OpenACC gives scientists and researchers a simple and powerful way to accelerate scientific computing applications incrementally. The OpenACC API describes a collection of compiler directives to specify loops and regions of code in standard C, C++, and Fortran to be offloaded from a host CPU to an attached accelerator. OpenACC is designed for portability across operating systems, host CPUs, and a wide range of accelerators, including APUs, GPUs, and many-core coprocessors.

And starting today, with the PGI Compiler 15.10 release, OpenACC enables performance portability between accelerators and multicore CPUs. The new PGI Fortran, C and C++ compilers for the first time allow OpenACC-enabled source code to be compiled for parallel execution on either a multicore CPU or a GPU accelerator. This capability provides tremendous flexibility for programmers, enabling applications to take advantage of multiple system architectures with a single version of the source code.
“Our goal is to enable HPC developers to easily port applications across all major CPU and accelerator platforms with uniformly high performance using a common source code base,” said Douglas Miles, director of PGI Compilers & Tools at NVIDIA. “This capability will be particularly important in the race towards exascale computing in which there will be a variety of system architectures requiring a more flexible application programming approach.”
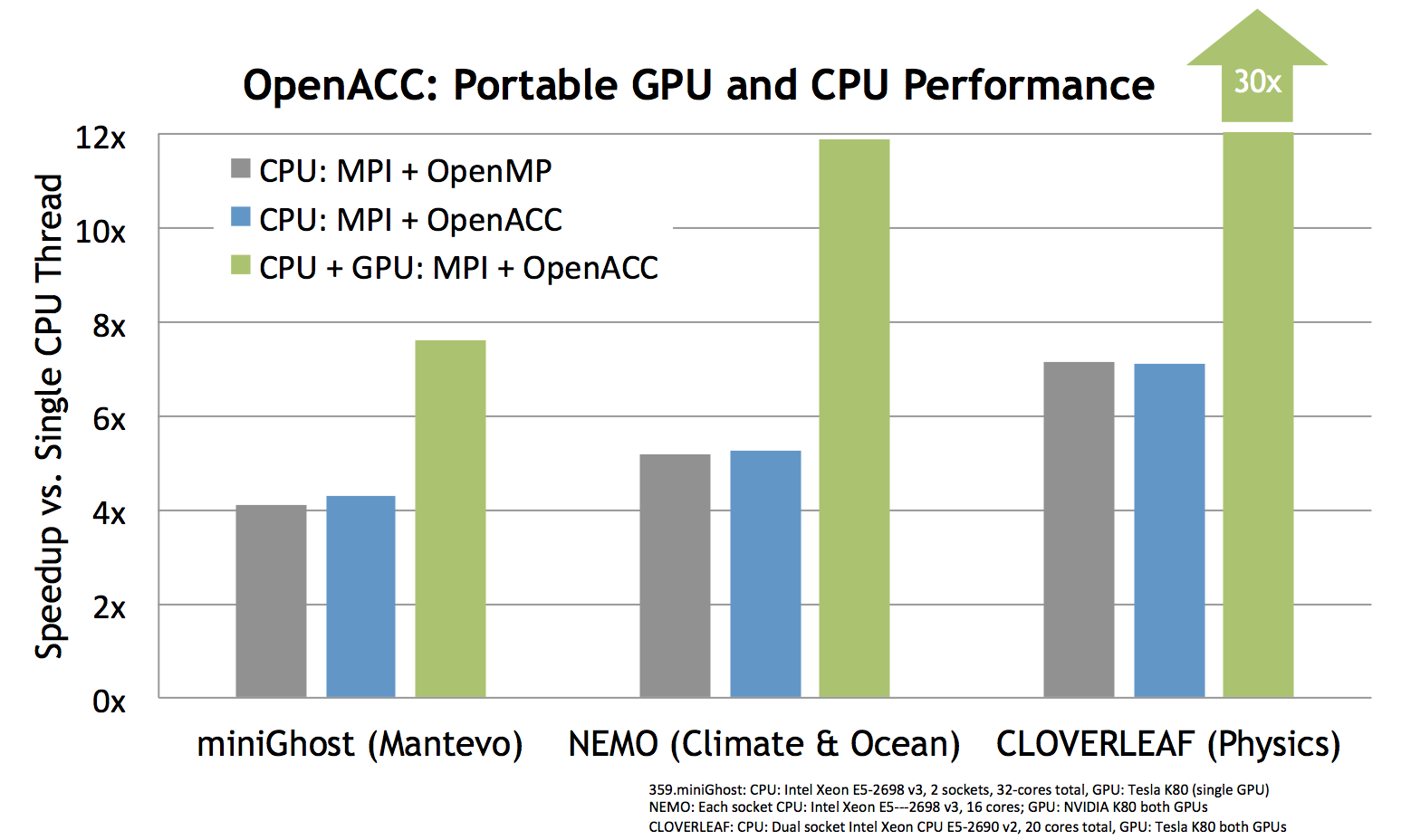 As the chart above shows, performance on multicore CPUs for HPC apps using MPI + OpenACC is equivalent to MPI + OpenMP code. Compiling and running the same code on a Tesla K80 GPU can provide large speedups.
As the chart above shows, performance on multicore CPUs for HPC apps using MPI + OpenACC is equivalent to MPI + OpenMP code. Compiling and running the same code on a Tesla K80 GPU can provide large speedups.
Key benefits of running OpenACC on multicore CPUs include:
- Effective utilization of all cores of a multicore CPU or multi-socket server for parallel execution
- Common programming model across CPUs and GPUs in Fortran, C, and C++
- Rapid exploitation of existing multicore parallelism in a program using the KERNELS directive, which enables incremental optimization for parallel execution
- Scalable performance across multicore CPUs and GPUs
PGI’s compiler roadmap, shown below, includes plans to support all of the compute processors that are likely to be viable building blocks for Exascale systems.

How to Compile OpenACC Applications for Multicore CPUs
Passing the flag -ta=multicore on the PGI compiler (pgcc, pgc++ or pgfortran) command line tells the compiler to generate parallel multicore code for OpenACC compute regions, instead of the default of generating parallel GPU kernels. The parallel multicore code will execute in much the same fashion as if you had used OpenMP omp parallel directives instead of OpenACC compute regions.
Adding -Minfo or -Minfo=accel will enable compiler feedback messages, giving details about the parallel code generated, as in the following.
ninvr:
59, Loop is parallelizable
Generating Multicore code
59, #pragma acc loop gang
pinvr:
90, Loop is parallelizable
Generating Multicore code
90, #pragma acc loop gang
You can control how many threads the program will use to run the parallel compute regions with the environment variable ACC_NUM_CORES. The default is to use all available cores on the system. For Linux targets, the runtime will launch as many threads as physical cores (not hyper-threaded logical cores). OpenACC gang-parallel loops run in parallel across the threads. If you have an OpenACC parallel construct with a num_gangs(200) clause, the runtime will take the minimum of the num_gangs argument and the number of cores on the system, and launch that many threads. That avoids the problem of launching hundreds or thousands of gangs, which makes sense on a GPU but which would overload a multicore CPU.
Single Programming Model, Portable High Performance
The goal of OpenACC is to have a single programming model that allows developers to write a single program that runs with high performance in parallel across a wide range of target systems. For the last few years, PGI has been developing and delivering OpenACC compilers targeting NVIDIA Tesla and AMD Radeon GPUs, but performance portability requires being able to run the same program with high performance in parallel on non-GPU targets, and in particular on multicore and manycore CPUs. So, the first reason to use OpenACC with -ta=multicore is if you have an application that you want to use on systems with GPUs, and on other systems without GPUs but with multicore CPUs. This allows you to develop your program once, without having to include compile-time conditionals (ifdefs) or special modules for each target with the increased development and maintenance cost.
Even if you are only interested in GPU-accelerated targets, you can do parallel OpenACC code development and testing on your multicore laptop or workstation without a GPU. This can separate algorithm development from GPU performance tuning. Debugging is often easier on the host than with a heterogeneous binary with both host and GPU code.
Working Through an Example: Please do Try This at Home!
To demonstrate the performance shown in the chart above, you can download the version of miniGhost used to generate the performance numbers from the PGI website.
To build the OpenMP version for execution on multicore, issue the following commands.
% make build_omp
…
mg_stencil_3d7pt:
197, Parallel region activated
200, Parallel loop activated with static block schedule
202, Generated 4 alternate versions of the loop
Generated vector sse code for the loop
Generated 5 prefetch instructions for the loop
213, Barrier
216, Parallel loop activated with static block schedule
218, Mem copy idiom, loop replaced by call to __c_mcopy8
224, Barrier
Parallel region terminated
…
% export MP_BIND=yes; make NCPUS=32 run_omp
env OMP_NUM_THREADS=32 time sh -x ./miniGhost.run ./miniGhost.omp >& miniGhost.omp.log
grep elapsed miniGhost.omp.log
8527.57user 5.96system 4:27.43elapsed 3190%CPU (0avgtext+0avgdata 6650048maxresident)k
This example is using the PGI OpenMP compiler, but the OpenMP time in the chart above uses the Intel OpenMP compiler. You’ll see about the same execution time using either of these two OpenMP compilers.
To build the OpenACC version for multicore using PGI, issue the following commands.
% make build_multicore
…
mg_stencil_3d7pt:
219, Loop is parallelizable
Generating Multicore code
219, !$acc loop gang
220, Loop is parallelizable
221, Loop is parallelizable
232, Loop is parallelizable
Generating Multicore code
232, !$acc loop gang
233, Loop is parallelizable
234, Loop is parallelizable
…
% export MP_BIND=yes; make NCPUS=32 run_multicore
env ACC_NUM_CORES=32 time sh -x ./miniGhost.run ./miniGhost.multi >& miniGhost.multi.log
grep elapsed miniGhost.multi.log
8006.06user 4.88system 4:14.04elapsed 3153%CPU (0avgtext+0avgdata 6652288maxresident)k
Finally, to build the OpenACC version for execution on an NVIDIA GPU using PGI, issue the following commands.
% make build_tesla
…
mg_stencil_3d7pt:
216, Generating present(work(:,:,:),grid(:,:,:))
219, Loop is parallelizable
220, Loop is parallelizable
221, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
220, !$acc loop gang, vector(2) ! blockidx%y threadidx%y
221, !$acc loop gang, vector(64) ! blockidx%x threadidx%x
232, Loop is parallelizable
233, Loop is parallelizable
234, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
233, !$acc loop gang ! blockidx%y
234, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
…
% make DEV_NUM=0 run_tesla
env ACC_DEVICE_NUM=0 time ./miniGhost.run ./miniGhost.tesla >& miniGhost.tesla.log
grep elapsed miniGhost.tesla.log
122.25user 30.12system 2:32.61elapsed 99%CPU (0avgtext+0avgdata 7542656maxresident)k
OpenACC Data Clauses on Multicore
In the OpenACC execution model, the multicore CPU is treated like an accelerator device that shares memory with the initial host thread. With a shared-memory device, most of the OpenACC data clauses (copy, copyin, copyout, create) are ignored, and the accelerator device (the parallel multicore) uses the same data as the initial host thread. Similarly, update directives and most OpenACC data API routines will not generate data allocation or movement. Other data clauses are still honored, such as private and reduction, which may require some dynamic memory allocation and data movement, but no more than the corresponding OpenMP data clauses.
When using OpenACC with a GPU, data gets copied from the system memory to device memory (and back). The user is responsible for keeping the two copies of data coherent, as needed. When using OpenACC on a multicore, there is only one copy of the data, so there is no coherence problem. However, the GPU OpenACC program can produce different results than a multicore OpenACC program if the program depends on the parallel compute regions updating a different copy of the data than the sequential initial host thread regions.
#pragma acc data create(a[0:n]) present(x[0:n],b[0:n])
{
// following loop executed on device
#pragma acc parallel loop
for(i=0;i<n;++i) a[i] = b[i];
// following loop executed on host
for(i=0;i<n;++i) a[i] = c[i];
// following loop executed on device
#pragma acc parallel loop
for(i=0;i<n;++i) x[i] = a[i];
...
}
On a GPU, the above code fragment allocates a copy of the array a on the device. It then fills in the device copy and the host copy with different values. The last loop will get the values from the device copy of a, so it’s equivalent to x[i]=b[i]; When compiled for a multicore, the first two loops are both executed on the CPU, the first with all multicore threads and the second with a single thread. Both loops update the same copy of a, and the last loop will be equivalent to x[i]=c[i].
Requirements and Limitations
PGI compilers on Linux, Windows, and Mac OS X support OpenACC for multicore. It works with any supported PGI target, including targets for which GPUs are not supported. This feature will work with any valid PGI license.
There are a few limitations in this release, which will be removed in future releases. In this release, the collapse clause is ignored, so only the outer loop is parallelized. The worker level of parallelism is ignored; PGI is still exploring how best to generate parallel code that includes gang, worker and vector parallelism. Also, no optimization or tuning of the loop code is done. For instance, when compiling for a GPU, the compiler will reorder loops to optimize array strides for the parallelism profile. None of this is implemented in the multicore target in this release. Finally, the vector level of parallelism is not being used to generate SIMD code in this release. PGI expects application performance will improve as these limitations are relaxed.
Conclusion
The PGI 15.10 release allows you to generate multicore CPU code from your OpenACC programs, enabling truly performance-portable parallel programs across CPUs and GPUs.
Register to download a free trial of the PGI 15.10 compilers and check it out for yourself. If you’re new to OpenACC, you can register for a free online OpenACC training course. To get started developing with OpenACC, try the NVIDIA OpenACC Toolkit, and read this introductory Parallel Forall post on OpenACC. A detailed article on OpenACC for CPUs with PGI 15.10 will be included in an upcoming PGInsider Newsletter from PGI.