
AI models, inference engine backends, and distributed inference frameworks continue to evolve in architecture, complexity, and scale. With the rapid pace of change, deploying and efficiently managing AI inference pipelines that support these advanced capabilities becomes a critical challenge.
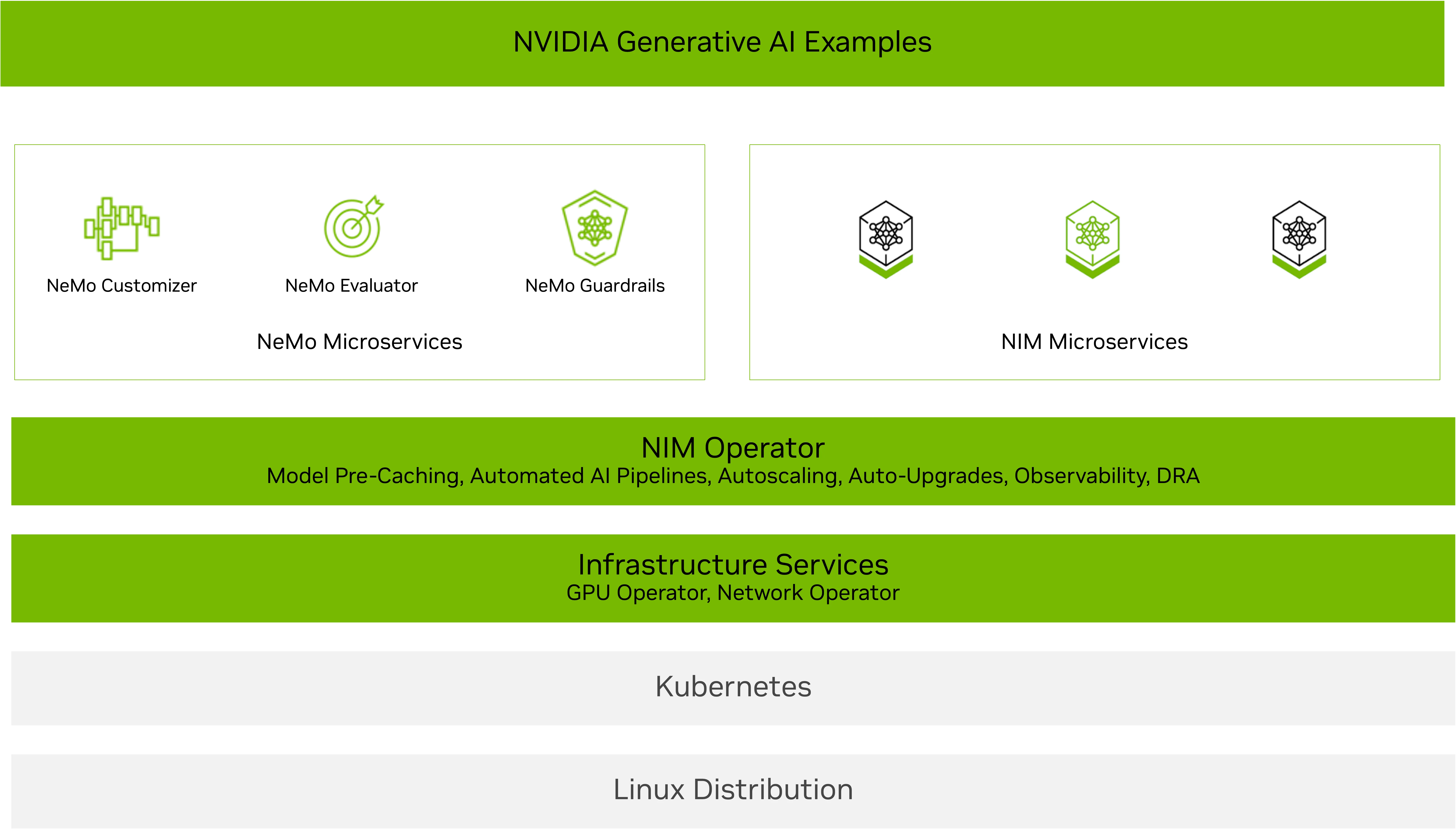
NVIDIA NIM Operator is designed to help you scale intelligently. It enables Kubernetes cluster administrators to operate the software components and services necessary to run NVIDIA NIM inference microservices for the latest LLMs and multimodal AI models, including reasoning, retrieval, vision, speech, biology, and more.
The latest release of NIM Operator 3.0.0 introduces expanded capabilities to simplify and optimize the deployment of NVIDIA NIM microservices and NVIDIA NeMo microservices across Kubernetes environments. NIM Operator 3.0.0 supports efficient resource utilization and integrates seamlessly with your existing Kubernetes infrastructure, including KServe deployments.
NVIDIA customers and partners have been using the NIM Operator to efficiently manage inference pipelines for a variety of applications and AI agents, including chatbots, agentic RAG, and virtual drug discovery.
NVIDIA has recently collaborated with Red Hat to enable NIM deployment on KServe with the NIM Operator. “Red Hat contributed to the NIM Operator open source GitHub repo to enable NVIDIA NIM deployment on KServe,” said Red Hat Director of Engineering Babak Mozaffari. “This feature allows the NIM Operator to deploy NIM microservices that benefit from KServe lifecycle management and simplifies scalable NIM deployment using NIM service. Native KServe support in the NIM Operator also allows users to benefit from model caching with NIM cache and leverage NeMo capabilities like NeMo Guardrails for building Trusted AI for all your KServe Inference endpoints.”
This post explains new capabilities in the NIM Operator 3.0.0 release, including:
- Simplified multi-LLM compatible and multi-node NIM deployment
- Efficient GPU utilization with Dynamic Resource Allocation (DRA)
- Seamless deployment on KServe
Flexible NIM deployment: Multi-LLM compatible and multi-node
NIM Operator 3.0.0 adds support for easy, fast NIM deployment. You can use it with a domain-specific NIM—such as those for biology, speech, or retrieval—or various NIM deployment options, including multi-LLM compatible, or multi-node.
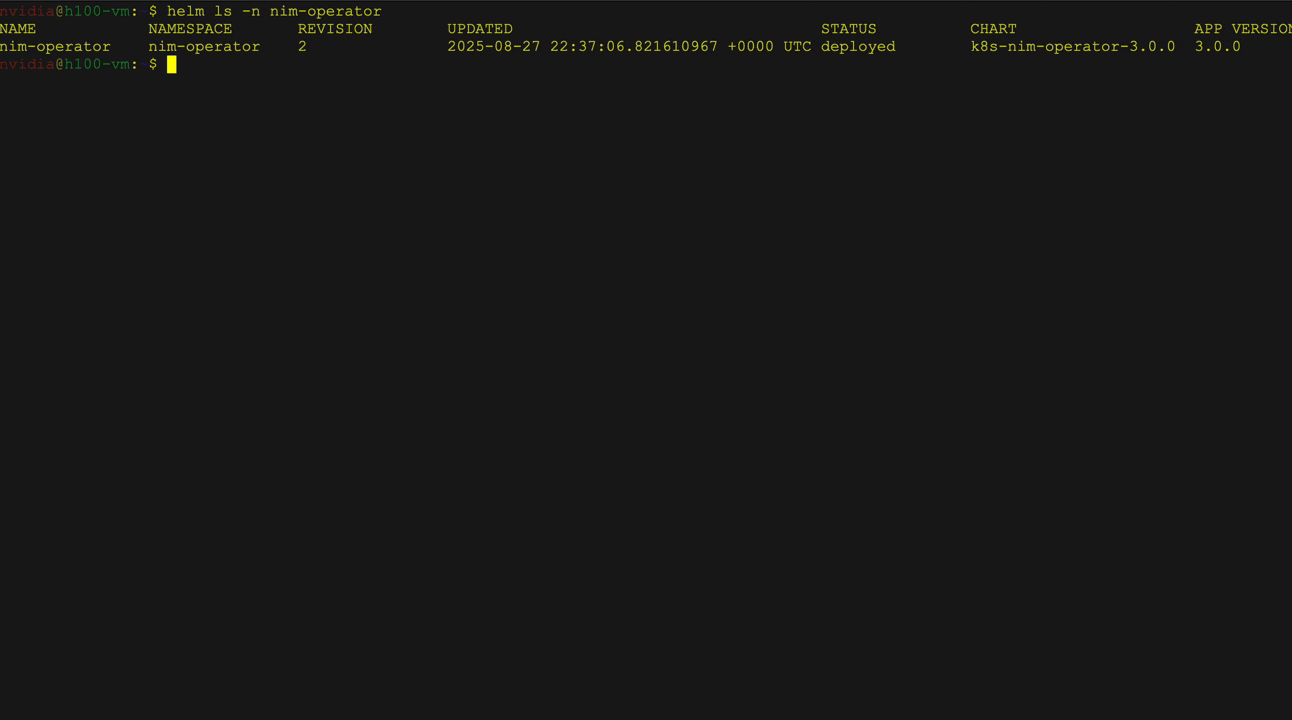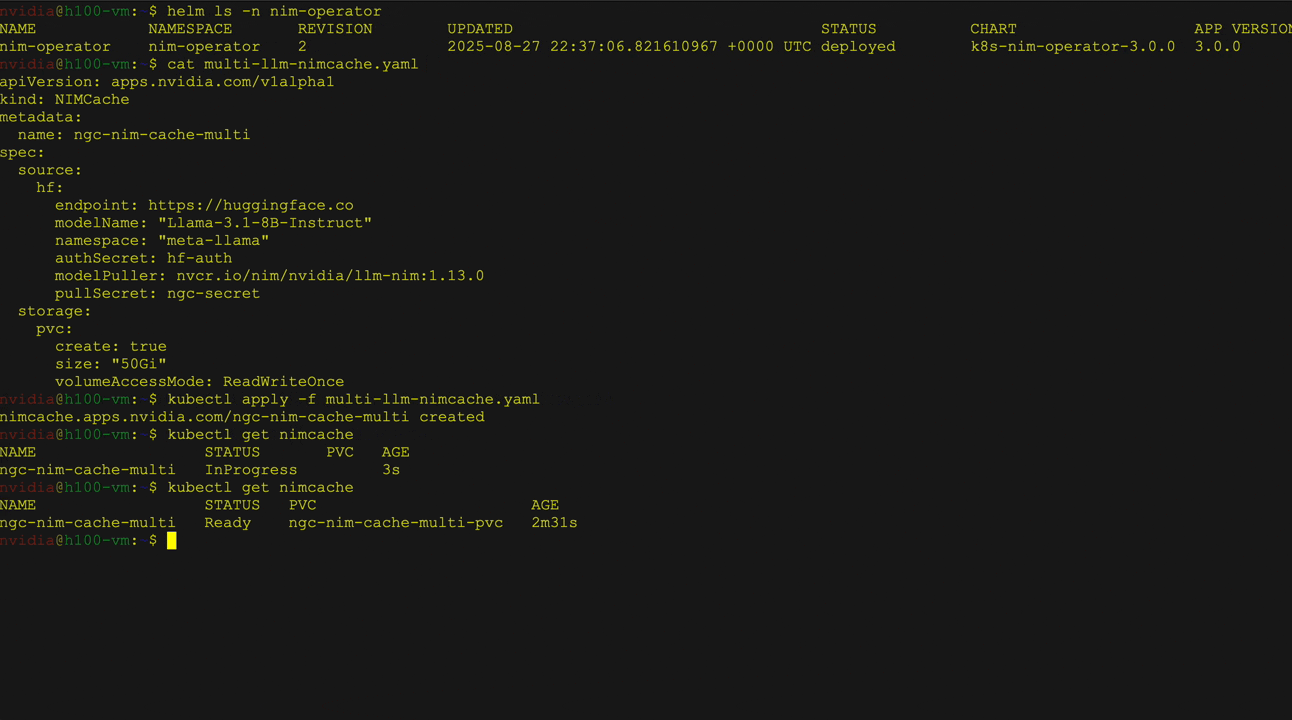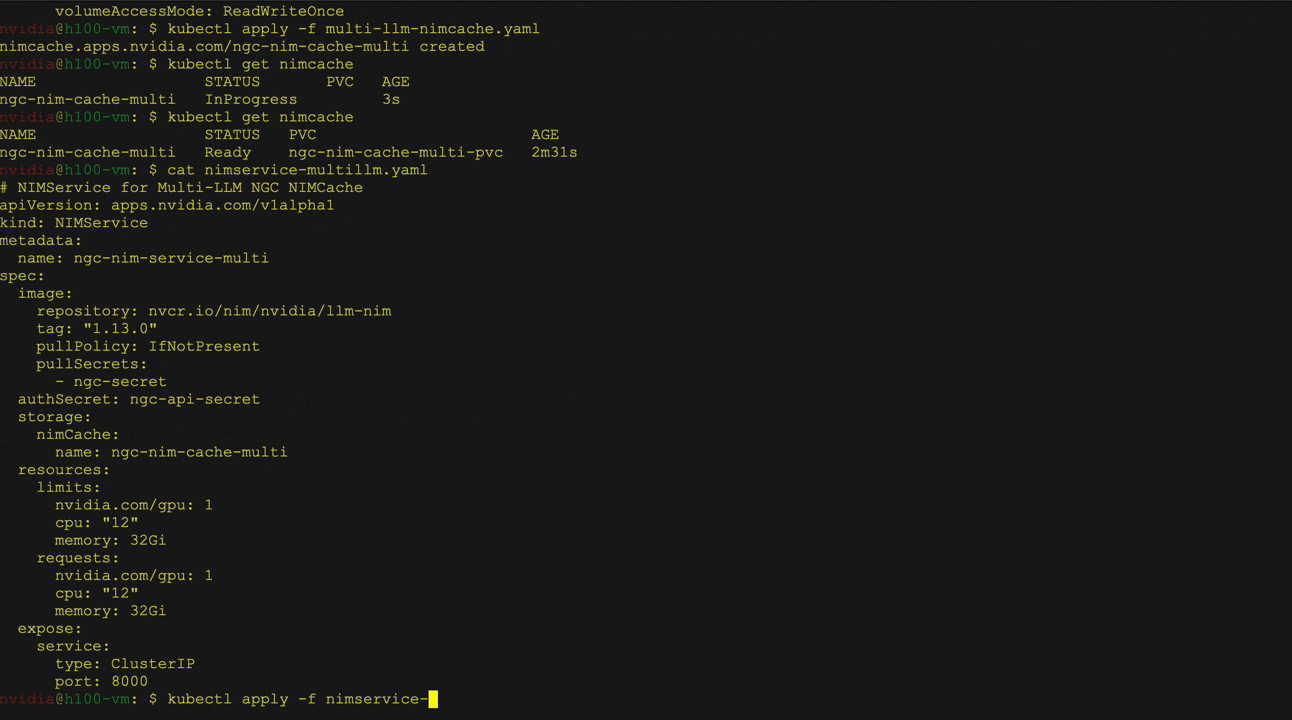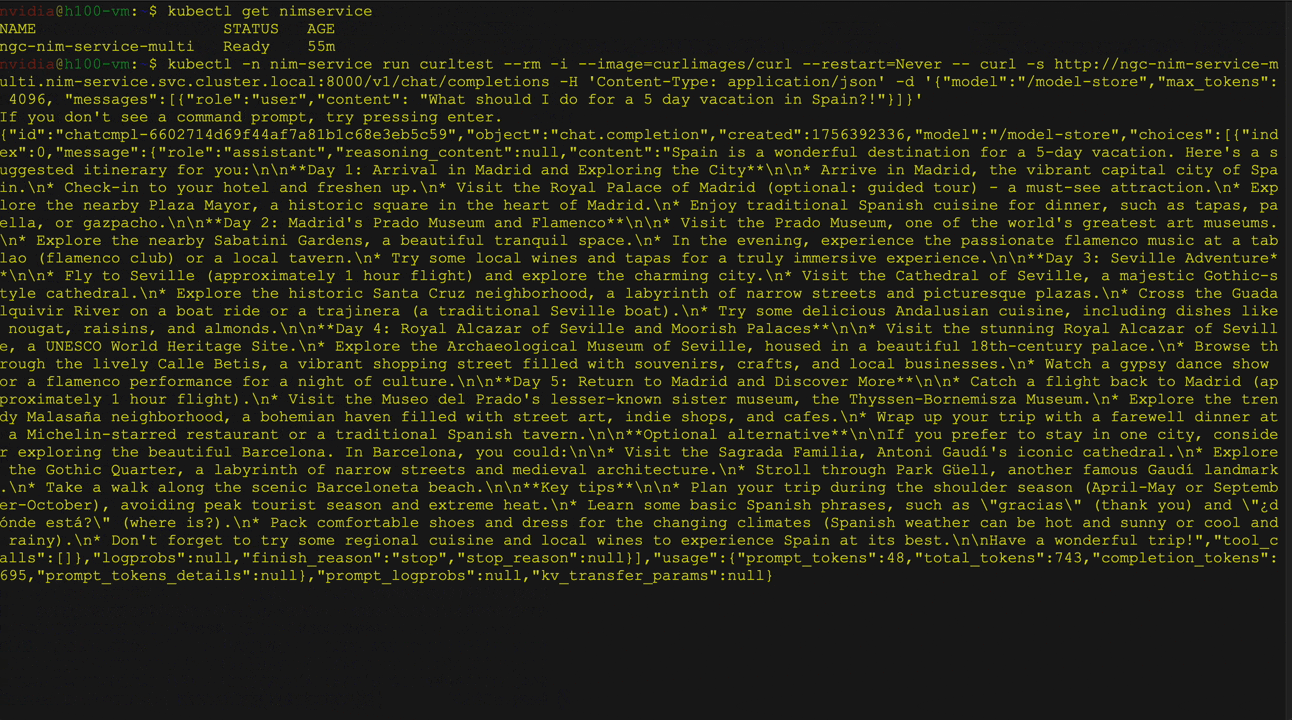
- Multi-LLM compatible NIM deployment: Deploy diverse models with custom weights from sources like NVIDIA NGC, Hugging Face, or local storage. Use the NIM cache custom resource definition (CRD) to download weights to PVCs and the NIM service CRD to manage deployment, scaling, and ingress.
- Multi-node NIM deployment addresses the challenge of deploying massive LLMs that cannot fit on a single GPU or need to run on multiple GPUs and potentially on multiple nodes. NIM Operator supports caching for multi-node NIM deployment using the NIM cache CRD, and deploying them using the NIM service CRD on Kubernetes with LeaderWorkerSets (LWS).
Note that the multi-node NIM deployment without GPUDirect RDMA may result in frequent restarts of LWS leader and worker pods due to model shard loading timeouts. Using fast network connectivity such as IPoIB or ROCE is highly recommended and can be easily configured through the NVIDIA Network Operator.
Figure 2 shows the deployment of large language models (LLMs) from the Hugging Face library on Kubernetes using the NVIDIA NIM Operator as a multi-LLM NIM deployment. It specifically demonstrates deploying the Llama 3 8B Instruct model, including service and pod status verification, followed by a curl command to send a request to the service.
Efficient GPU utilization with DRA
DRA is a built-in Kubernetes feature that simplifies GPU management by replacing traditional device plugins with a more flexible and extensible approach. DRA enables users to define GPU device classes, request GPUs based on those classes, and filter them according to workload and business needs.
NIM Operator 3.0.0 supports DRA under technology preview by configuring ResourceClaim and ResourceClaimTemplate on NIM Pod through both the NIM service CRD and NIM Pipeline CRD. You can either create and attach your own claims or let the NIM Operator create and manage them automatically.
The NIM Operator DRA supports:
- Full GPU and MIG usage
- GPU sharing through time slicing by assigning the same claim to multiple NIM services
Note: This feature is currently available as a technology preview, with full support available soon.
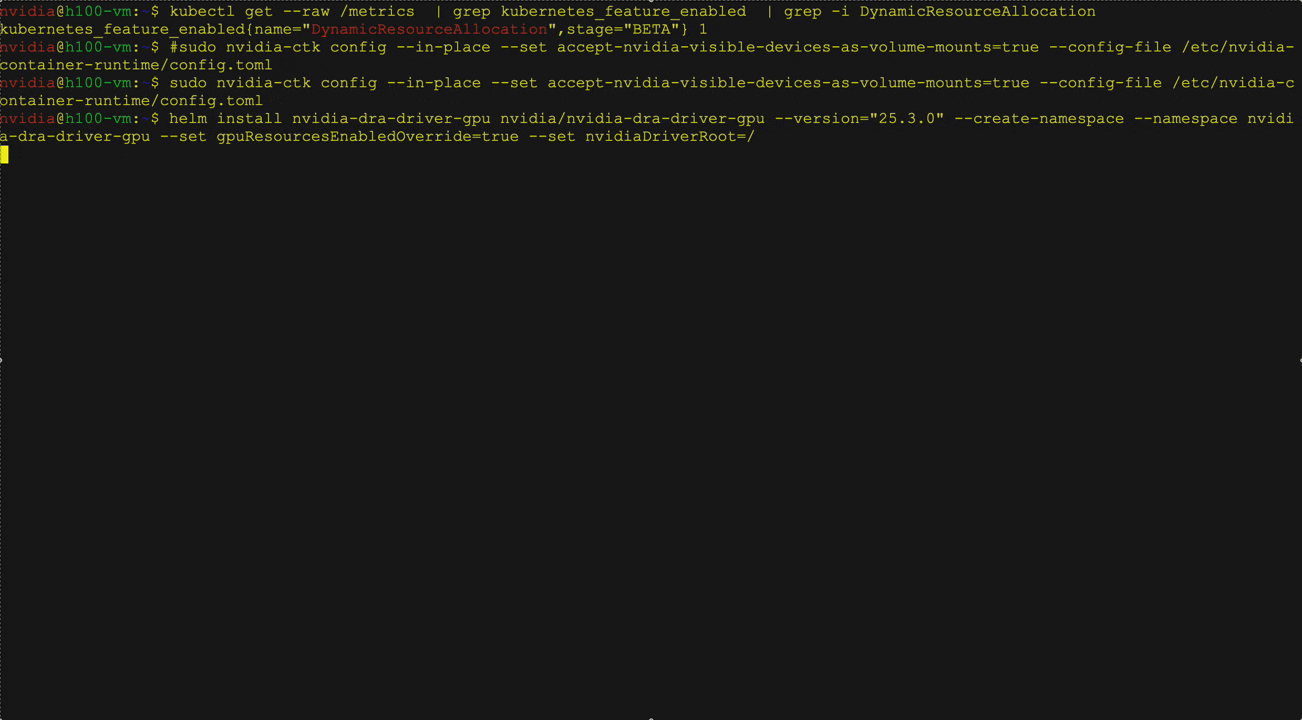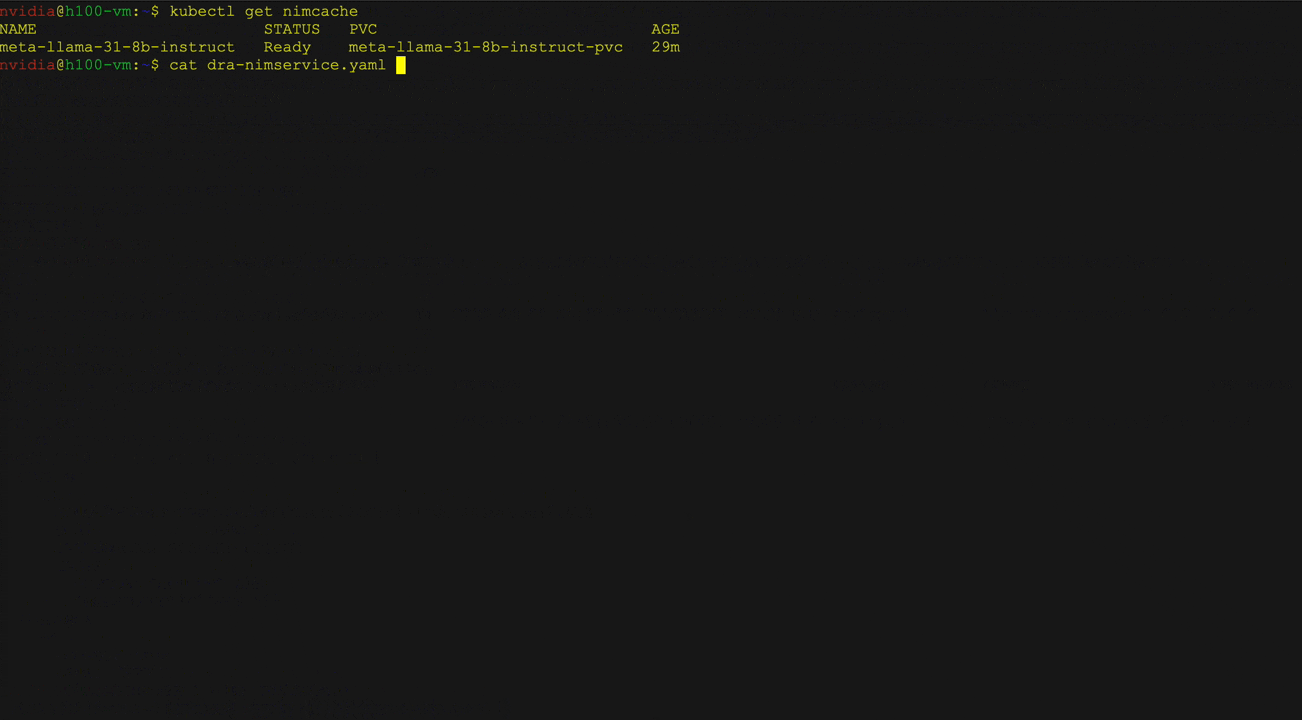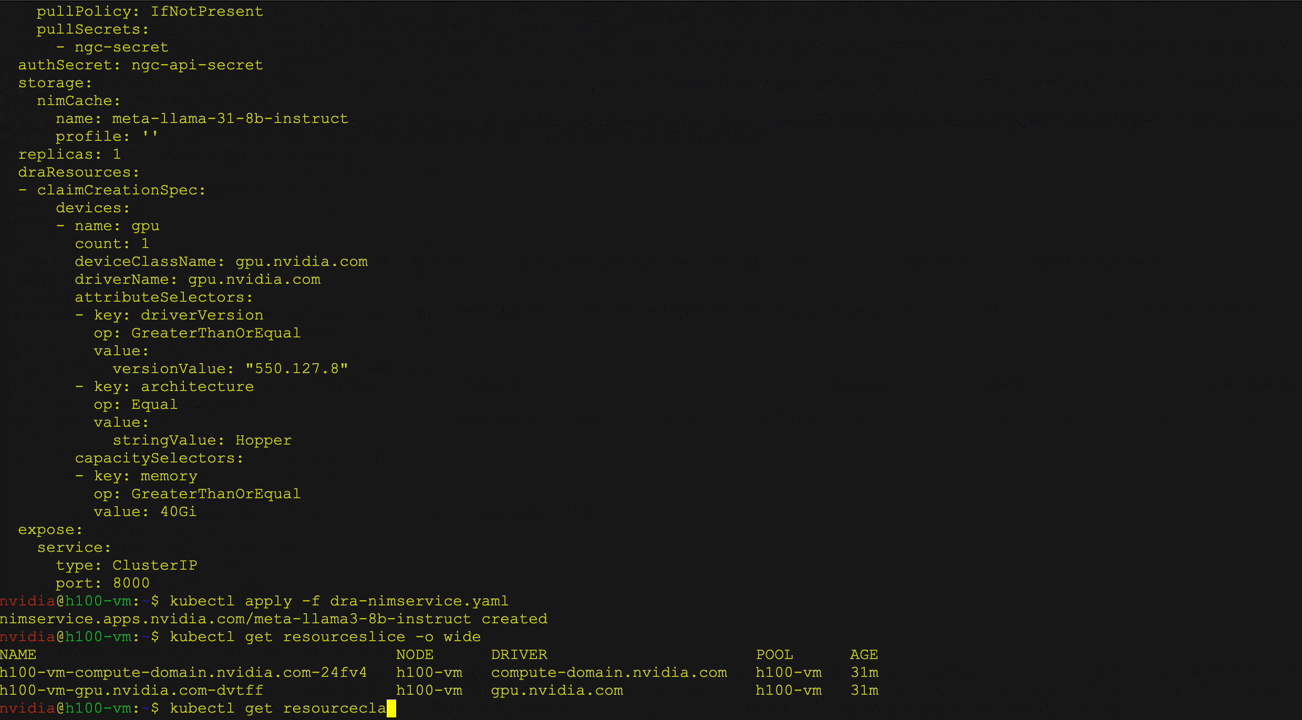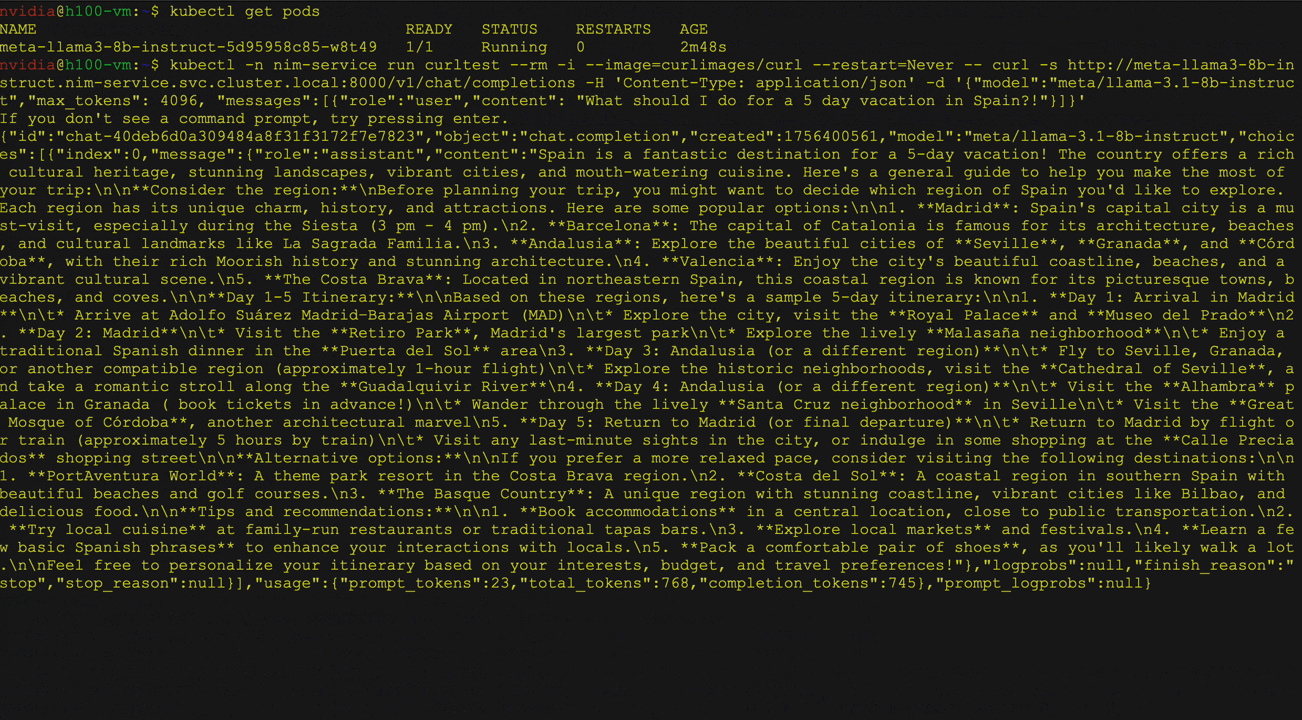
Figure 3 demonstrates the deployment of Llama 3 8B Instruct NIM using Kubernetes DRA with NIM Operator. Users can define a resource claim in a NIM service to request specific hardware attributes such as GPU architecture and memory, and interact with the deployed LLM using curl.
Seamless deployment on KServe
KServe is a widely adopted open source inference serving platform used by many partners and customers. NIM Operator 3.0.0 supports both raw and serverless deployments on KServe by configuring the InferenceService custom resource to manage deployment, upgrades, and autoscaling of NIM. NIM Operator simplifies the deployment process by automatically configuring all required environment variables and resources in the InferenceService CRDs.
This integration delivers two additional benefits:
- Intelligent caching with NIM cache to reduce initial inference time and autoscaling latency, resulting in faster and more responsive deployments.
- NeMo microservices support for evaluation, guardrails, and customization to enhance AI systems for latency, accuracy, cost, and compliance.
Figure 4 shows the deployment of the Llama 3.2 1B Instruct NIM on KServe using NIM Operator. Two distinct deployment methodologies are shown: RawDeployment and Serverless. The Serverless deployment incorporates autoscaling functionality through K8s annotation. Both strategies use a curl command to test the responses of the NIM.

Get started scaling AI inference with NIM Operator 3.0.0
NVIDIA NIM Operator 3.0.0 makes deploying scalable AI inference easier than ever. Whether you’re working with multi-LLM compatible or multi-node NIM deployment, optimizing GPU usage with DRA, or deploying on KServe, this release enables you to build high-performance, flexible, and scalable AI applications.
By automating the deployment, scaling, and lifecycle management of both NVIDIA NIM and NVIDIA NeMo microservices, NIM Operator makes it easier for enterprise teams to adopt AI workflows. This effort aligns with making AI workflows easy to deploy with NVIDIA AI Blueprints, enabling quick movement to production. The NIM Operator is part of NVIDIA AI Enterprise, providing enterprise support, API stability, and proactive security patching.
Get started through NGC or from the NVIDIA/k8s-nim-operator open source GitHub repo. For technical questions on installation, usage, or issues, file an issue on the NVIDIA/k8s-nim-operator GitHub repo.







