
由于冠状病毒的存在, 2021 年韩国科学技术信息研究所( KISTI ) GPU 黑客大赛在 KISTI NVIDIA 和 OpenACC 组织的专家导师指导下举行。为了激发科学家加速 AI 研究或 HPC 代码的可能性, hackathon 提供了利用 NVIDIA GPU 并行计算技术解决研究问题和扩展专业知识的机会。
以面对面活动而闻名的虚拟黑客大会对与会者和主持人都提出了自己的挑战。新的模式还需要兼顾由三个 HPC 和 AI 团队、四个高等教育和研究团队以及两个行业团队组成的多样化团队。
活动团队发现以下配方有助于为参与者创造有意义的成功体验:
指导
基于他们在特定领域或编程语言方面的专业知识,专门的导师与团队一起进行指导,以设定目标,并考虑不同的方法。导师们合作解决团队遇到的问题并排除障碍。每天的导师同步电话让每个人都集中精力,朝着实现目标的最佳策略努力。
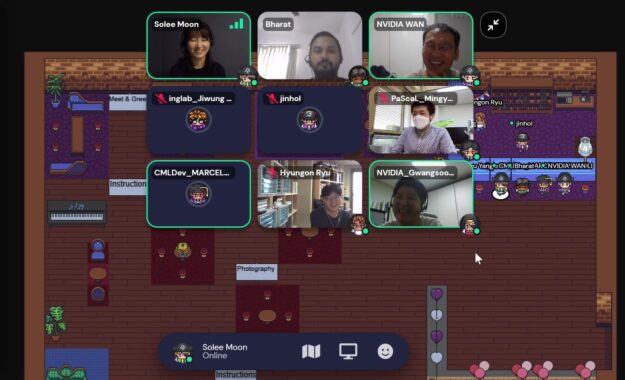
社交
每个人都知道,只工作不玩耍实际上会阻碍团队的生产力。 hackathon 为参与者和导师提供了 TGIF 社交时间会议。使用 Metaverse Gather 城镇空间,导师和团队分享经验,为电池充电,并建立联系,帮助他们在活动期间继续前进。
资源和现场研讨会
成功的另一个重要因素是为与会者提供专门的培训和资源。例如, NVIDIA 深度学习培训中心( DLI )的一位大使和导师介绍了一个涵盖 CUDA C / C ++主题的研讨会。其他导师提供了团队专用的技术课程,重点是TRT和 NVIDIA Triton 、OpenACC和 NSight 系统的评测、并行计算和优化。

努力工作是有回报的
延世大学的帕斯卡团队正在开发一种热流体解算器,该解算器可以有效地计算湍流的热运动。在这次黑客大会上,团队通过 OpenACC 和 cuFFT 库将基于 CPU 的现有代码转换为多 GPU 环境。这使得最耗时的子程序之一的计算速度加快了 4 . 84 倍 RHS (右侧,分步)。
来自 AmorePacific 化妆品公司的 Amore Opt 团队致力于 GPU 优化 DeepLabV3 +细分模型。通过应用他们对 TensorRT 推理优化器和 NVIDIA Triton 推理服务器的了解,他们提高了推理速度,使推理速度提高了 26 倍。他们做到了这一点,同时保持人工智能模型的准确性,以便为未来的大规模客户服务检测皮肤问题。
首尔国立大学的 TFC 团队参与了一个项目,以加速基于 CPU 的 Fortran 内部流体计算代码。通过在 KISTI 使用 NVIDIA GPU s ,团队加速了耗时的三对角矩阵算法( TDMA )用于热解算器和动量解算器,以及快速傅立叶变换( FFT )用于压力解算器计算。他们在一台 V100 GPU 上实现了 11 . 15 倍的速度。
NVIDIA Inception 成员 Nota 和杭阳大学合作,通过利用 NVIDIA GPU s 中的张量核进行 INT4 量化,优化了 Nota 模型压缩引擎。名为 NOTA-HYU 的团队学会了使用 NVIDIA 分析工具 NSight 系统和 NSight 计算。然后,他们应用 NVIDIA 库弯刀,通过 CUDA 优化,使剩余块的总体速度提高 1 . 85 倍。
有关 GPU 黑客大会和未来活动的更多信息,请访问https://www.gpuhackathons.org/
也不要错过 2021 年 9 月 14 日至 15 日的2021 年亚太经合组织首脑会议。




