produced a steering angle as output. While having the virtue of simplicity, this approach has some drawbacks. First, the steering angle does not uniquely determine the path followed by a real car. The actual path depends on factors such as the car dynamics, car geometry, road surface conditions, and transverse slope of the road (banks or domes). Ignoring these factors can prevent the vehicle from staying centered in its lane. In addition, just producing the current steering angle does not provide information about the likely course (intent) of the vehicle. Finally, a system that just produces steering is hard to integrate with an obstacle detection system.
To overcome these limitations, PilotNet now outputs a desired trajectory in a 3D coordinate frame relative to the car coordinate system. An independent controller then guides the vehicle along the trajectory. Following the trajectory, rather than just following a steering angle, allows PilotNet to have consistent behavior regardless of vehicle characteristics.
A bonus in using a trajectory as an output is that it facilitates fusing the output of PilotNet with information from other sources, such as maps or separate obstacle detection systems.
To train this newer PilotNet, it is necessary to create the desired target trajectory. It now uses the lane centerline, as determined by human labelers, as the ground truth desired trajectory. The human labelers also specify a centerline on roads where there are no painted lines, allowing PilotNet to predict the lane boundaries in these situations. The lane boundary output allows third parties to plan their own trajectories using the path perception provided by PilotNet.
Data collection
Creating a huge, varied corpus of clean data is one of the most critical and resource-intensive aspects encountered in creating a high-performance, learned self-driving system.
The early data collected was adequate for demonstrating a proof-of-concept. However, getting to a high-performance product required a massively scaled data-collection process. NVIDIA embarked on a large-scale data-collection campaign in 2017. This effort uses the NVIDIA DRIVE Hyperion reference architecture and included building a fleet of Ford Fusion and Ford Mondeo cars to collect data not only for PilotNet but also for the numerous other subsystems required for a complete driving solution.
Collected data included imagery from 12 automotive-grade cameras, returns from three lidars and eight radars, and GPS data, as well as CAN data such as steering angle and speed. Two NVIDIA DRIVE PX2 systems provided computing for the data-collection platform. Data was collected in the U.S., Japan and Europe with routes chosen to maximize diversity.
Training pipeline
Early PilotNet followed a typical convolutional net structure. More recent versions feature a modified ResNet structure.
PilotNet currently trains on millions of frames. All data manipulation is executed in parallel on one of the NVIDIA internal GPU compute clusters. To train PilotNet efficiently, we developed a comprehensive automated data pipeline. The pipeline lets us simultaneously explore different adjustments to network architecture, data selection, and image processing. In addition, the pipeline allows us to run experiments reproducibly. Much effort was expended to ensure deterministic behavior. Training a PilotNet network from scratch to peak driving performance takes about two weeks.
Testing the network: Augmented Resimulator
Different versions of PilotNet must be able to be evaluated and compared. The most direct test is real-world, on-road testing. However, real-world tests are time-consuming and not easily reproduced. Simulated test environments can help alleviate these issues, but simulations may not be representative of the real world. This is a particular concern for vision-based systems like PilotNet, where road textures, glare, or even chromatic aberration caused by different speeds of capturing the RGB channels in the camera can affect real-world driving. Producing a photorealistic simulation can be a challenge in and of itself.
In response to the challenges of creating realistic simulations, the Augmented Resimulator tool was developed. It’s a solution that allows for closed-loop testing like in a synthetic simulator but based on real sensor recordings instead of synthetic data. PilotNet uses viewpoint transforms to expand the training data to domains not recorded through human driving. The same strategy was used to generate testing environments from collected videos.
The basic approach is like video-replay, except that the system under test is free to control the car as if it were in a synthetic simulation. At each new state of simulation, sensor data is produced for the cameras through a viewpoint transform from the closest frame in the recording.
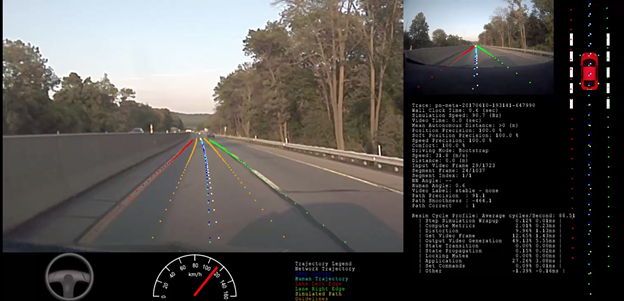
Figure 5 shows a screenshot of the Augmented Resimulator. The car icon in the upper right corner shows the position of the resimulated vehicle in its lane. The photographic image in the upper right is the original image captured while the data collection car was driven by a human. The large image on the left is the resimulated view. The dashed dark blue line indicates the ground truth lane center. The dashed light blue line represents the path driven by the human driver. The white dashes are the predicted path from the neural network. The yellow dashes are the tire positions from the resimulation. The red and green lines are the predicted lane edges.
What guides PilotNet?
The in-car monitor includes a saliency map that highlights in bright green the regions of the input image that are most salient in determining PilotNet’s output. For more information about the methodology in creating this visualization, see Explaining How a Deep Neural Network Trained with End-to-End Learning Steers a Car.
Figure 6 shows some examples of saliency maps.



In Figure 6, the top image shows a residential street with no lane markings. Here, the lower parts of the parked cars guide PilotNet. The second image from the top shows a busy intersection. PilotNet pays attention to painted lines in the direction of travel but ignores lines of the crosswalk that are nearly perpendicular to the direction of travel. In the bottom image, PilotNet is guided by the Bobcat front loader on the right and the curb on the left.
Multi-resolution image patches
Learning an accurate trajectory requires high-resolution data that provides enough information for PilotNet to see clearly at a distance. High-resolution cameras are used for this purpose. However, the image preprocessing steps, such as cropping and downsampling, significantly reduce resolution. In the early versions, the preprocessed image patch fed into PilotNet had a size of 209×65 pixels. One of the advantages of a small patch size is that it reduces the computing load, allowing PilotNet to drive with a high frame rate. But the resolution (~3.9 pixels per horizontal degree and ~ 5.9 pixels per vertical degree) at large distances is too low for the network to extract needed road features. At this resolution, the full moon would be only two pixels wide.
To increase the resolution at far distances while keeping a near constant computational load, we introduced a new method called “multi-resolution image patch.” This method significantly improves the PilotNet performance with modestly more computation. The basic idea is to linearly increase the horizontal and vertical resolutions (pixels per degree) from near to far distance with respect to the regular image patch. The method used here extracts a trapezoidal region from the original image and then reshapes it into a rectangular matrix.
The multi-resolution network (the network trained with the multi-resolution patch) provides improved lane trajectory accuracy. Figure 7 shows some example patches where the multi-resolution network predicts a better driving trajectory than the regular network.

The yellow lines are ground truth trajectories, and the orange lines are the network-predicted trajectories. In Figure 7, the multi-resolution PilotNet neural network achieves higher trajectory prediction accuracy. The multi-resolution patch is “distorted” with respect to the regular patch. However, this distortion is not a problem for PilotNet because the network is able to learn the relationship between the multi-resolution image space and 3D world space.
Conclusion
This post described a research project, PilotNet, in which a single DNN takes pixels as inputs and produces vehicle trajectories, all without the use of handcrafted rules or handcrafted task decomposition. PilotNet has given us insight into the nature of the immense AV challenges and potential solutions. Though not a standalone system, PilotNet can be incorporated as one component in much larger and complex production systems, providing diversity and redundancy for safety.
For further information about PilotNet, contact Urs Muller.
Acknowledgements
Thanks to all the current and former members of the PilotNet team: Mariusz Bojarski, Chenyi Chen, Joyjit Daw, Alperen Değirmenci, Joya Deri, Ben Firner, Beat Flepp, Sachin Gogri, Jesse Hong, Larry Jackel, Zhenhua Jia, BJ Lee, Bo Liu, Fei Liu, Urs Muller, Samuel Payne, Nischal Kota Nagendra Prasad, Artem Provodin, John Roach, Timur Rvachov, Neha Tadimeti, Jesper van Engelen, Haiguang Wen, Eric Yang, and Zongyi Yang.
