Think of it as style transfer for dancing, a deep learning based algorithm that can convincingly show a real person mirroring the moves of their favorite dancers.
The work, developed by a team of researchers from the University of California Berkeley, allows anyone to portray themselves as a world-class ballerina or a pop superstar like Bruno Mars.
“With our framework, we create a variety of videos, enabling untrained amateurs to spin and twirl like ballerinas, perform martial arts kicks or dance as vibrantly as pop stars,” the researchers stated in their paper. “Using pose detections as an intermediate representation between source and target, we learn a mapping from pose images to a target subject’s appearance,” the team explained.
Using NVIDIA TITAN Xp and GeForce GTX 1080 Ti GPUs, with the cuDNN-accelerated PyTorch deep learning framework for both training and inference, the team first trained their conditional generative adversarial network on video of amateur dancers performing a range of poses filmed at 120 frames per second. Each subject completed the poses for at least 20 minutes.
The team then extracted pose key points for the body, face, and hands using the architecture provided by a state of the art pose detector OpenPose.
For the image translation, the team based their algorithm on the pix2pixHD architecture developed by NVIDIA researchers.
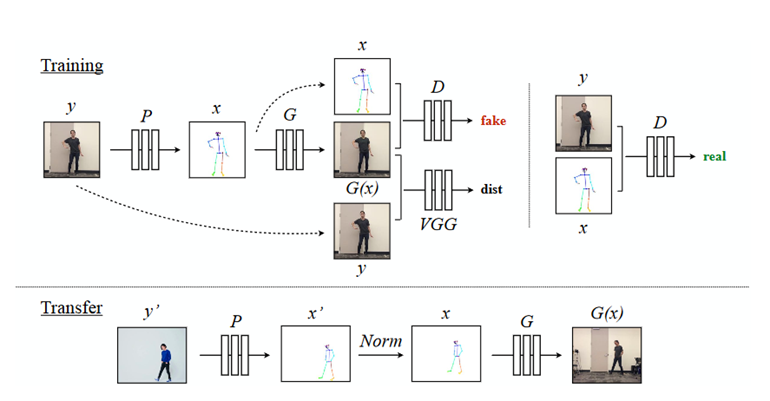
“Overall our model can create reasonable and arbitrarily long videos of a target person dancing given body movements to follow through an input video of another subject dancing,” the team said.
The researchers concede their model isn’t perfect. “Even though we try to inject temporal coherence through our setup and pre smoothing key points, our results often still suffer from jittering. Errors occur particularly in transfer videos when the input motion or motion speed is different from the movements seen at training time,” the team explained.
To address the issues the team is working on using a different pose estimation framework that is optimized for motion transfer.
The work was published on ArXiv this week.
Read more>
AI Can Transform Anyone Into a Professional Dancer

Aug 24, 2018
Discuss (0)
AI-Generated Summary
- Researchers from the University of California Berkeley developed a deep learning algorithm that allows users to mimic the dance moves of others by transferring their style onto the user's video.
- The team trained a conditional generative adversarial network using NVIDIA TITAN Xp and GeForce GTX 1080 Ti GPUs, and the cuDNN-accelerated PyTorch framework on videos of amateur dancers filmed at 120 frames per second.
- The model uses a pose detector to create pose stick figures and learns a mapping from pose images to a target subject's appearance, enabling users to dance like their favorite stars, such as Bruno Mars.
AI-generated content may summarize information incompletely. Verify important information. Learn more