
在设计基于机器学习的解决方案时,需要问的一个关键问题是,“开发此解决方案的资源成本是多少?”答案通常有很多因素:时间、开发人员技能和计算资源。很少有研究人员能够最大化所有这些方面,因此优化解决方案开发过程至关重要。这一问题在机器人技术中进一步加剧,因为每项任务通常都需要一个完全独特的解决方案,其中涉及到专家的大量手工制作。
典型的机器人解决方案需要数周甚至数月的时间来开发和测试。灵巧的多指物体操纵一直是机器人操纵控制和学习领域的一个长期挑战。有关更多信息,请参阅以下论文:
虽然在过去 5 年中,运动的高维控制以及基于图像的物体操作(使用简化的夹持器)方面的挑战取得了显著的进展,但多指灵巧操作仍然是一个影响巨大但难以解决的问题。这一挑战是由以下问题造成的:
- 高维协调控制
- 低效的仿真平台
- 实际机器人操作中观测和控制的不确定性
- 缺乏强健且经济高效的硬件平台
这些挑战加上缺乏大规模计算机和机器人硬件,限制了试图解决这些问题的团队的多样性。
我们在这项工作中的目标是通过大规模仿真和机器人即服务技术,为机器人学习的民主化提供一条道路和可行的解决方案。以灵巧多指机械手为例,重点研究了六自由度物体操纵。我们展示了在桌面级 GPU 和基于云的机器人技术上进行的大规模模拟如何使机器人专家能够利用有限的资源进行机器人学习方面的研究。
虽然在手工操作方面的一些努力试图构建健壮的系统,但最令人印象深刻的演示之一是几年前来自 OpenAI 的一个团队,该团队构建了一个名为Dactyl的系统。这是一个令人印象深刻的工程壮举,以实现多目标在手休息与阴影的手。
然而,它不仅在最终性能上,而且在构建此演示所需的计算量和工程工作量上都是引人注目的。据公众估计,它使用了 13000 年的计算机,硬件本身成本高昂,但需要反复干预。巨大的资源需求有效地阻止了其他人复制这一结果,并因此在这一结果的基础上再接再厉。
在这篇文章中,我们展示了我们的系统努力是解决这种资源不平等的途径。现在,使用单一的台式机等级 GPU 和 CPU ,在不到一天的时间内即可获得类似的结果。
强化学习中标准姿势表示的复杂性
在最初的实验中,我们遵循以前的工作,提供了基于三维笛卡尔位置加上四维四元数表示的姿势的观察,以指定立方体的当前和目标位置。我们还根据 L2 范数(位置)和立方体的期望姿势和当前姿势之间的角度差(方向)固定了奖励。有关更多信息,请参阅学习灵活性 OpenAI 帖子和 GPU – 分布式强化学习的加速机器人仿真。
我们发现这种方法会产生不稳定的奖励曲线,即使在调整相对权重后,它也能很好地优化奖励的位置部分。
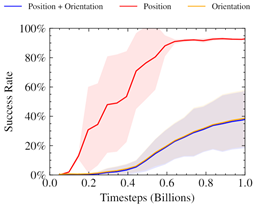
先前的工作已经证明了使用神经网络时空间旋转的交替表示的好处。此外,已经证明,这种方式的混合损失会导致只朝着优化单一目标的方向崩溃。该图表暗示了类似的行为,其中只有职位奖励被优化。
受此启发,我们在 SO ( 3 )中为我们的 6 自由度休息问题寻找姿势表示。这也会自然地通过强化学习以适合优化的方式权衡职位和轮换奖励。
使用远程机器人缩小 Sim2Real 差距
获得物理机器人资源的问题因新冠病毒 -19 大流行而加剧。那些之前有幸在他们的研究小组中接触到机器人的人发现,能够接触到机器人的人数大大减少了。那些依赖其他机构提供硬件的机构往往由于物理距离限制而完全疏远。
我们的工作证明了机器人即服务( RaaS )方法与机器人学习相结合的可行性。一小队接受过维护机器人培训的人员和另一队研究人员可以上传一份经过培训的政策,并远程收集数据进行后处理。
虽然我们的研究团队主要在北美,但物理机器人在欧洲。在整个项目期间,我们的开发团队从来没有和我们工作的机器人呆在同一个房间里。远程访问意味着我们无法改变手头的任务以使其更容易。它还限制了我们可以进行的迭代和实验的种类。例如,合理的系统识别是不可能的,因为我们的策略在整个 f ARM 中随机选择的机器人上运行。
尽管缺乏物理访问,但我们发现,我们能够通过多种技术的组合,制定出一个稳健且有效的策略来解决 6 自由度休息任务:
- 真实 GPU – 加速仿真
- 无模型 RL
- 域随机化
- 任务适当的姿势表示
方法概述
我们的系统使用 NVIDIA V100 或 NVIDIA NVIDIA 3090 RTX 在 16384 个环境中并行使用 GPU 健身房模拟器进行训练。然后,利用上传的演员权重,在位于德国大西洋彼岸的三指机器人上远程进行推理。我们执行 Sim2Real 传输的基础设施由真正的机器人挑战的组织者提供。
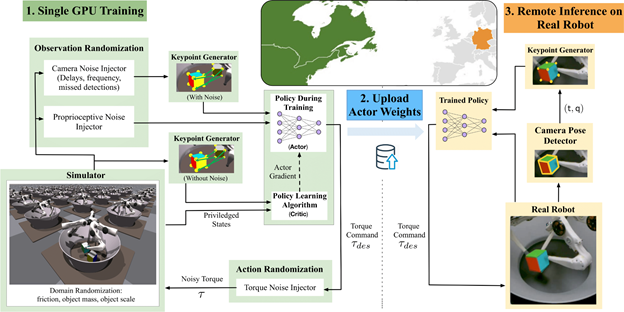
收集并处理培训示例
使用 ISAAC 健身房模拟器,我们收集了高通量体验( NVIDIA RTX 3090 上每秒约 10 万个样本)。样例的对象姿势和目标姿势与对象形状的八个关键点对应。将领域随机化应用于观测和环境参数,以模拟真实机器人和摄像机本体感受传感器的变化。这些观察结果,以及来自模拟器的一些特权状态信息,然后被用来训练我们的政策。
培训政策
我们的策略是使用近端策略优化( PPO )算法来最大化定制奖励。我们的奖励激励政策平衡机器人手指与物体的距离、移动速度以及从物体到指定目标位置的距离。它有效地解决了这项任务,尽管它是一种广泛适用于手部操作应用的通用公式。该策略输出每个机器人电机的扭矩,然后将其传回模拟环境。
将策略转移到真正的机器人并运行推理
在我们训练了策略之后,我们将其上传到真实机器人的控制器。这个立方体是用三个摄像头在系统上跟踪的。我们将系统提供的本体感知信息与转换的关键点表示结合起来,为策略提供输入。我们重复了基于摄像头的立方体姿势观察,以进行后续的策略评估,从而使策略能够利用机器人可用的更高频率本体感受数据。然后,从系统收集的数据用于确定策略的成功率。
机器人上的跟踪系统目前只支持立方体。然而,这在将来可以扩展到任意对象。
Results
姿势的关键点表示大大提高了成功率和收敛性。
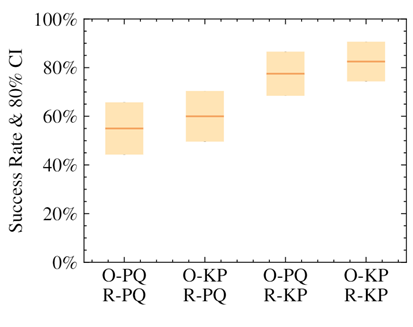
我们证明了使用我们的关键点表示法的策略,无论是在提供给策略的观察中还是在奖励计算中,都比使用位置+四元数表示法获得了更高的成功率。最高性能来自于对这两个元素使用替代表示的策略。
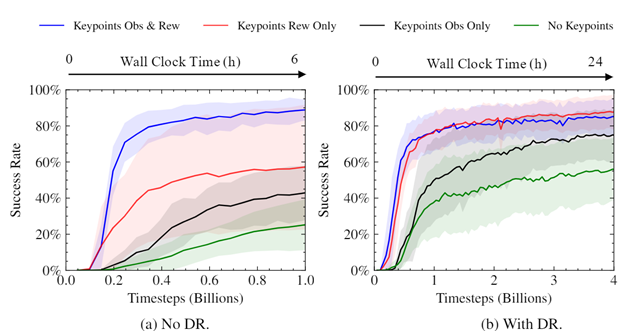
我们进行了实验,以了解关键点的使用如何影响我们经过训练的策略的速度和收敛水平。可以看出,使用关键点作为奖励的一部分大大加快了培训,提高了最终成功率,并减少了培训策略之间的差异。考虑到使用关键点作为奖励的一部分的简单性和普遍性,差异的大小令人惊讶。
经过培训的策略可以直接从模拟器部署到远程真实机器人(图 5 )。

图 6 显示了一种我们称之为“掉落和重新抓取”的紧急行为。在这个动作中,机器人学会在立方体接近正确位置时掉落立方体,重新抓取立方体,然后将其捡起来。这使得机器人能够在正确的位置稳定地抓住立方体,从而获得更成功的尝试。值得注意的是,这段视频是实时的,不会以任何方式加速。
机器人还学习利用立方体在竞技场中正确位置的运动,作为在地面上同时旋转立方体的机会。这有助于在远离手指工作区中心的挑战性目标位置实现正确抓取。

我们的政策也很稳健,有助于降低成本。机器人可以从一个从手上掉下来的立方体中恢复,并从地面上取回它。
对物理和物体变化的鲁棒性
我们发现,我们的策略对模拟中环境参数的变化具有鲁棒性。例如,它优雅地处理了立方体的上下缩放,其范围远远超过了随机化。


令人惊讶的是,我们发现我们的策略能够将 0-shot 推广到其他对象,例如长方体或球。
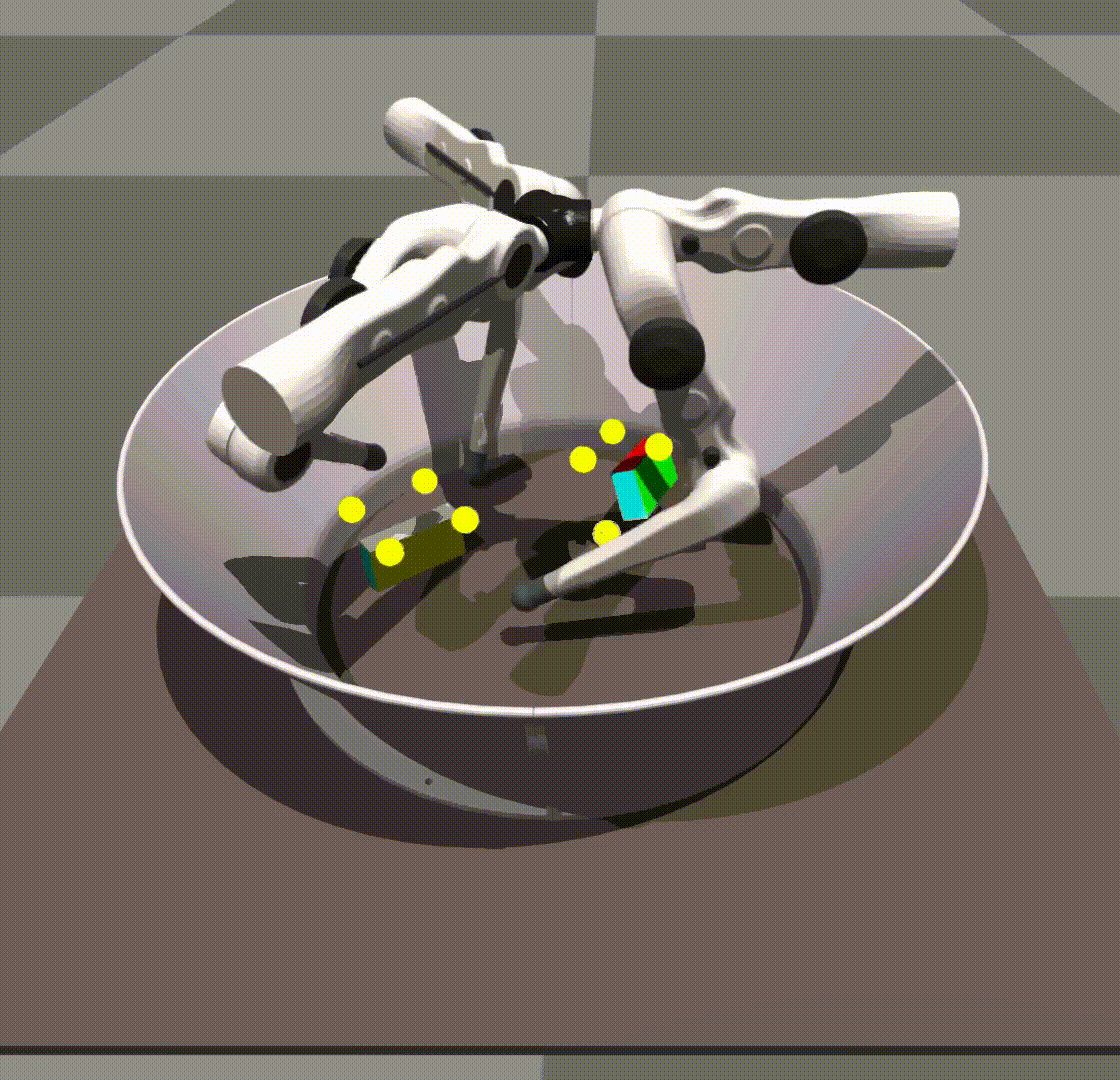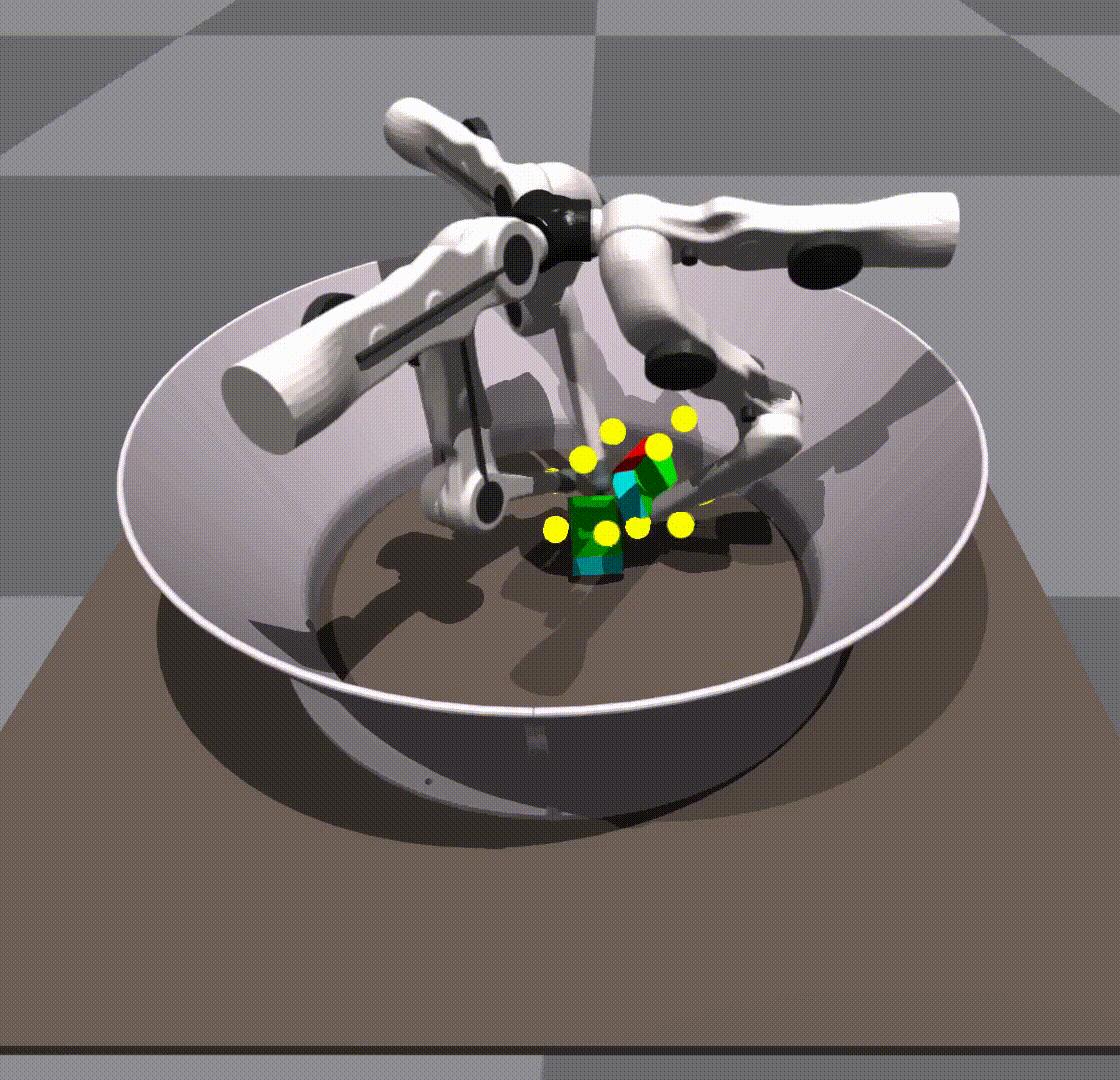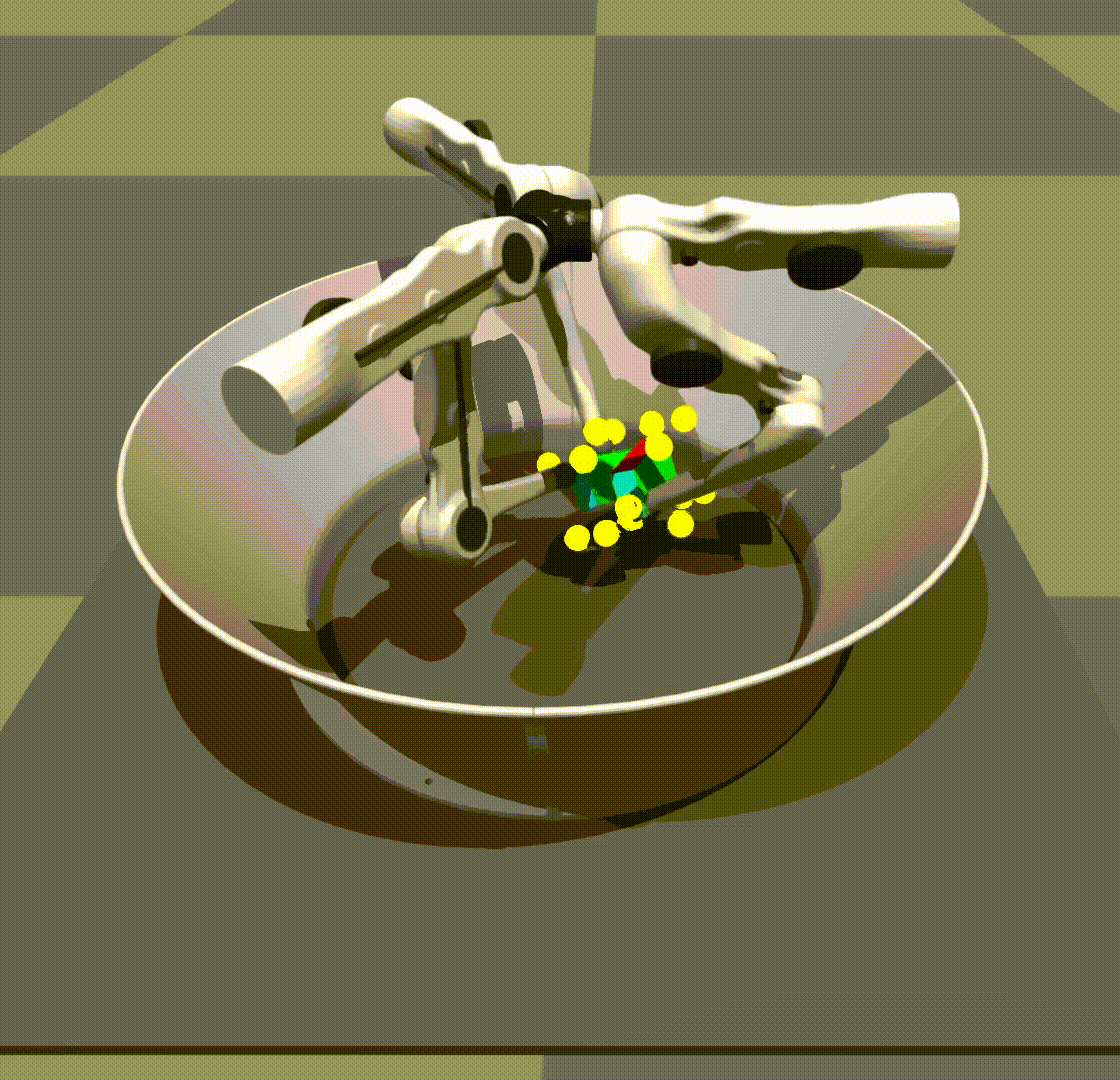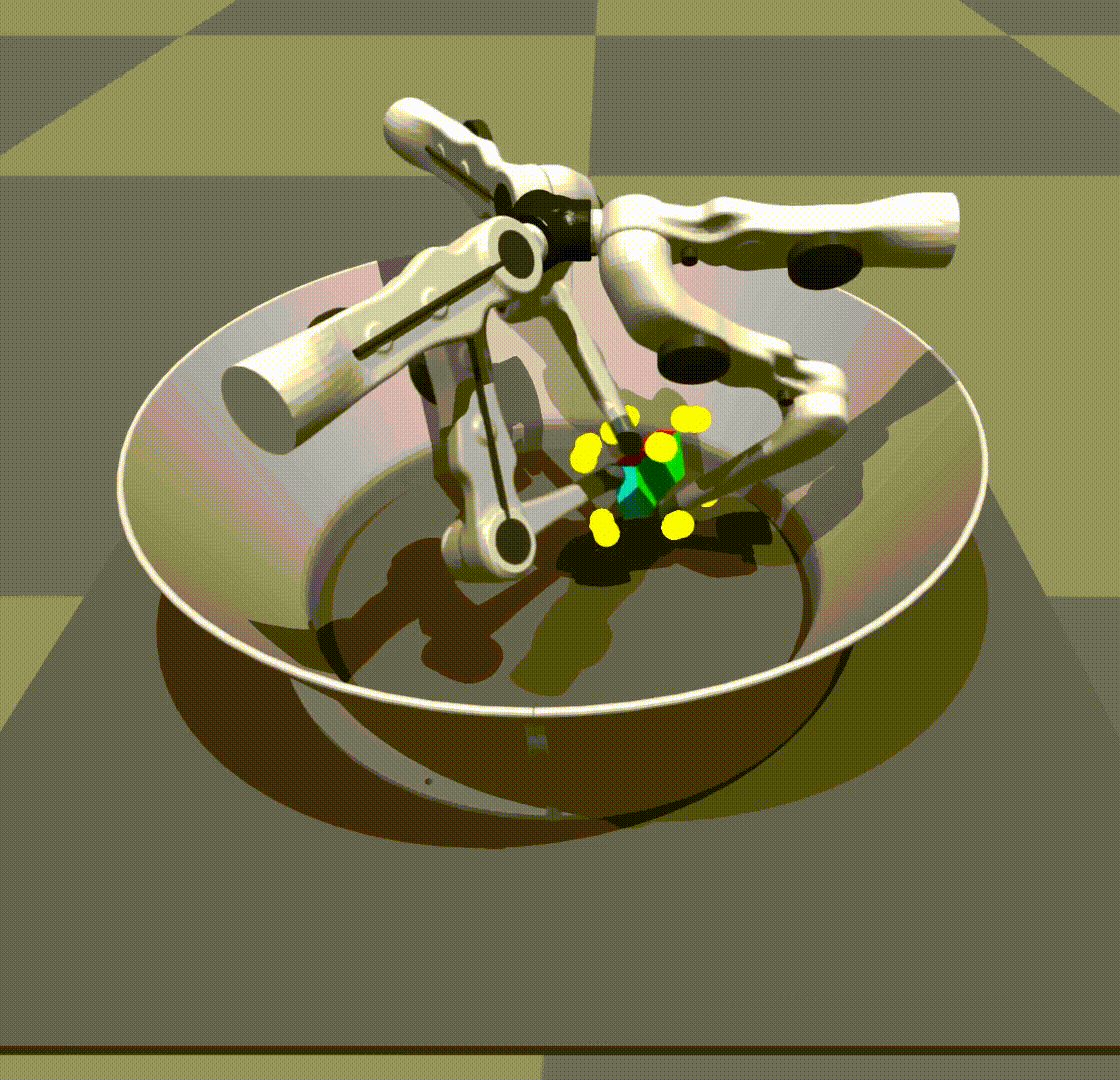

由于策略自身的健壮性,在规模和对象上进行了泛化。我们不给它任何形状信息。关键点保持在立方体上的相同位置。

结论
我们的方法通过基于 GPU 的大规模仿真展示了一条可行的机器人学习路径。在本文中,我们向您展示了如何使用中等水平的计算资源(桌面级计算)来训练策略,并将其传输到远程机器人。我们还表明,这些策略对环境和被操纵对象中的各种变化具有鲁棒性。我们希望我们的工作能够成为研究人员向前迈进的平台。
NVIDIA 还宣布广泛支持具有开放机器人技术的机器人操作系统( ROS )。这一重要的 ISAAC ROS 公告强调了 NVIDIA 人工智能感知技术如何加速人工智能在 ROS 社区的应用,以帮助机器人专家、研究人员和机器人用户开发、测试和管理下一代基于人工智能的机器人。
有关这项研究的更多信息,请参阅将 GPU 模拟中的灵巧操作转移到远程真实世界的三指手指 GitHub 页面,其中包含指向whitepaper的链接。要了解更多关于 NVIDIA 机器人研究以及 NVIDIA 开发者社区正在进行的工作,请免费注册 NVIDIA GTC 。
致谢
这项工作由多伦多大学与 NVIDIA 、向量研究所、 MPI 、 ETH 和 Snap 合作领导。我们要感谢 Vector Institute 对计算的支持,以及 CIFAR AI 主席对 Animesh Garg 的研究支持。




