
 This week’s Spotlight is on Pierre Wahl, a PhD student at Vrije Universiteit Brussel.
This week’s Spotlight is on Pierre Wahl, a PhD student at Vrije Universiteit Brussel.
As a member of the Brussels Photonics Team (B-PHOT), he designs energy-efficient optical interconnects and works closely with the NVIDIA Application Lab at the Forschungszentrum Jülich.
Pierre used CUDA to develop B-CALM, a GPU-accelerated Finite Difference Time Domain (FDTD) simulator.
NVIDIA: Pierre, what is B-CALM?
Pierre: B-CALM stands for Belgium-California Light Machine and is an FDTD simulator to numerically solve electromagnetic problems using the fundamental Maxwell’s equations.
FDTD is particularly useful for problems where the electromagnetic waves interact with objects that are the same order of magnitude in size as the wavelength. Those problems can be very computationally intensive, especially when simulating the interaction of electromagnetic waves with metals, which is at the core of my research.
NVIDIA: How have GPUs helped you in your research?
Pierre: I research avenues to make on-chip optical interconnects very energy efficient, because safely extracting the heat generated by regular metallic interconnects from chips gets increasingly difficult with the ever-increasing bandwidth requirements.
However, for optical interconnects to be competitive, optoelectronic components (modulators/photodetectors) have to have a very low electrical capacitance and must therefore be made very small. By using metals to guide and confine light (also referred to as plasmonics) optoelectronic components can have a size that is only a fraction of the wavelength and hence a very small electrical capacitance.
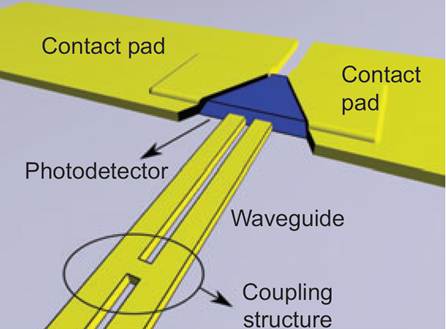
To be able to design coupling structures to sub-wavelength plasmonic optoelectronic components, very detailed and computationally intensive electromagnetic simulations have to be performed and a very fine grid has to be utilized.
Using our CPU FDTD code, we quickly ran into computational limitations. B-CALM was born by porting our FDTD code to GPUs using CUDA and we obtained an 80X speed-up.
Simulations that used to run overnight now take only ten minutes. This speed-up allowed us to optimize plasmonic coupling structures iteratively, which we were not able to do before porting our code to GPUs.
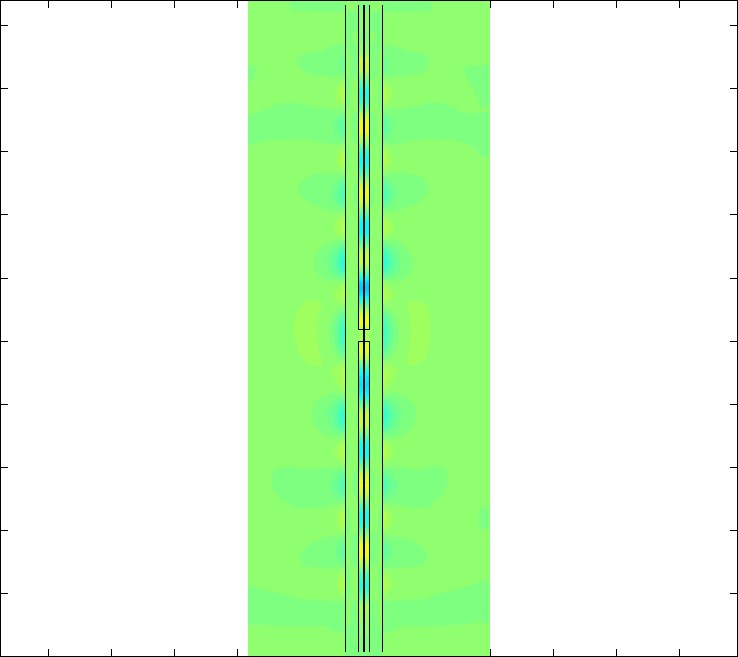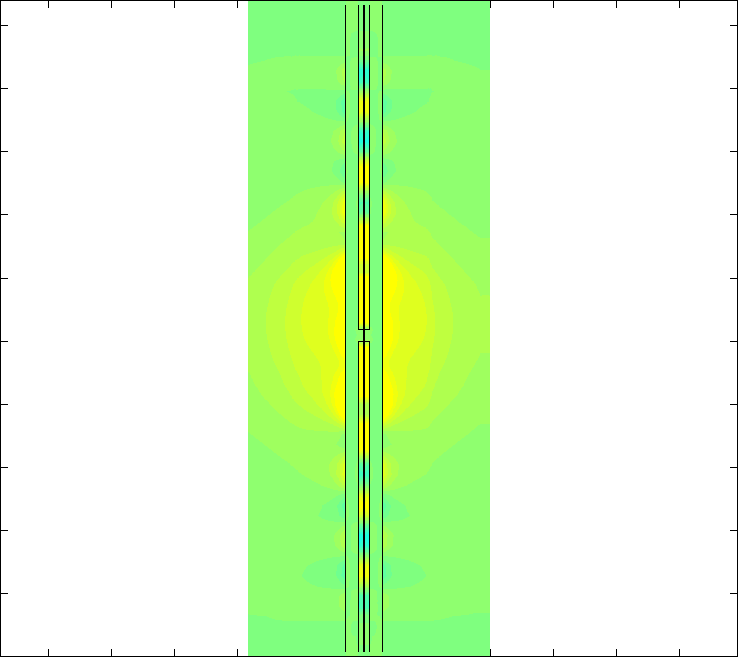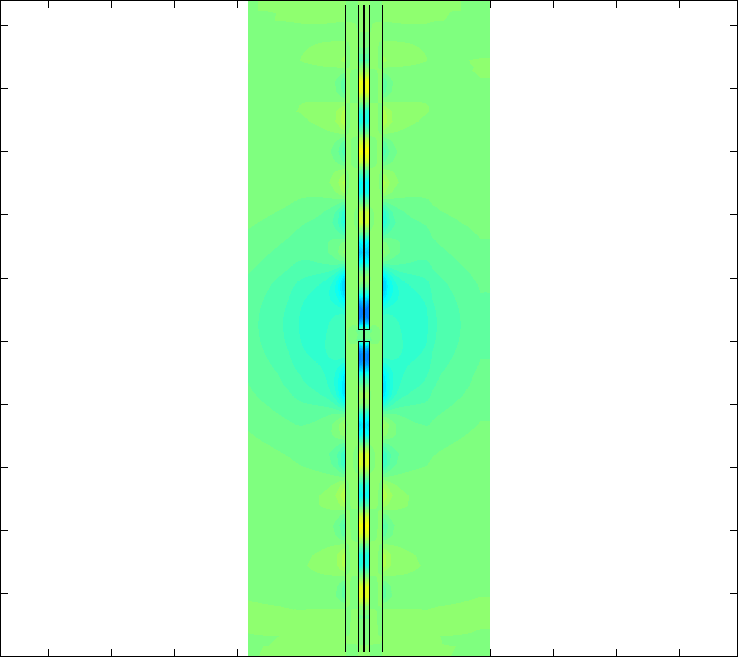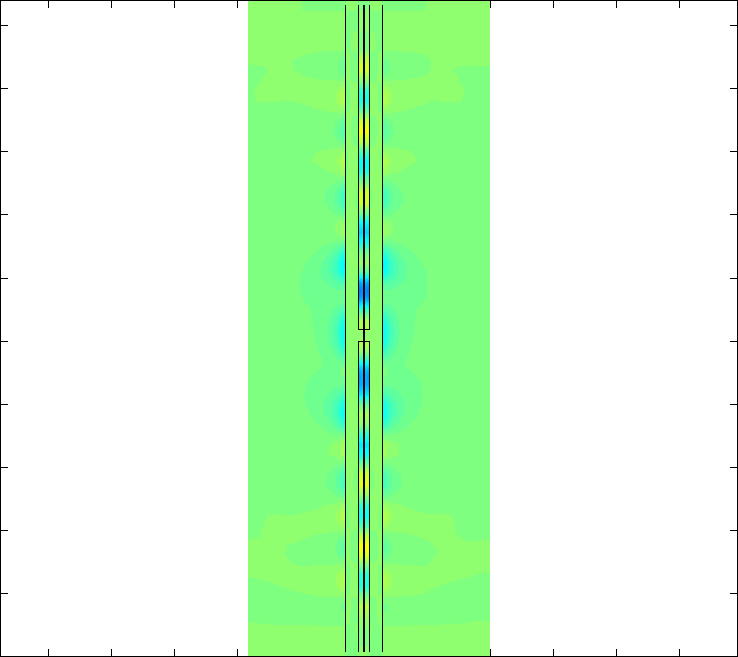
NVIDIA: What types of parallel algorithms are being implemented?
Pierre: Fundamentally B-CALM is a Finite Difference algorithm with a halo of 1 that is parallelized using very fine-grained domain decomposition. Each CUDA thread computes only a very small part of the simulation domain. A white paper by Paulius Micikevicius of NVIDIA on the general implementation of Finite Difference algorithms that can be applied to many problems was very helpful.
NVIDIA: What approaches did you find the most useful for CUDA development?
Pierre: I had little experience in parallel programming before I started to learn CUDA. Personally, I found the documented examples (such as matrix multiplication) in the SDK very useful to learn the fundamentals. Also, the CUDA Toolkit is very well documented so you can learn about the intricacies only when you need them while you are already working on your project.
NVIDIA: What advice would you offer others in your field looking at CUDA?
Pierre: CUDA C is really a great language to program on GPUs and understanding the fundamentals is enough to get started. Before you get started, take time to consider whether your problem is well-suited for GPUs. As a rule of thumb, I would say that well-suited problems need to access most of their data in a regular, and preferably non-data dependent, way.
NVIDIA: Describe your partnership with the NVIDIA Application Lab at Jülich.
Pierre: The NVIDIA Application Lab at Jülich helped us take B-CALM to the next level by assisting us in implementing a CUDA-aware MPI layer so that B-CALM could run on GPU clusters and by helping us to optimize the most important kernels. Their insights in terms of domain decomposition proved to be invaluable as well. In its current form, B-CALM scales up to 32 GPUs, but our models predict it could scale up to hundreds of GPUs.
NVIDIA: Tell us about the project with the Institute of Energy Research (IEK-5) at Jülich.
Pierre: The IEK-5 works on thin film solar cells. One particular research topic is the patterning of the conducting oxide on top of thin film solar cells to make them more efficient. The influence of the pattern of the conducting oxide on the solar-cells performance is due to the scattering by sub-wavelength patterns in the conducting oxide.

Simulating those effects required large broadband simulations, for which B-CALM running on GPUs proved to be the ideal tool. Although thin film solar cells are outside the scope of my research, it was exciting to see that the computing power of B-CALM and GPUs could be applied elsewhere.
NVIDIA: Describe the system you are running on.
Pierre: At B-PHOT, we acquired a single computing node with four NVIDIA Tesla C2070 cards and use Intel(R) Xeon(R) CPU X5650 @ 2.67GHz processors. The operating system is Debian Linux.
NVIDIA: What approaches did you find the most useful for CUDA development?
Pierre: I had little experience in parallel programming before I started to learn CUDA. Personally, I found the documented examples (such as matrix multiplication) in the SDK very useful to learn the fundamentals. Also, the CUDA Toolkit is very well documented so you can learn about the intricacies only when you need them while you are already working on your project.
NVIDIA: What advice would you offer others in your field looking at CUDA?
Pierre: CUDA is really a great platform for programming GPUs and understanding the fundamentals is enough to get started. Before you get started, take time to consider whether your problem is well-suited for GPUs. As a rule of thumb, I would say that well-suited problems need to access most of their data in a regular, and preferably non-data dependent, way.
NVIDIA: What are the biggest challenges going forward?
Pierre: One of the challenges moving forward is to make B-CALM a feature-complete FDTD simulator. This would include sub-gridding. This is the ability to have certain areas in the simulation space with a finer resolution than others. This might be difficult as we will certainly run into load-balancing issues.
NVIDIA: If you had more computing power, what could you and your team do?
Pierre: We could move from simulating plasmonic structures, such as waveguides, couplers or photodetectors, to the study of integrated optical systems, where all those components would be present in one simulation. This might be needed because, when components are very tightly integrated, a change in one component can affect the entire system. System analysis would be particularly useful in the study of tolerance for fabrication variability.
NVIDIA: How did you become interested in photonics?
Pierre: I became interested in photonics because it is an engineering science that is very close to fundamental physics. Solving engineering problems, where you regularly need electromagnetism, quantum mechanics and advanced mathematical and computational methods is really fun, and you learn a lot as well.
Read more GPU Computing Spotlights.