Imaging over long distances is important for many defense and commercial applications. High-end ground-to-ground, air-to-ground, and ground-to-air systems now routinely image objects several kilometers to several dozen kilometers away; however, this increased range comes at a price. In many scenarios, the limiting factor becomes not the quality of your camera but the atmosphere through which the light travels to the camera. Dynamic changes in the atmospheric density between the camera and object impart time-variant distortions resulting in loss of contrast and detail in the collected imagery (see Figure 1 and Figure 2).
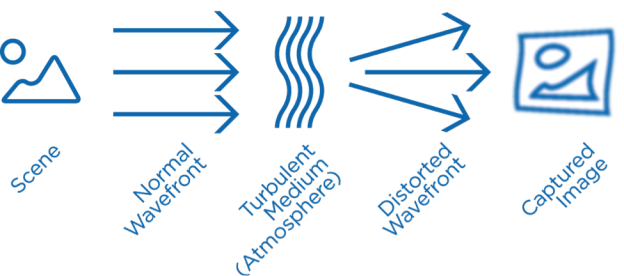
Several approaches have been developed to combat this effect that can be roughly divided into two categories: hardware-based and signal processing approaches. The primary hardware technique is adaptive optics (AO), an approach favored by the astronomical community to observe stellar phenomena. AO techniques generally employ a deformable mirror to correct the incoming wavefront before it is captured on the sensor. While this provides the ability to improve imagery to account for distortions, the equipment required is fragile and expensive and is therefore not suitable for many applications. In contrast, signal processing techniques are limited only by the computational hardware they run on. In our case, we have leveraged the processing power of GPUs to achieve the performance necessary for real-time processing of high-definition video. Thanks to modern GPUs, we are now able to process live 720p video streams at over 30 fps, as the video below shows.

One of the major advantages of the signal processing approach we have developed at EM Photonics is that there is no additional optical or sensing hardware (such as a wavefront sensor) required. Our application processes incoming video streams using off-the-shelf computational hardware and outputs an enhanced version. Our tool, ATCOM™, contains multiple image processing components including atmospheric turbulence mitigation, local area contrast enhancement, and physics-based deblurring, among others. The crux of the turbulence mitigation functionality is based on a multi-frame approach where we are conceptually creating an output image from multiple input images by extracting more information than that which is available in any single image. This approach exploits the time-variant nature of the atmosphere. While all images are blurred by turbulence, dynamic movement of the atmosphere means that each frame is blurred in a different way, allowing us to extract different information from successive frames in a video (or other short exposure image stream). Despite being multi-frame, our techniques allow us to output a new enhanced image for each one collected, thus minimizing latency and maintaining the real time nature of the incoming stream (see Figure 3).
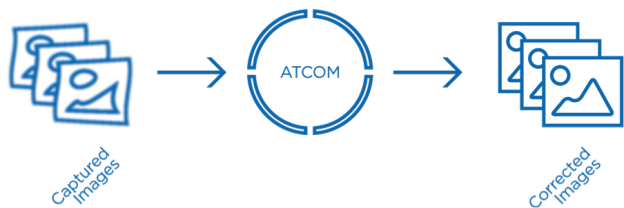

Using the technique described above, ATCOM is able to remove the atmospheric distortions revealing more detail in collected imagery (see Figure 4) and allowing for more stable, natural videos (see videos above and below).
Achieving the performance necessary to enhance high-definition videos in real time is not possible on CPU-only systems and thus spurred our use of NVIDIA GPUs. We have been using GPUs in this application for many years, but recent feature additions to NVIDIA GPU hardware have enabled new optimizations that allowed us to further improve performance. In the following I’ll highlight specific ways that we leveraged the GPU for improved performance in ATCOM.
Tiling
Our technique inherently breaks the input image into a collection of tiles for processing. While the size of these tiles can be changed, we generally use tiles of 64×64 or 128×128 pixels. Processing is then performed on a per-tile basis with some data for a particular tile’s computations coming from pixels in its neighboring tiles. This cross-tile data sharing can result in dependencies that unnecessarily constrain parallel execution. On the GPU, it is preferable that each work unit is independent, so we replicate data in each tile to include the pixels from its neighbors that it would need for processing (see Figure 5). In this way, more bandwidth is used but all work units are independent so they expose much more parallelism to the GPU.

Read-Only Data Cache
In the Kepler architecture, NVIDIA added the ability to access the texture unit for read-only access to global memory. This eases L1 and shared memory volume and contention, and supports full speed unaligned memory access. The read-only cache is available on devices of Compute Capability 3.5 and up, such as Tesla K20, K40, and K80. For ATCOM, we use this cache to read in the Fourier transform data during the most computationally intense portion of our algorithm, resulting in performance gains greater than 5%. [Ed: see this previous Parallel Forall post for information on using the read-only data cache.]
Pre-Fetch Load
The NVIDIA Maxwell GPU architecture has improved ability to simultaneously run multiple non-dependent instructions, which lets us take advantage of instruction-level parallelism in the algorithm. We do so by adding a prefetch load to our processing pipeline. Each iteration of reconstruction has operations that are not dependent on values from the previous iteration. On Maxwell, we can load the next iteration’s values while still processing the current one. These operations are completely independent so they do not interfere.

Performance
Our benchmark goal has been to enhance an incoming 1280×720 video stream at 30 frames per second (FPS) using off-the-shelf processing hardware. GPUs were critical for meeting this goal. Resolution and frame rate are the key measures for ATCOM performance, and one can be traded for the other. A higher framerate can be achieved by reducing the resolution of the video being enhanced (or only processing a sub-region of the incoming stream) and conversely, larger resolution images can be processed at a slower rate.
Harnessing GPU technology has allowed us to not only improve application performance through our own optimizations, but also ride NVIDIA’s technology curve. The table compares our previous-generation solver based on the NVIDIA GeForce GTX 690 to our latest version using the GeForce GTX Titan X.
| Previous Generation | Current Generation |
| Intel Haswell i7-4770 @ 3.4 GHz (4 cores) | Intel Xeon CPU E3-1230 v3 @ 3.30GHz (4 Cores) |
| 32 GB RAM | 32 GB RAM |
| NVIDIA GeForce GTX 690 | NVIDIA GeForce GTX Titan X |
| 24.5 Frames Per Second at 1280×720 (full frame) | 40.0 Frames Per Second at 1280×720 (full frame) |
As you can see, we have crossed over to real-time performance by reaching 30 fps for a 1280×720 video stream. The old system could only achieve real time for a smaller resolution video stream. Also, the new version of our engine includes additional features such as enhanced motion compensation and denoising.
There are a couple key points to note about the 63.3% performance increase we achieved. The most obvious is the transition from the GTX 690 to the Titan X card. As discussed previously, in addition to the increased performance a new generation of computational hardware provides, the most recent GPUs have additional features that we were able to leverage, namely additional memory and caching options and instruction-level parallelism.
A more subtle point, however, is that the GTX 690 actually combines two GPUs on a single card. Working with a GTX 690 effectively means using two GTX 680 GPUs. Therefore, our move to the Titan X cut the number of GPUs we used in half. So not only did we improve performance, we reduced the amount of computational hardware (and associated power usage) required to achieve it.
More Information
For more information, please see the ATCOM website and the talk presented at the most recent NVIDIA GPU Technology Conference. For specific questions, contact us at atcom@emphotonics.com.
If you work in this area consider attending and/or submitting a paper to the Long-Range Imaging conference at SPIE’s Defense and Commercial Sensing Symposium