Posts by Tim Dettmers
Data Science
Sep 08, 2016
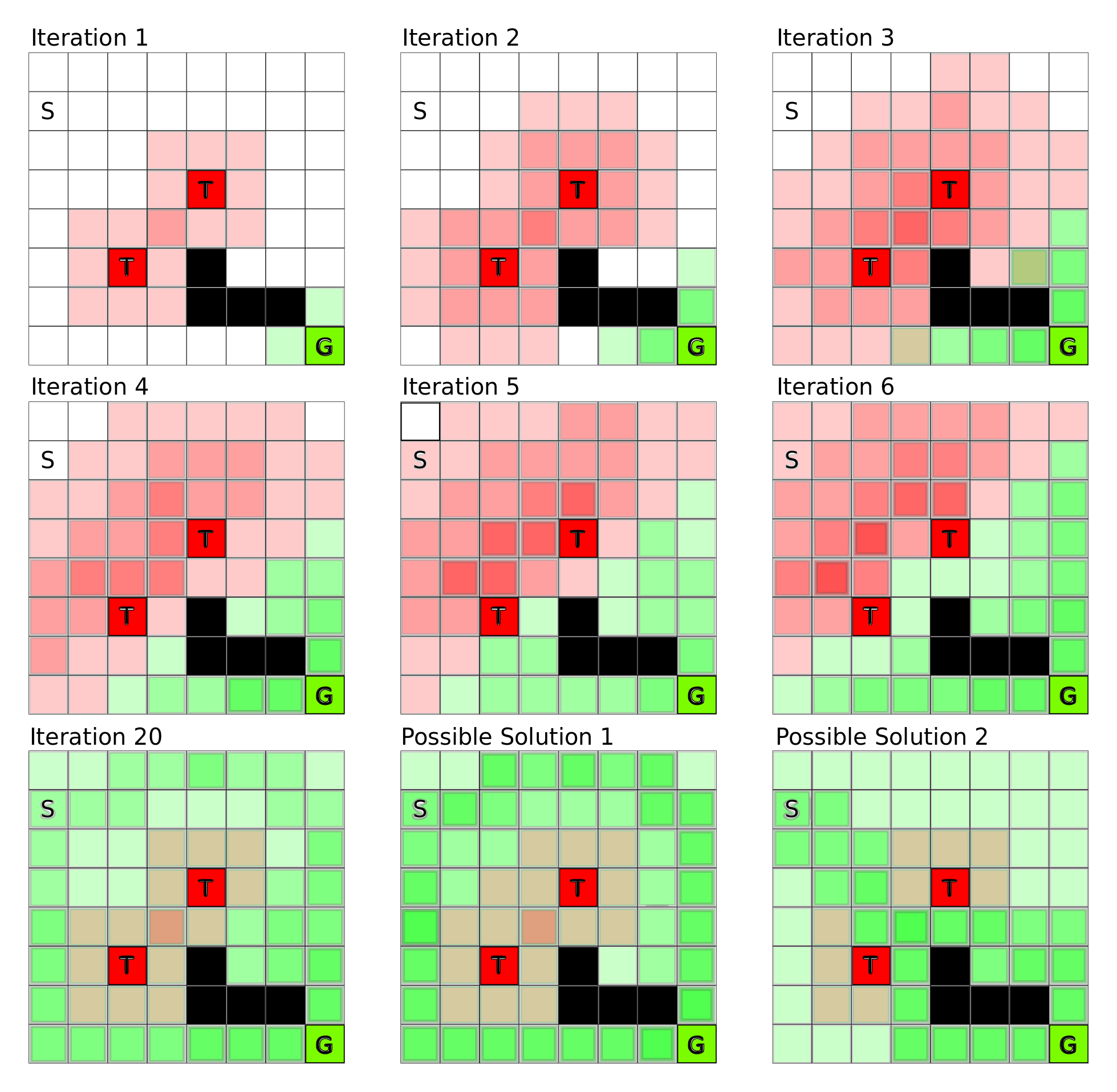
Deep Learning in a Nutshell: Reinforcement Learning
This post is Part 4 of the Deep Learning in a Nutshell series, in which I’ll dive into reinforcement learning, a type of machine learning in which agents take...
28 MIN READ

Simulation / Modeling / Design
Mar 07, 2016
Deep Learning in a Nutshell: Sequence Learning
This series of blog posts aims to provide an intuitive and gentle introduction to deep learning that does not rely heavily on math or theoretical...
13 MIN READ

Data Science
Dec 16, 2015
Deep Learning in a Nutshell: History and Training
This series of blog posts aims to provide an intuitive and gentle introduction to deep learning that does not rely heavily on math or theoretical constructs....
23 MIN READ
Data Science
Nov 03, 2015
Deep Learning in a Nutshell: Core Concepts
This post is the first in a series I’ll be writing for Parallel Forall that aims to provide an intuitive and gentle introduction to deep learning. It covers...
19 MIN READ