Have you ever looked at your shopping list and tried to optimize your trip based on things like distance to store, price, and number of items you can buy at each store? The quest for a smarter shopping cart is never-ending, and the complexity of finding even a sub-optimal solution to this problem can quickly get out of hand. This is especially true of online shopping, which expands the set of fulfillment possibilities from local to national scale. Ideally, you could shop online for all items from your list and the website would do all the work to find you the most savings.
That is exactly what Jet.com does for you! Jet.com is an e-commerce company (acquired by Walmart in 2016) known for its innovative pricing engine that finds an optimal cart and the most savings for the customer in real time.
In this post I discuss how Jet tackles the fulfillment optimization problem using GPUs with F#, Azure and microservices. We implemented our solutions in F# via AleaGPU, a natural choice for coding CUDA solutions in .NET. I will also cover relevant aspects of our microservice architecture.
The Merchant Selection Problem
Jet.com’s provides value by finding efficiencies in the system and passing them through to customers in the form of lower prices. At the center of this is Jet’s smart merchant selection algorithm. When a customer orders several items at once they usually can be fulfilled by multiple merchants with different warehouses. The goal is to find the combination of merchants and warehouses that minimizes the total order cost, including shipment costs and commissions. The bigger the shopping cart, the higher the potential savings, but also the more time consuming the search for the optimal combination.
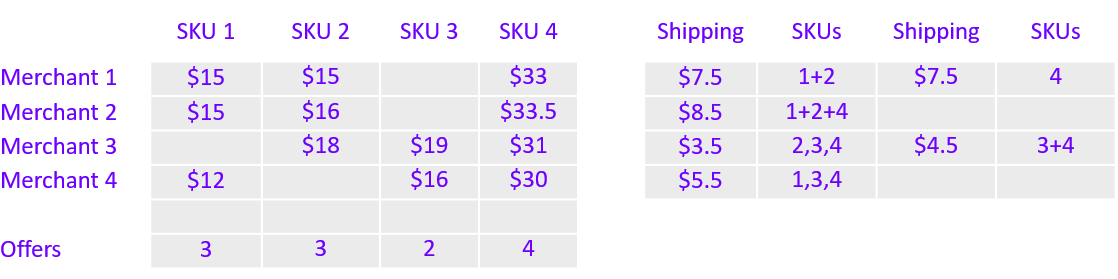
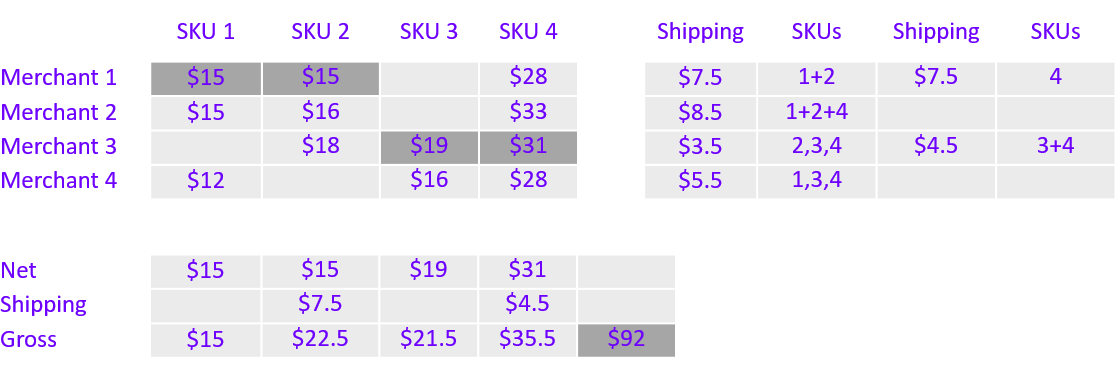
Take, for example, a cart of four items (retail SKUs, or “Stock Keeping Units”) and a local market of four merchants.
Figure 1 shows the merchant’s price for each of the four skus and the shipping cost by merchant for some possible fulfillment combinations those merchants can provide. The table of shipping costs shows the cost for either individual SKUs or multiple SKUs packaged together (delimited by a comma or a plus sign respectively). For example, the cost to ship any individual SKU from Merchant 3 is $3.5 however SKU 3 and SKU 4 can be shipped together for only $4.5.
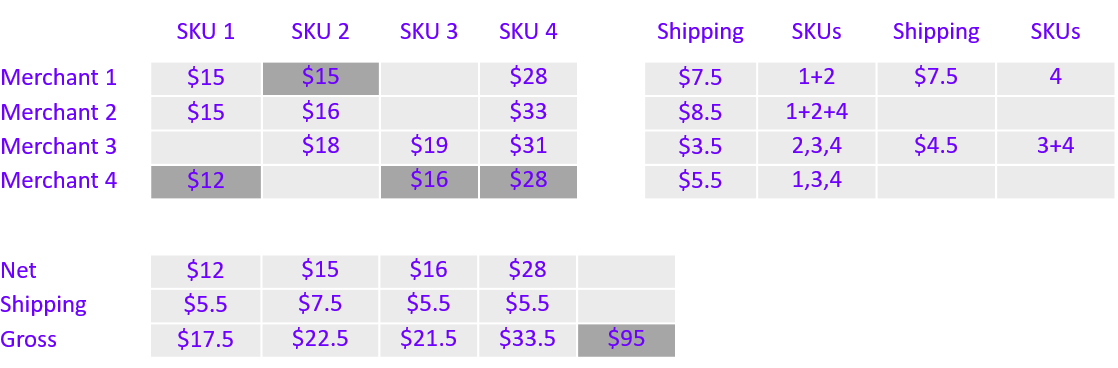
The naive approach of choosing the merchant with the cheapest offer for each SKU results in a total of $95 for the cart (Figure 2). This approach neglects shipping costs and fails to discover any savings from shipping multiple items from the same merchant.
For example, Merchant 2 can fulfill three of the 4 SKUs for only $8.5 in shipping costs, so fulfilling the order via Merchant 2 and Merchant 4 brings the total down to $94 (Figure 3). Is this the most optimal combination?
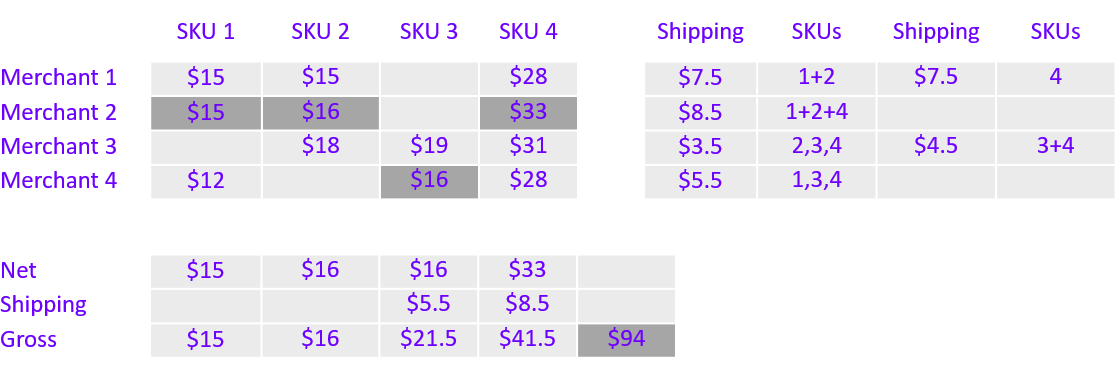
The only way to find the optimal combination (the most savings for the customer, as Figure 4 shows) is by pricing every one of the 72 combinations for this cart.
The Complexity of Full Search
Pricing every possible fulfillment combination to find the optimal solution is an exhaustive brute-force search of the entire solution space. The full search approach to the merchant selection problem is embarrassingly parallel: each enumerated fulfillment combination can be priced independently. This natural parallelism lead us to initially use the full search approach on the GPU, but it turns out that full search is prohibitive (even with GPU acceleration) due to the exponential complexity of the merchant selection problem. Since a genetic algorithm (discussed in the next section) does not guarantee a fully optimal solution, it’s important to use full search when possible. We developed a metric called the “full search year” which we use to measure the computation time required for merchant selection.
A full search year is the number of combinations that can be priced within a year. We use GPU full search year or CPU full search year to indicate the time required when running either implementation. Full search seconds, minutes, hours, and days are derived from full search year.
Cart Complexity, or Merchant selection complexity, is the total number of fulfillment combinations that must be priced in order to find the most optimal fulfillment and lowest price.
Cart Complexity = number of combinations = # offers for item 1 * # offers for item 2 * … * # offers for item k.
To illustrate both the complexity of the merchant selection problem and the application of the full search year metric, we dug through our logs to find a cart which timed out when a customer tried to place an order. These timeouts tend to occur most often when a large number of merchants that can fulfill each item, such as with electronics. Figure 5 shows an example in which the customer was ordering components to build a computer.
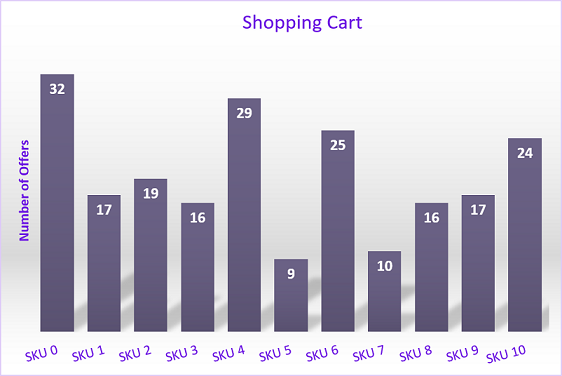
The chart in Figure 6 shows the number of offers for each of the 11 retail SKUs in the customer’s cart. The cart complexity is 321719162992510161724 = 70,442,237,952,000 = 1013.85 combinations. The time required to find the optimal fulfillment for this cart is 8.6 CPU full search years or 11 GPU full search days! This is well outside of our target response time of a few seconds. Given this constraint, the problem quickly grows larger than what can be handled by the GPU full search within the target time. We needed a better, more scalable solution.
A Genetic Algorithm
To address the scalability issues, we decided to apply genetic algorithms (GA) to solve the problem. Two important points to consider with the GA approach:
- GA can only find approximately optimal solutions.
- A standard GA will not work because our search space is astronomically large and we need a reliable approximate solution in near real-time.
Jet.com’s constraints on response time limit how long we can spend producing consecutive generations of the population. Moreover, since generation iteration is a serial process, we can’t reduce computation time by parallelizing iterations.
We used four methods to address these issues:
- Dramatically increasing the population size to reduce the number of iterations required for convergence.
- Improving the initial population by including merchant combinations which are likely to be good. For example, rather than starting with an initial population of fully randomized combinations, we include combinations in which single merchants fulfill multiple retail SKUs since this tends to reduce shipping costs in most cases.
- Identifying parts of the population which can be used to guide the behavior of mutation and crossover operators.
- Leveraging AI/ML to choose the appropriate configuration for the GA.
The fourth method was non-trivial and introduced some of its own unique challenges which I hope to cover in more detail in a future blog post.
Implementation
I’m going to take you through some implementation details of the GPU full search algorithm (GPUFS) but first I want to briefly discuss algorithm selection. There are three merchant selection algorithms we can use : the CPU implementation, the GPU full search, and the GPU genetic algorithm (GPUGA). Each approach has its own strengths and weaknesses depending on the situation.
The implementation uses a decision function to choose between the three algorithms based on cart complexity and load. For example, consider the case of a single item checkout. Pricing a single-item cart on the GPU would take longer than pricing it on the CPU due to the cost of data transfer to the GPU. For more complex carts, if we can perform merchant selection within an acceptable timeframe using GPUFS we should choose it over GPUGA, since GA’s do not guarantee optimal results.
Choosing the best algorithm for the task is unfortunately not as simple as “if cart = small then do CPUFS elif cart = big then do GPUFS elif cart = huge then do GPUGA.” We needed a smart decision function to address these issues so we used machine learning to train a model based on cart features and used it to improve the function’s results. In order to train this model appropriately and employ multiple algorithms we had to develop a way to validate, appraise, and compare multiple algorithms on production data. I hope to share details of this work in future blog posts as they are out of scope of our current discussion. For now, let’s focus on the details of the GPUFS algorithm and the microservice that invokes it.
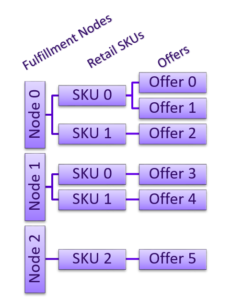
First I need to explain two core concepts: local market supply and allocation. The local market supply is an array of mappings of fulfillment nodes to offers for each retail SKU in a cart. Figure 6 shows an example LocalMarketSupply data structure; you can see (for example) that Node 0 can fulfill SKU 0 from two possible offers.
The goal of the search algorithms is to find the cheapest fulfillment combination for the items in the customer’s cart. Consider a scenario in which a customer initiates a checkout with three items: SKU 0, SKU 1, and SKU 2. Jet.com’s microservice queries a database to find all offers for these three retail SKUs and then uses this information to build the LocalMarketSupply structure for the cart.
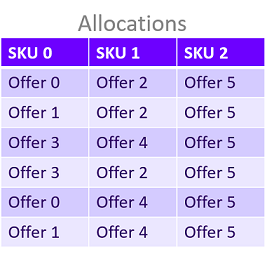
The actual search space of the merchant selection problem is the set of all possible fulfillment combinations, which we refer to as allocations. A single allocation is an array of integers representing a combination of fulfillment options for the set of retail SKUs being priced. The indices of this array represents the IDs of the retail SKUs, and the value at each index is the offer ID chosen for that retail SKU.
\(A = [o_{r_0} \ldots o_{r_i}]\)
Therefore the set of allocations for the local market supply defined in Figure 6 would resemble the table in Figure 7.
Full Search
Jet.com’s full search implementation is straightforward. One kernel function processes all possible allocations, pricing each one and performing a min reduction to find the cheapest.
To aid explanation I’ll divide the full search implementation into two conceptual parts: search and pricing. The search part essentially refers to the kernel and the code responsible for finding the cheapest allocation. The pricing part then refers to code that actually prices an individual allocation. Let’s look at the search part first.
The kernel has a main while loop that follows a familiar strided access pattern.
// Because we need to repeatedly refer to our local market supply to
// determine which retail skus a fulfillment node can fulfill we store the
// compressed supply in shared memory.
let shared = __shared__.ExternArray(8) |> __address_of_array
let supply = CompressedSupply.LoadToShared(supply, shared.Reinterpret(), numRetailSkus)
let mutable minAllocation = -1L
let mutable minPrice = RealMax
let start = blockIdx.x * blockDim.x + threadIdx.x
let stride = gridDim.x * blockDim.x
let mutable localLinear = int64 start
while localLinear < numElements do
let allocation = localLinear + linearStart
let price = price allocation
if price < minPrice then
minPrice <- price
minAllocation <- allocation
localLinear <- localLinear + (int64 stride)
We perform a warp reduce to find the best price/allocation for each warp.
let mutable pricedAllocation = PricedAllocation(minPrice, minAllocation) for i = 0 to Util.WarpSizeLog - 1 do let offset = 1 <<< i let peer = DeviceFunction.ShuffleDown(pricedAllocation, offset, Util.WarpSize) pricedAllocation // Synchronize threads because we reuse the shared memory __syncthreads()
Then we prepare for a block reduce by adding the warp reduce result to shared memory.
let mutable shared = shared.Reinterpret() if threadIdx.x &&& Util.WarpSizeMask = 0 then let warpId = threadIdx.x >>> Util.WarpSizeLog shared.[warpId] __syncthreads()
Next we perform a block reduce to find the best price and allocation among the warps within each block.
if threadIdx.x = 0 then
for warpId = 1 to (blockDim.x / Util.WarpSize) - 1 do
pricedAllocation <- PricedAllocation.Min pricedAllocation shared.[warpId]
output.Prices.[blockIdx.x] <- pricedAllocation.Price
output.Allocations.[blockIdx.x] <- pricedAllocation.Allocation
Now we need to retrieve the results from the GPU, find the price/allocation pair with the minimum price, and then decode the respective allocation from int64 back to an array of int.
let decodeAllocation = // A jagged array of offers by retail sku id, the first dimension // runs over all **sorted** retail sku ids and the second dimension // are the offers for the given retail sku id let offerIdsByRetailSkuId = LocalMarket.localMarketSupplyToOfferIdsByRetailSkuId pr.LocalMarketSupply let dims = offerIdsByRetailSkuId |> Array.map (fun fids -> fids.Length) let indexer = RowMajor(dims) fun allocation -> let indices = allocation |> indexer.ToIndex indices |> Array.mapi (fun rsid idx -> offerIdsByRetailSkuId.[rsid].[idx])
Finally the getResults function copies the array of grid minima back to the host and performs a min by price to find the global minimum along with its accompanying allocation.
let getResults() =
let prices = Gpu.CopyToHost(prices)
let allocations = Gpu.CopyToHost(allocations)
let price, allocation = Array.zip prices allocations |> Array.minBy fst
let allocation = decodeAllocation allocation
price, allocation
Now that we’ve seen the general flow of the search kernel, let’s look into the pricing code. The allocation price function is defined within the kernel function.
let price (allocation:int64) =
generalPrice
numRetailSkus numFulfillmentNodes
(fun i -> fulfillmentNodes.[i])
(fun i -> shippingRules.[i])
(fun i -> commissionRules.[i])
(loopOffers allocation)
The generalPrice function prices an allocation by calling priceFulfillmentNode on an incrementing fulfillmentNodeId within a while loop. The priceFulfillmentNode function returns the number of SKUs computed in the allocation so the loop can exit early if possible. Note that generalPrice and loopOffers are both higher order functions. price uses partial function application and passes the partially applied loopOffers function along to generalPrice.
The loopOffers function loops over the offers of the allocation which are being fulfilled by fulfillment node fnid. Every time loopOffers is called, it loops over each retail SKU but only invokes the function f if the fulfillment node id of the offer for that retail SKU is equal to the current node being priced.Implementing loopOffers as a higher order function provides an abstraction over the various updateXYZ functions used within priceFulfillmentNode.
let loopOffers (allocation:int64) (fnid:int) (f:Offer -> Sku -> unit) =
let offset = ref allocation
let f (iter:AllocationIterator) (rsid:int) =
let idx = AllocationIterator.Decode(iter, offset)
let oid = supply.OfferIds.[iter.SupplyOffset + idx]
let offer = offers.[oid]
let sku = retailSkus.[rsid]
if offer.Id = oid && offer.fulfillmentNodeId = fnid && offer.retailSkuId = rsid then
f offer sku
// The AllocationIterator type is used only by the GPU full
// search implementation where we encode allocations of int[]
// into int64 to improve performance and use less memory.
AllocationIterator.Iterate(supply, numRetailSkus, f)
The reduction in memory use provided by doing this int[] to int64 encoding is important for full search since it must enumerate all possible allocations. Using encoded allocations significantly increases the capabilities of the full search algorithm with regard to the level of cart complexity the algorithm can handle.
priceFulfillmentNode prices the set of offers being fulfilled by fulfillment node fnid, and updates various aspects of the order such as the total order price, total weight, and shipping cost.
let priceFulfillmentNode fnid
(fulfillmentNode:FulfillmentNode)
(shippingRules:int -> ShippingRule)
(commissionRules:int -> CommissionRule)
(loopOffers:int -> (Offer -> Sku -> unit) -> unit) =
let mutable orderPrice = 0.0
let mutable numSkusPriced = 0
let order = ref (Order())
let orderSums = ref (OrderSums())
let updateOrderSums = updateOrderSums orderSums
let updateShippingCost = updateShippingCost shippingRules orderSums order
let updateOfferPrice = updateOfferPrice commissionRules orderSums order
loopOffers fnid updateOrderSums
if orderSums.contents.linesCount > 0 then
numSkusPriced <- orderSums.contents.linesCount
updateShippingCost fulfillmentNode
loopOffers fnid (updateOfferPrice fulfillmentNode)
let order = !order
orderPrice <- order.totalNetPrice + order.totalShipping - order.commission
orderPrice, numSkusPriced
Microservice Layer
At a high level, Jet.com’s microservices are just simple executables that listen to a route for an HTTP request and translate the body JSON to an F# record containing all the data necessary to perform the merchant selection operation. The microservices reference the pricing engine library and use it accordingly.
In addition to testing the core performance of the GPU algorithm, we also needed to address how the GPU microservice would handle high load. That is, what do we do when a request is received before the GPU is done with the previous calculation? Our solution uses a BlockingCollection of size 1 from System.Collections.Concurrent. The tryAdd member attempts to add an element to the collection within the specified wait time.
// 4 second wait time
let [] private MAX_WAIT_TIME = 4000
// With a collection size of 1, once an element has been added to it
// further adds are blocked until the element is removed.
let requestQueue = new BlockingCollection(1)
let cheapestAllocation () =
match pricingAlgorithm with
| GpuFullSearch | PricingAlgorithm.GpuGenetic ->
// We try for 4 seconds to add a new request
if requestQueue.TryAdd(merchantSelectionRequest, MAX_WAIT_TIME) then
try
let result = pricingAlgorithm.Invoke pr
// Once we have the result, remove the request from the
// collection so we can process the next one
requestQueue.Take() |> ignore
Success(result)
with exn ->
requestQueue.Take() |> ignore
Failure exn
Else
// If we are unable to add a new request to the collection within
// 4 seconds, fail with GPU busy message
Failure(new Exception("GPU busy"))
| _ ->
// CPU algorithms aren’t blocked
pricingAlgorithm.Invoke pr
|> Success
This simple solution works well. Due to the improved performance on medium to large-size carts, one Azure N-Series GPU machine is able to handle the request load of multiple Azure D3 (CPU-only) instances.
Conclusion: GPU-accelerated Fulfillment with F# in the Cloud
This post introduced Jet.com’s exponentially complex merchant selection problem and our approach to solving it within an environment of microservices written in F# and running in the Azure cloud. I covered implementation details of a brute force GPU search approach to merchant selection and how this algorithm is used from a RESTful microservice. In future posts I hope to expand on our genetic algorithm approach, how we validated and compared multiple algorithms on production data, and different ways we have used AI and machine learning to improve the performance of our pricing engine.
If you’d like to learn more about some of the GPU-related work going on at Jet.com be sure to check out these two GTC presentations given by Daniel Egloff:
- “Prices Drop as You Shop: How Walmart is Using Jet’s GPU-based Smart Merchant Selection to Gain a Competitive Advantage” (MP4, PDF)
- “Welcome to the Jet Age – How AI and Deep Learning Make Online Shopping Smarter at Walmart” (MP4, PDF)
Check out the Jet Technology Blog to learn more about Jet.com and the problems we are working on, and feel free to reach out to me directly or in the comments below.
Acknowledgements
I would like to thank Daniel Egloff, Neerav Kothari, Xiang Zhang, and Andrew Shaeffer. This work would not have been possible without them.