Note: this post was co-written by Alex Şuhan and Todd Mostak of MapD.
At MapD our goal is to build the world’s fastest big data analytics and visualization platform that enables lag-free interactive exploration of multi-billion row datasets. MapD supports standard SQL queries as well as a visualization API that maps OpenGL primitives onto SQL result sets.
Although MapD is fast running on x86-64 CPUs, our real advantage stems from our ability to leverage the massive parallelism and memory bandwidth of GPUs. The most powerful GPU currently available is the NVIDIA Tesla K80 Accelerator, with up to 8.74 teraflops of compute performance and nearly 500 GB/sec of memory bandwidth. By supporting up to eight of these cards per server we see orders-of-magnitude better performance on standard data analytics tasks, enabling a user to visually filter and aggregate billions of rows in tens of milliseconds, all without indexing. The following Video shows the MapD dashboard, showing 750 million tweets animated in real time. Nothing in this demo is pre-computed or canned. Our big data visual analytics platform is running on 8 NVIDIA Tesla K40 GPUs on a single server to power the dashboard.
Fast hardware is only half of the story, so at MapD we have invested heavily into optimizing our code such that a wide range of analytic workloads run optimally on GPUs. In particular, we have worked hard so that common SQL analytic operations, such as filtering (WHERE) and GROUP BY, run as fast as possible. One of the biggest payoffs in this regard has been moving from the query interpreter that we used in our prototype to a JIT (Just-In-Time) compilation framework built on LLVM. LLVM allows us to transform query plans into architecture-independent intermediate code (LLVM IR) and then use any of the LLVM architecture-specific “backends” to compile that IR code for the needed target, such as NVIDIA GPUs, x64 CPUs, and ARM CPUs.
Query compilation has the following advantages over an interpreter:
- Since it is inefficient to evaluate a query plan for a single row at a time (in one “dispatch”), an interpreter requires the use of extra buffers to store the intermediate results of evaluating an expression. For example, to evaluate the expression
x*2+3, an interpreter-based query engine would first evaluatex*2for a number of rows, storing that to an intermediate buffer. The intermediate results stored in that buffer would then be read and summed with 3 to get the final result. Writing and reading these intermediate results to memory wastes memory bandwidth and/or valuable cache space. Compare this to a compiled query which can simply store the result of the first subexpression (x*2) into a register before computing the final result, allowing the cache to be used for other purposes, for example to create the hash table necessary for a query’sGROUP BYclause. This is related to loop fusion and kernel fusion compiler optimizations. -
An efficient interpreter would likely involve executing instructions represented by vectors of opcodes/byte-codes. Decoding the byte-code to get the required operations and then branching to the correct operation requires a significant amount of extra cycles. On the other hand, pre-generating compiled code for the query avoids the inefficiencies of this virtual machine approach.
-
Depending on the number and range of the columns used in a
GROUP BYclause, different hash strategies are optimal. Some of them rely on generating collision-free hash functions based on the range of the data, which is only known at runtime. Reproducing such functionality efficiently with an interpreter, particularly when the number and types of columns can vary, is difficult.
Of course, LLVM is not the only way to generate a JIT query compiler. Some databases employ source-to-source compilers to convert SQL to another source language like C++, which they then compile using regular compilers like gcc. We think that an LLVM-based compiler has significant advantages over a transpiler, including:
- Compilation times are much quicker using LLVM. We can compile our query plans in tens of milliseconds, whereas source-to-source compilation often requires multiple seconds to compile a plan. Since our platform is built for interactive data exploration, minimizing query compilation time is critical.
-
LLVM IR is quite portable over the various architectures we run on (GPU, x86-64, ARM). In contrast, source language generation requires more attention to syntactic differences, particularly in divergent cases like CUDA vs. OpenCL (both can be targeted with LLVM quite easily).
-
LLVM comes with built-in code validation APIs and tools. For example, comparison and arithmetic operations on integers will fail (with a useful error message) if the operand widths are different. Once a function is generated,
llvm::verifyFunctionperforms additional sanity checks, ensuring (among other things) that the control flow graph of our query is well-formed.
How MapD Uses NVVM
LLVM is powerful and battle-proven for CPUs, but our product focuses on GPUs. If we could use LLVM for GPU code compilation we’d get all the benefits we’ve mentioned while also being able to run on a CPU when needed. Fortunately, the NVIDIA Compiler SDK made this a reality long before we started to build our product.
The NVIDIA Compiler SDK includes libNVVM, an LLVM-based compiler backend and NVVM IR, a rather extensive subset of LLVM IR. Thanks to our choice of LLVM and libNVVM, our system runs on NVIDIA GPUs, GPU-less ultrabooks, and even on the 32-bit ARM CPU on the Jetson TK1, all using the same code base.
MapD does not need to directly generate all code. We offload some of the functionality to a runtime written in C++ whenever code generation would be tedious and error-prone without any performance benefits. This approach is a great fit for things like aggregate functions, handling arithmetic on columns with SQL null values, hash dictionaries and more. The LLVM based C++ compiler, clang, generates the corresponding LLVM IR, and we combine it with our explicitly generated IR.
As is always the case when compilation is involved, the time required to generate native code is an important consideration. An interactive system sees new queries all the time as the user refines them in search of insight. We’re able to keep code generation consistently under 30 ms for entirely new queries, which is good enough to be unnoticeable in the console, especially for massive datasets. However, for “mere billions” of rows, our UI is able to show smooth animations over multiple correlated charts. Since the actual execution is so fast in this case, 30 ms can matter a lot.
Fortunately, these queries are structurally identical and only differ in the value of literals as the filter window moves across the time range or the user selects the tail of a histogram. With caching in place, compilation time becomes a non-issue. We keep it simple and still generate the IR, then use it as a key in the native code cache. The LLVM API offers an easy way to serialize source level entities (functions in our case), shown below.
std::string serialize_function(const llvm::Function* f) {
std::stringstream ss;
llvm::raw_os_ostream os(ss);
f->print(os);
return ss.str();
}
Performance Measurements
Ideas are great in performance-focused systems, but the proof is in the pudding. As it turns out, MapD extracts a lot of performance out of GPUs.
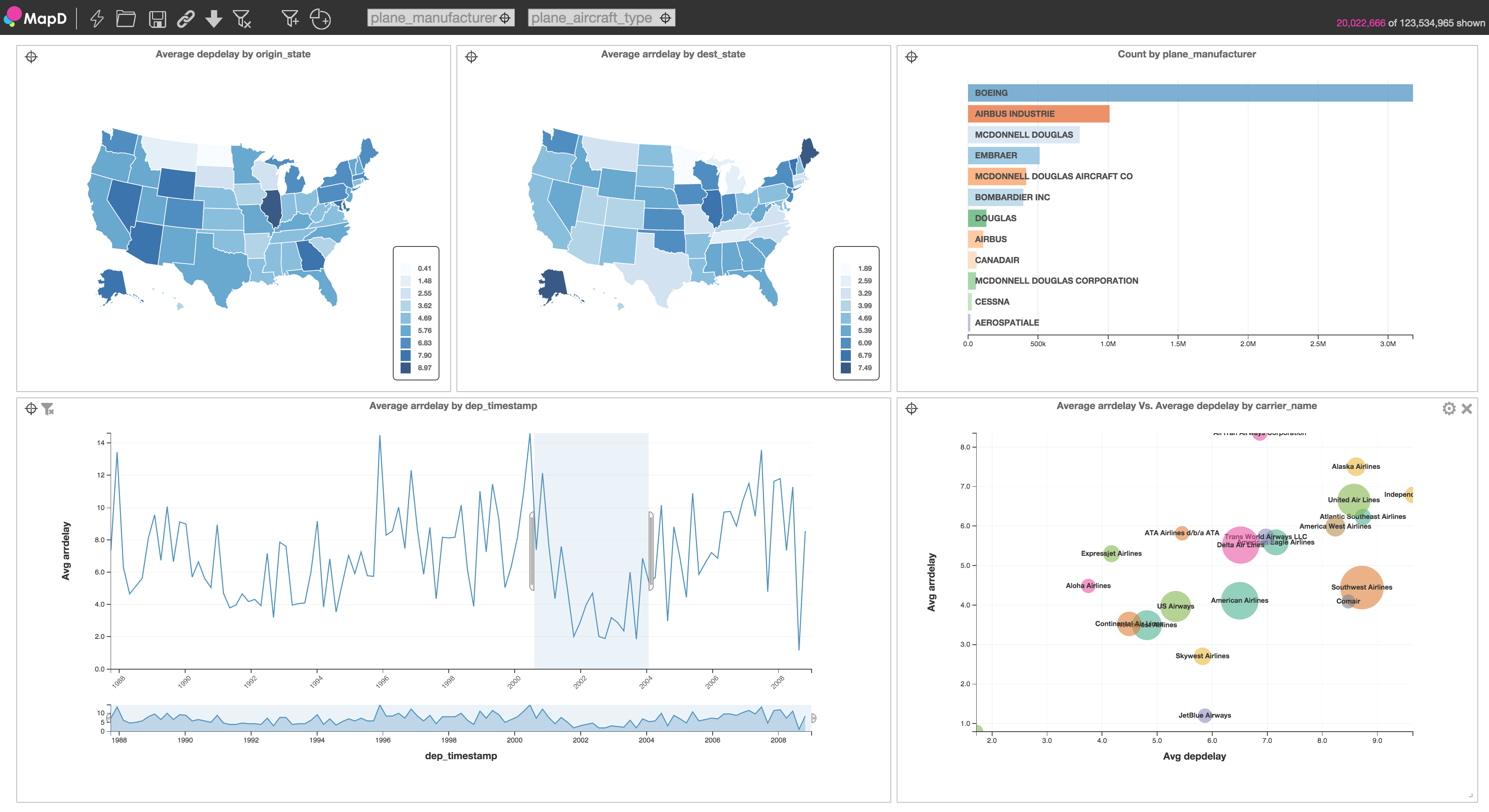
Queries using filter and aggregate routinely hit more than 80% of the available bandwidth. We’ve measured more than 240 GB/s on a single K40 (vs a theoretical max of 288GB/sec) for a filter and count query touching a single column. When grouping by a single column with 20 possible values and some skew (the carrier in the airline data set in Figure 1), MapD can only reach slightly more than 100 GB/s on K40. On the new Titan X GPU, based on the Maxwell architecture, we are able to get more than 200 GB/s on the same query, on a single card. Maxwell handles contention in shared memory atomics significantly better than the Kepler architecture, which explains this great result on skewed inputs. We’re looking forward to this feature being implemented on future generations of Tesla cards as well.
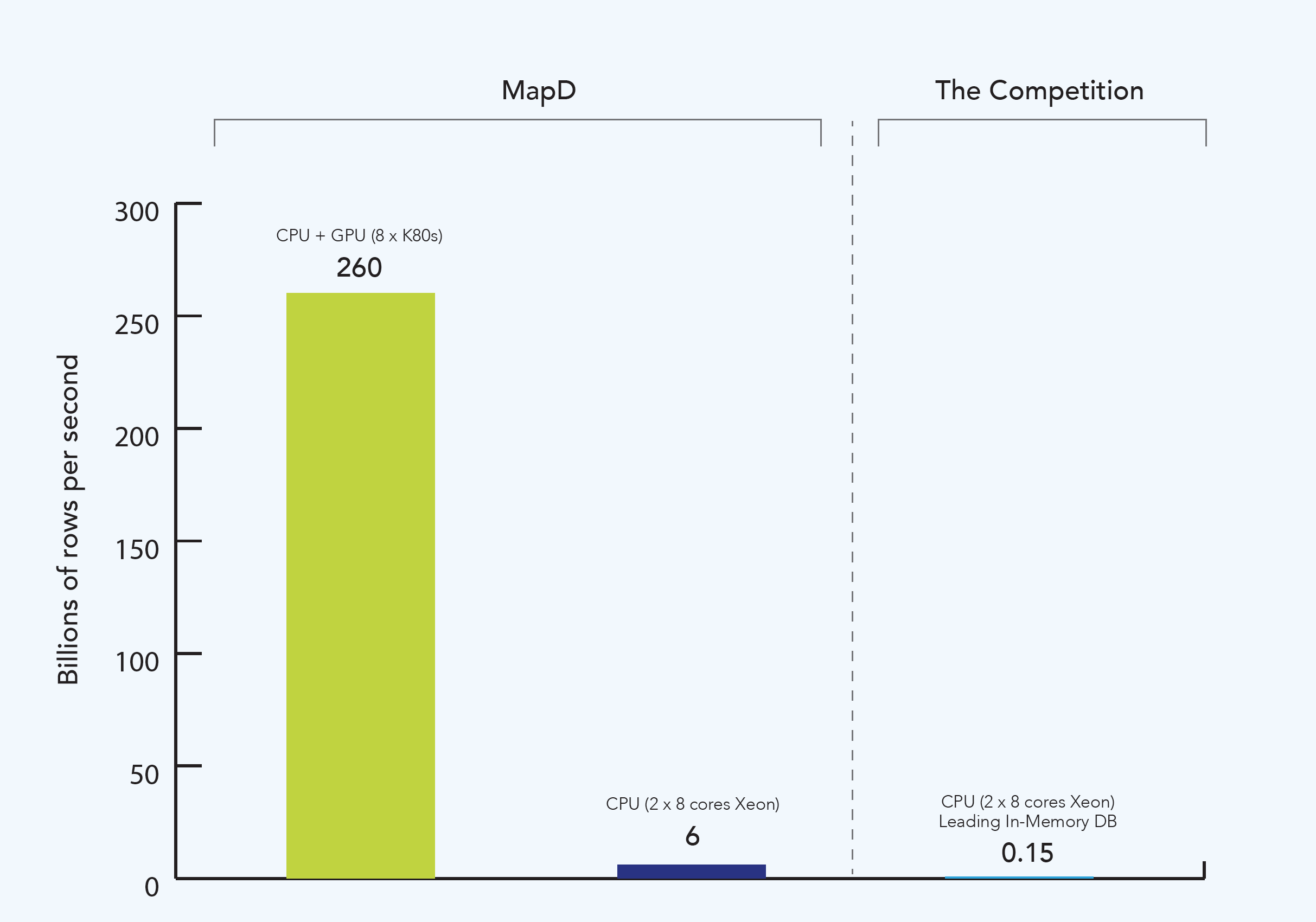
MapD is easily able to get a 40-50x speedup on a multi-GPU system, even when compared to our own code running on a high end dual-socket CPU system, and there are even queries for which the gap is two orders of magnitude (this is often code with lots of divisions, which tend to be slow on x86-64). Compared to other leading in-memory CPU-based databases, which typically use interpreters or source-to-source compilers, the speedup can easily be three orders of magnitude, as Figure 2 shows.
LLVM JIT Compilation for GPUs: Tips and Tricks
We’ve learned a lot about LLVM and JIT compilation for GPUs while building MapD’s interactive query engine, and we’d like to share some of that experience with you.
Most MapD runtime functions are marked as always_inline, which forces the LLVM AlwaysInliner optimization pass to inline them so that there is no function call overhead and increased scope for other optimization passes. For example, the following is a reasonable way of implementing a max aggregate.
extern "C" __attribute__((always_inline))
void agg_max(int64_t* agg, const int64_t val) {
*agg = std::max(*agg, val);
}
Note that the function is not marked as __device__ since this is not CUDA C++ code. Any explicit call to this function will be eventually inlined and the result can run unmodified on the GPU. Also, if agg points to a value allocated on the stack (as is the case for queries without GROUP BY clause), the PromoteMemoryToRegister pass will place it in a register for the inner loop of the query. The runtime functions which need GPU-specific implementations are part of a regular CUDA C++ library we can call from the query.
We’ve said that NVVM generates native code, but there actually is an additional step we haven’t discussed. From the IR we generate, NVVM generates PTX, which in turn is compiled to native code for the GPU. Especially if you’re bundling a CUDA C++ library with the generated code, like we do, caching the result of this last step is very important. Make sure the compute cache directory is writable by your application or else it will silently fail and recompile every time. The code snippet below shows how we bundle a library with the PTX we generate.
checkCudaErrors(cuLinkCreate(num_options, &option_keys[0],
&option_values[0], &link_state_));
if (!lib_path.empty()) {
// To create a static CUDA library:
// 1. nvcc -std=c++11 -arch=sm_30 --device-link
// -c [list of .cu files]
// 2. nvcc -std=c++11 -arch=sm_30
// -lib [list of .o files generated by step 1]
// -o [library_name.a]
checkCudaErrors(cuLinkAddFile(link_state_, CU_JIT_INPUT_LIBRARY,
lib_path.c_str(), num_options,
&option_keys[0], &option_values[0]));
}
checkCudaErrors(cuLinkAddData(link_state_, CU_JIT_INPUT_PTX,
static_cast<void*>(ptx),
strlen(ptx) + 1, 0, num_options,
&option_keys[0], &option_values[0]));
void* cubin;
size_t cubin_size;
checkCudaErrors(cuLinkComplete(link_state_, &cubin, &cubin_size));
checkCudaErrors(cuModuleLoadDataEx(&module_, cubin, num_options,
&option_keys[0], &option_values[0]));
checkCudaErrors(cuModuleGetFunction(&kernel_, module_, func_name.c_str()));
There is an upper bound for the number of registers a block can use, so the CU_JIT_THREADS_PER_BLOCK option should be set to the block size. Failing to do so can make the translation to native code fail. We’ve had this issue for queries with many projected columns and a lot of threads per block before setting this option.
Speaking of libraries, not all POSIX C functions are included in the CUDA C++ runtime libraries. In our case, we needed gmtime_r for the EXTRACT family of SQL functions. Fortunately, we’ve been able to port it from newlib and compile it with NVCC.
Just a word of caution: despite sharing the IR specification, NVVM and LLVM are ultimately different code-bases. Going with an older version of LLVM, preferably the one NVVM is based on, can help. We decided against that approach since the LLVM API offers a wide range of “IR surgery” features and we were able to fix up these mismatches, but your mileage may vary.
Also, unlike LLVM IR, unaligned loads are not allowed in NVVM IR. The address of a load must be a multiple of the size of the type; otherwise, the query would crash with an invalid memory access error on the GPU, even if the load is not annotated as aligned.
Try MapD Today!
Creating a SQL JIT for GPUs is just one of the many optimizations we’ve implemented to make MapD as fast as possible. If you’d like to learn more about MapD, please visit the MapD website, download our white paper, or read our blog.