这篇文章讨论了张量方法,它们是如何在 NVIDIA 中使用的,以及它们是如何成为下一代人工智能算法的核心。
现代机器学习中的张量
张量将矩阵推广到二维以上,在现代机器学习中无处不在。从深层神经网络特征到视频或功能磁共振成像数据,这些高阶张量的结构往往至关重要。
深度神经网络通常在高阶张量之间映射。事实上,正是深层卷积神经网络保持和利用局部结构的能力,使得当前的性能水平以及大数据集和高效硬件成为可能。张量方法使您能够为单个层或整个网络进一步保留和利用该结构。
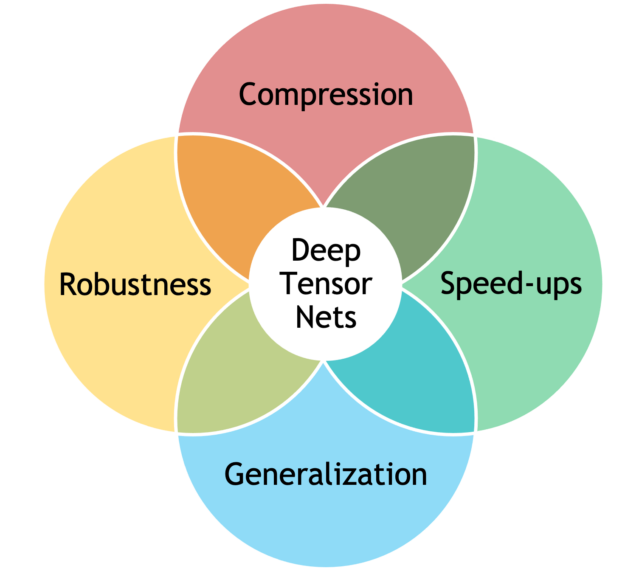
将张量方法与深度学习相结合可以产生更好的模型,包括:
- 通过更好的归纳偏差,实现更好的性能和通用性
- 通过隐式(低秩结构)或显式(张量衰减)正则化改进鲁棒性
- 简约模型,参数数量大幅减少
- 通过直接有效地操作因式化张量,提高了计算速度
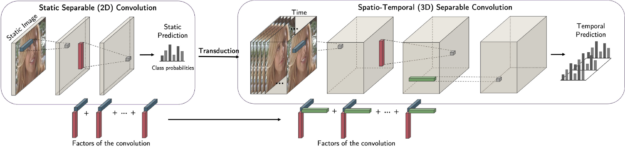
一个例子是因式卷积。使用 CP 结构,可以分解卷积的核并将其高效地表示为可分离的核。这将解耦尺寸标注并使您能够转换,例如在二维上进行培训,并在利用二维中学习到的信息的同时将其推广到三维。
基于张量的深度神经网络的正确实现可能很棘手。主要的神经网络库,如 PyTorch 或 TensorFlow 不提供基于张量代数方法的层,并且对稀疏张量的支持有限。在 NVIDIA 中,我们通过 TensorLy 项目和 Minkowski 引擎,领导开发了一系列工具,以使张量方法在深度学习中无缝使用。
张力生态系统
TensorLy 为张量方法提供了一个高级 API ,包括分解和代数。
它使您能够轻松地使用张量方法,而不需要大量的背景知识。您可以选择并无缝集成您选择的计算后端( NumPy 、 PyTorch 、 MXNet 、 TensorFlow 、 CuPy 或 JAX ),而无需更改代码。
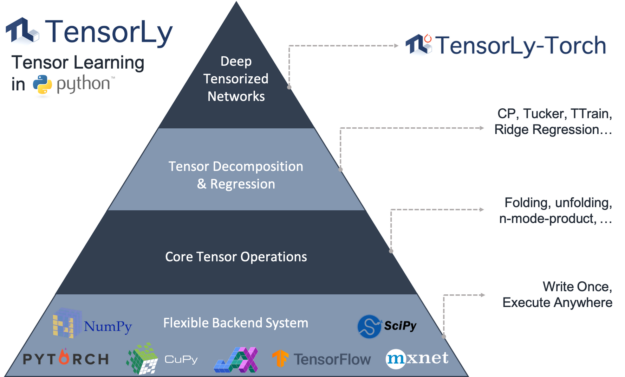
TensorLy Torch 是一个新的库,它构建在 TensorLy 之上,并提供实现这些 tensor 操作的 PyTorch 层。它们可以开箱即用,并且很容易集成到任何深度神经网络中。它的核心是因式分解张量的概念:张量以分解形式直接表示、存储和操作。只要可能,操作就直接对这些分解的张量进行操作。
这些因子化张量可用于有效地参数化深层神经网络层,如因子化卷积和线性层。最后,张量挂钩使您能够无缝地应用诸如广义套索和张量衰减等技术,以提高泛化和健壮性。
空间稀疏张量与 Minkowski 引擎
在许多高维问题中,随着空间体积的增加,数据变得稀疏。稀疏性主要嵌入在空间维度中,您可以在其中计算距离。这种稀疏性最著名的例子是 3D 数据,如网格和扫描。

下面是一个有两张床的房间的三维重建示例。它所占用的三维边界体积可能相当大,但数据或三维曲面重建只占用空间的一小部分。在本例中, 95.5% 的空间为空,小于 5% 的空间包含有效曲面。如果要处理此类数据,使用稠密张量表示此类数据不仅会浪费大量内存,还会浪费计算量。
在这种情况下,您可以使用稀疏表示法来构建神经网络或学习算法,该表示法不会在空白空间浪费内存和计算。具体来说,您可以使用稀疏张量表示此类数据,这是稀疏数据最广泛使用的表示形式之一。稀疏张量使用一对非零值的位置和值表示数据。
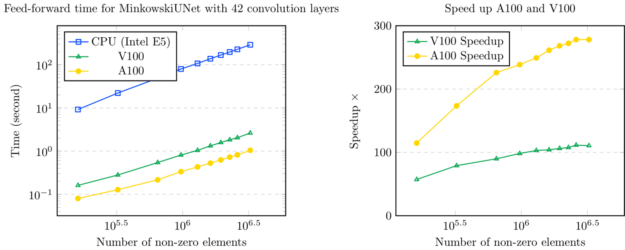
Minkowski 发动机是 PyTorch 的扩展,它为稀疏张量提供了一组广泛的神经网络层。 Minkowski 发动机中的所有功能都支持 CPU 和 CUDA 操作,其中 CUDA 操作在 CPU s 生产线顶部加速超过 100 倍。
有关其他有趣的项目,请参见所有 NVIDIA 研究岗位。