Posts by Carl (Izzy) Putterman

Agentic AI / Generative AI
Dec 17, 2024
Boost Llama 3.3 70B Inference Throughput 3x with NVIDIA TensorRT-LLM Speculative Decoding
Meta's Llama collection of open large language models (LLMs) continues to grow with the recent addition of Llama 3.3 70B, a text-only...
8 MIN READ

Agentic AI / Generative AI
Dec 02, 2024
TensorRT-LLM Speculative Decoding Boosts Inference Throughput by up to 3.6x
NVIDIA TensorRT-LLM support for speculative decoding now provides over 3x the speedup in total token throughput. TensorRT-LLM is an open-source library that...
9 MIN READ

Data Center / Cloud
Nov 15, 2024
NVIDIA NIM 1.4 Ready to Deploy with 2.4x Faster Inference
The demand for ready-to-deploy high-performance inference is growing as generative AI reshapes industries. NVIDIA NIM provides production-ready microservice...
3 MIN READ
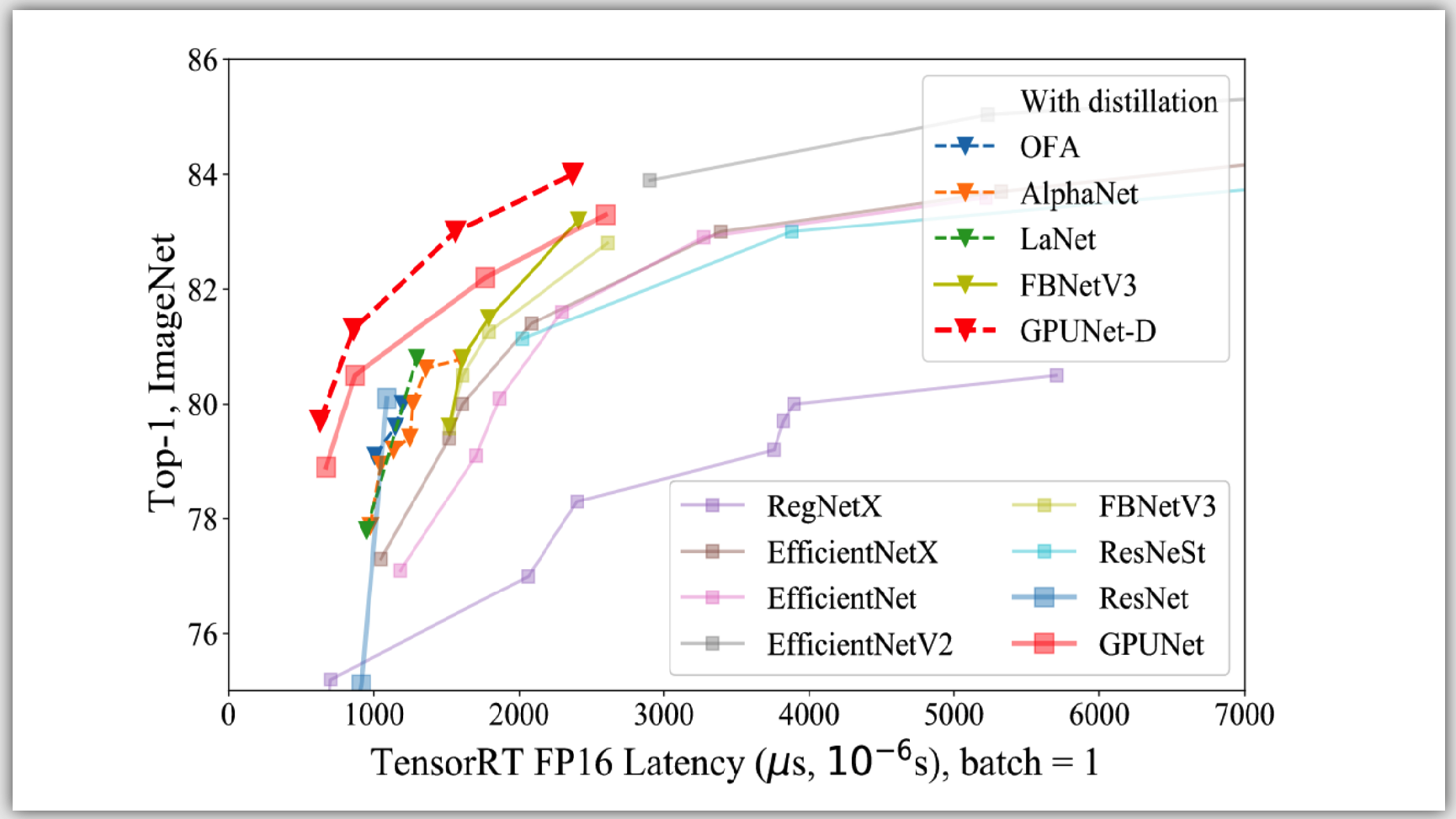
Computer Vision / Video Analytics
Aug 30, 2022
Beating SOTA Inference Performance on NVIDIA GPUs with GPUNet
Crafted by AI for AI, GPUNet is a class of convolutional neural networks designed to maximize the performance of NVIDIA GPUs using NVIDIA TensorRT. Built using...
6 MIN READ

Data Science
Feb 15, 2022
Time Series Forecasting with the NVIDIA Time Series Prediction Platform and Triton Inference Server
In this post, we detail the recently released NVIDIA Time Series Prediction Platform (TSPP), a tool designed to compare easily and experiment with arbitrary...
13 MIN READ