想象一下在机场等你的航班。突然,一个重要的商务电话与一个高姿态的客户点亮了你的手机。大量的背景噪音使你周围的声音变得杂乱无章——背景嘈杂,飞机起飞,也许是飞行通告。你必须接电话,而且你要听清楚。
我们都曾处于这种尴尬、不理想的境地。这只是现代商业的一部分。
背景噪音无处不在。这很烦人。
现在想象一下,当你接电话说话时,噪音神奇地消失了,而另一端所有人能听到的都是你的声音。没有声音的低语穿过。
我们的激情代表着我们的愿景。让我们听听好的降噪效果。
两年前,我们坐下来,决定开发一种技术,可以完全消除人与人之间交流中的背景噪音,使之更加愉悦和易懂。从那时起,这个问题就成了我们的困扰。
让我们看看是什么让噪声抑制如此困难,构建实时低延迟噪声抑制系统需要什么,以及深度学习如何帮助我们将质量提升到一个新的水平。
噪声抑制技术的现状
让我们弄清楚什么是噪音抑制。乍一看,这似乎令人困惑。
本文中的噪声抑制是指抑制从 你的 背景到您正在通话的人的噪声,以及来自 他们的 背景的噪声,如图 1 所示。
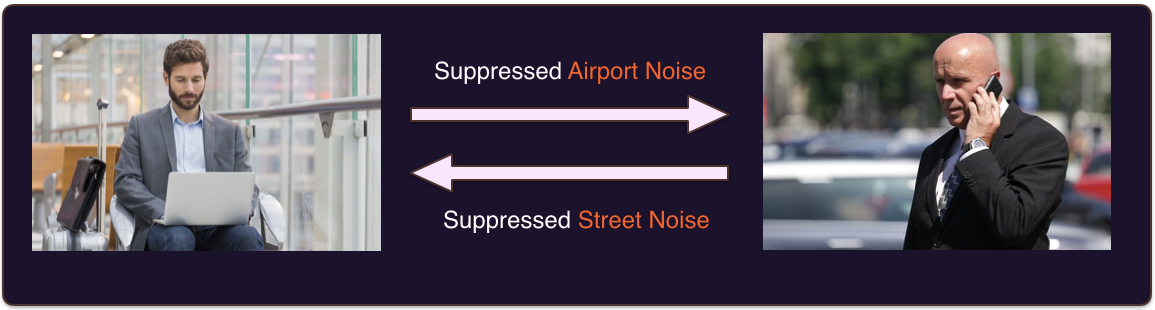
这与 有源噪声消除 相反, VZX23 指的是抑制来自周围环境的不必要的噪音。主动噪声消除通常需要多麦克风耳机(如 BoseQuiteComfort ),如图 2 所示。
这篇文章的重点是噪声抑制, 不 主动噪声消除。
传统的噪声抑制方法
传统的噪声抑制已经在边缘设备上得到了有效的实现,如电话、笔记本电脑、会议系统等。这似乎是一种直观的方法,因为它是边缘设备,首先捕捉用户的声音。一旦捕获,设备过滤掉噪音,并将结果发送到呼叫的另一端。
10 年前的手机通话体验相当糟糕。一些移动电话仍然如此;然而,更现代的手机配备了多个麦克风( mic ),这有助于在通话时抑制环境噪音。
如图 2 所示,当前一代手机包括两个或两个以上的麦克风,最新的 iPhone 有 4 个。第一个麦克风放在手机的前底部,最靠近用户说话时的嘴,直接捕捉用户的声音。手机设计师将第二个麦克风放置在离第一个麦克风尽可能远的地方,通常放在手机的上背部。
两个麦克风都能捕捉周围的声音。靠近嘴的麦克风捕捉到更多的声音能量;第二个麦克风捕捉的声音更少。软件有效地将这些信息相互抵消,产生(几乎)干净的声音。
这听起来很简单,但很多情况下都存在这种技术失败的情况。想象一下,当这个人不说话,而麦克风听到的只是噪音。或者想象这个人在说话的时候,比如跑步的时候,正在积极地摇晃/转动手机。处理这些情况很棘手。
对于设备原始设备制造商和 ODM 来说,两个或更多的麦克风也使得音频路径和声学设计变得相当困难和昂贵。音频/硬件/软件工程师必须实施次优权衡,以支持工业设计和语音质量要求…
考虑到这些困难,今天的手机在中等噪音的环境中表现得相当好。。现有的噪声抑制解决方案并不完美,但确实提供了改进的用户体验。
如图 3 所示,使用分离式话筒时,外形因素会起作用。第一个和第二个麦克风之间的距离必须满足最低要求。当用户把手机放在耳朵和嘴上说话时,效果很好。
然而,现代手机的“棒棒糖”外形可能不会长期存在。可穿戴设备(智能手表、胸前的麦克风)、笔记本电脑、平板电脑和 Alexa 等智能语音助手颠覆了平板手机的外形。用户从不同的角度和不同的距离与他们的设备交谈。在大多数情况下,没有可行的解决办法。噪音抑制只是失败了。
从多话筒设计转向单话筒设计
多麦克风设计有几个重要的缺点。
- 它们需要一定的外形尺寸,使其仅适用于特定的使用场合,例如带有粘性麦克风的电话或耳机(专为呼叫中心或入耳式监听器设计)。
- 多麦克风设计使得音频路径变得复杂,需要更多的硬件和代码。此外,为二次麦克风钻孔带来了工业 ID 质量和产量问题。
- 只能在边缘或设备侧处理音频。因此,由于低功耗和计算需求,支持它的算法并不十分复杂。
现在想象一个解决方案,你只需要一个麦克风,所有的后处理都由软件处理。这使得硬件设计更加简单和高效。
事实证明,在音频流中分离噪声和人类语言是一个具有挑战性的问题。此函数不存在高性能算法。
传统的数字信号处理( DSP )算法通过逐帧处理音频信号,不断地寻找噪声模式并加以适应。这些算法在某些用例中运行良好。然而,它们并不能适应我们日常环境中存在的噪音的多样性和可变性。
存在两种基本噪声类型: 固定的 和 非静止 ,如图 4 所示。
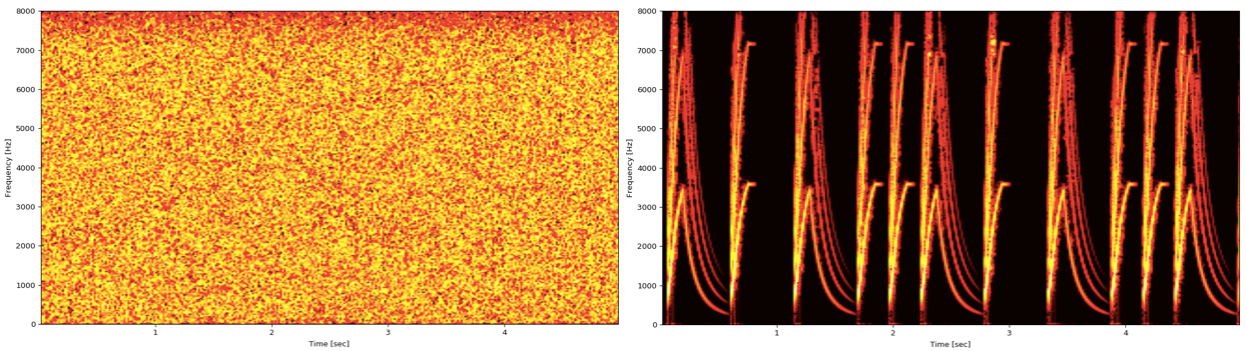
把静止的噪音想象成一种可重复但又不同于人声的声音。传统的 DSP 算法(自适应滤波器)可以很有效地滤除这些噪声。
非平稳噪声具有复杂的模式,很难与人的声音区分开来。信号可能很短,来去非常快(例如键盘输入或警报器)。有关技术上更正确的定义,请参阅此 Quora 文章 。
如果你想同时战胜静止和非静止噪声,你需要超越传统的 DSP 。在 2Hz ,我们相信深度学习可以成为处理这些困难应用的重要工具。
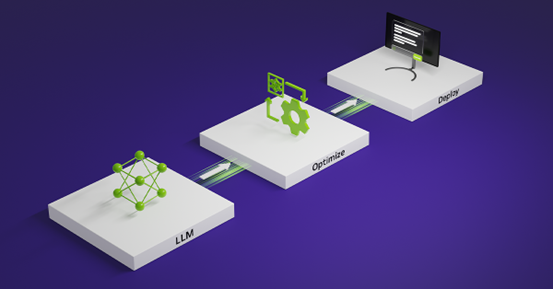
用深度学习分离背景噪声
关于将深度学习应用于噪声抑制的一篇基础论文似乎是 2015 年徐勇著 。
Yong 提出了一种回归方法来学习为每个音频频率生成一个比率掩码。所产生的比率掩模可以使人的声音保持完整,并删除外来噪音。虽然远不是完美的,但这是一个很好的早期方法。
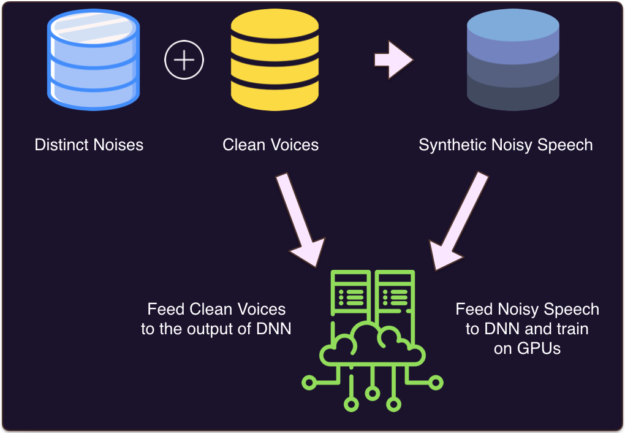
在随后的几年里,许多不同的方法被采用;高级方法几乎总是相同的,包括三个步骤,如图 5 所示:
- 数据收集 :将干净语音与噪声混合生成大数据集
- 培训 :在输入时将此数据集馈送给 DNN ,在输出时向 DNN 提供干净的语音
- 推论 :生成一个掩模(二进制、比率或复合),它将离开人声并过滤掉噪声
在 2Hz 频率下,我们用不同的 DNN 进行了实验,并提出了我们独特的 DNN 架构,可以对各种噪声产生显著的效果。在嘈杂的演讲中,平均 MOS 评分 (平均意见得分)提高了 1 . 4 分,这是我们看到的最好的结果。这一结果令人印象深刻,因为在单个麦克风上运行的传统 DSP 算法通常 减少 的 MOS 分数。
语音延迟。实时 DNN 可能吗?
低延迟是语音通信的关键。人类在交谈时可以忍受长达 200 毫秒的端到端延迟,否则我们会在通话中互相交谈。潜伏期越长,我们就越注意到它,也就越恼火。
有三个因素会影响端到端延迟:网络、计算和编解码器。通常网络延迟的影响最大。编解码器的延迟在 5-80ms 之间,这取决于编解码器及其模式,但现代编解码器已经变得相当高效。计算延迟实际上取决于很多因素。
计算延迟使 dnn 具有挑战性。如果你想用 DNN 来处理每一帧,你就有可能引入大的计算延迟,这在现实的部署中是不可接受的。
根据不同的延迟因素计算:
计算平台能力
在耳机里运行一个大的 DNN 不是你想做的事情。有 CPU 和功率限制。实现实时处理速度是非常具有挑战性的,除非平台有一个加速器,它可以使矩阵乘法更快、更低的功耗。
DNN 体系结构
DNN 的速度取决于你有多少个超参数和 DNN 层,以及你的节点运行什么操作。如果你想用最小的噪声产生高质量的音频,你的 DNN 不能很小。
例如, Mozilla rnnoise 非常快, 也或许可以放入耳机中。然而,它的质量并不令人印象深刻的非平稳噪声。
音频采样率
DNN 的性能取决于音频采样率。采样率越高,需要提供给 DNN 的超参数就越多。
相比之下, Mozilla rnnoise 使用分组频率的频带,因此性能对采样率的依赖最小。虽然这是一个有趣的想法,但这对最终质量有不利影响。
窄带 音频信号( 8kHz 采样率)质量较低,但我们的大多数通信仍在窄带中进行。这是因为大多数移动运营商的网络基础设施仍然使用窄带编解码器对音频进行编码和解码。
由于窄带每个频率需要较少的数据,因此它可以成为实时 DNN 的一个良好的起始目标。但是当你需要增加对宽带或超宽带( 16kHz 或 22kHz )和全频段( 44 . 1 或 48kHz )的支持时,事情变得非常困难。如今,许多基于 VoIP 的应用都在使用宽带,有时甚至使用全频段编解码器(开源的 Opus 编解码器支持所有模式)。
在一个天真的设计中,你的 DNNMIG ht 要求它增长 64 倍,因此要支持全频段,就要慢 64 倍。
如何测试噪声抑制算法?
测试语音增强的质量很有挑战性,因为你不能相信人的耳朵。由于年龄、训练或其他因素,不同的人有不同的听力能力。不幸的是,没有开放的和一致的噪声抑制基准,所以比较结果是有问题的。
大多数学术论文使用 渔业 、 莫斯 和 表 来比较结果。你向算法提供原始语音音频和失真音频,它会生成一个简单的度量分数。例如, PESQ 分数在 -0 . 5-4 . 5 之间,其中 4 . 5 是一个非常干净的演讲。不过, PESQ 、 MOS 和 STOI 还没有被设计成额定噪声级,所以你不能盲目相信它们。在你的过程中你也必须进行主观测试。
ETSI 室。
一种更专业的方法来进行主观音频测试并使其具有可重复性,就是满足不同标准机构制定的此类测试标准。
3GPP 电信组织定义了 ETSI 室的概念。如果您打算将您的算法部署到现实世界中,您必须在您的设施中有这样的设置。 ETSI 室是构建可重复和可靠测试的良好机制;图 6 显示了一个示例。

这个房间隔音效果很好。它通常还包括一个人造的人体躯干,一个在躯干内模拟声音的人造嘴(一个扬声器),以及一个预先设定好的距离的具有麦克风功能的目标设备。
这使测试人员能够使用周围的扬声器模拟不同的噪音,播放“躯干扬声器”的声音,并在目标设备上捕获结果音频并应用您的算法。所有这些都可以编写脚本来自动化测试。
出站噪声与入站噪声
噪音抑制真的有很多 阴影 。
假设您正在与您的团队参加电话会议。包括你在内,有四个参与者在通话中。现在混音中可能有四种潜在的噪音。每个人都把背景噪音传给别人。
传统上,噪声抑制是在边缘设备上进行的,这意味着噪声抑制与麦克风有关。你从麦克风那里得到信号,抑制噪音,然后把信号传送到上游。
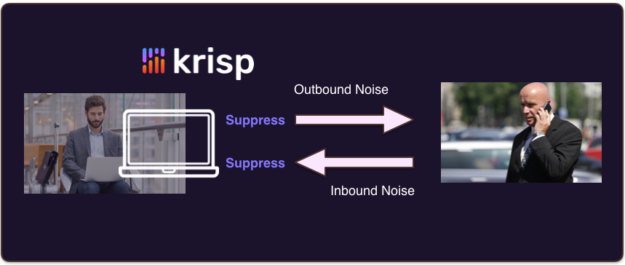
由于单个 mic DNN 方法只需要一个源流,所以您可以将它放在任何地方。现在,假设您希望抑制所有参与者发出的麦克风信号( 出站噪声 )和扬声器信号( 进站噪声 )。
我们构建了我们的应用程序 克里斯普。 ,明确地处理入站和出站噪声(图 7 )。
下面的视频演示如何使用 DNN 完全消除非平稳噪声。
对于入站噪声抑制,问题变得更加复杂。
你需要处理声音和声音的变化,这不是噪声抑制算法的典型特征。例如,您的团队 MIG 可能正在使用会议设备,并且坐在远离该设备的地方。这意味着到达设备 MIG 的语音能量更低。或者他们在车上用 iPhone 在仪表板上给你打电话,这是一个固有的高噪音环境,由于与扬声器的距离较远,声音很低。在另一种情况下,多人同时讲话,你希望保留所有的声音,而不是将其中的一些声音作为噪音加以抑制。
当您拨打 Skype 电话时,您会听到扬声器中的来电铃声。那响声是不是噪音?或者说“保留音乐”是不是一种噪音?我把它留给你。
向云端移动
到目前为止,您应该已经对噪声抑制的最新技术有了一个坚实的概念,以及为此目的而使用的实时深度学习算法所面临的挑战。您还了解了关键的延迟要求,这些要求使问题更具挑战性。你的噪声抑制算法所增加的总延迟不能超过 20 毫秒,这确实是一个上限。
由于该算法完全基于软件,它是否可以迁移到云端,如图 8 所示?
答案是肯定的。首先,基于云的噪声抑制适用于所有设备。其次,它可以在两条线路(或电话会议中的多条线路)上执行。我们认为噪音抑制和其他语音增强技术可以转移到云端。这在过去是不可能的,因为多麦克风的要求。移动运营商已经制定了各种质量标准,设备原始设备制造商必须执行这些标准才能提供正确的质量水平,迄今为止的解决方案是多个麦克风。然而,深度学习使得在支持单麦克风硬件的同时,能够在云端抑制噪声。
最大的挑战是算法的可扩展性。
使用 NVIDIA GPUs 缩放 20 倍
如果我们希望这些算法能够扩展到足以服务于真实的 VoIP 负载,我们需要了解它们的性能。
大型 VoIP 基础设施可同时服务于 10K-100K 流。我们认识的一家 VoIP 服务提供商在一台裸机媒体服务器上提供 3000 个 G . 711 呼叫流,这是相当令人印象深刻的。
有许多因素影响媒体服务器(如 FreeSWITCH )可以同时提供多少音频流。一个明显的因素是服务器平台。与裸机优化部署相比,云部署的媒体服务器提供的性能要低得多,如图 9 所示。
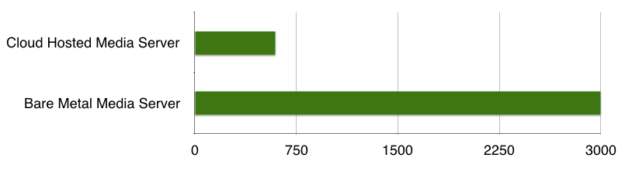
服务器端噪声抑制必须是经济高效的,否则没有客户想要部署它。
我们在 2Hz 下的第一个实验是从 CPU s 开始的。一个 CPU 核心可以处理多达 10 个并行流。这不是一个非常划算的解决方案。
然后我们在 GPUs 上进行了实验,结果令人吃惊。单个 NVIDIA 1080ti 可以在没有任何优化的情况下扩展到 1000 个流(图 10 )。在正确的优化之后,我们看到了扩展到 3000 个流;更多的可能是可能的。
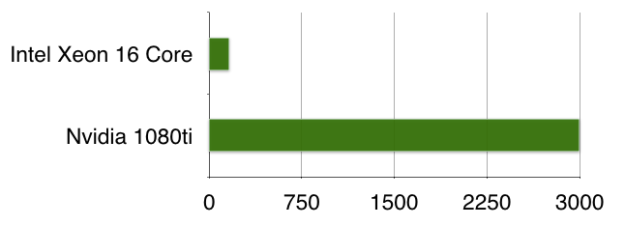
原始媒体服务器加载,包括处理流和编解码器解码仍然发生在 CPU 上。使用 GPUs 的另一个好处是,只需将一个外部 GPU 连接到您的媒体服务器盒,并将噪声抑制处理完全卸载到它身上,而不会影响标准音频处理管道。
用 CUDA 配料
让我们来看看为什么 GPU 比 CPU 更好地扩展这类应用程序。
CPU 传统上,供应商在优化和加速单线程体系结构方面花费了更多的时间和精力。他们实现了算法、过程和技术,尽可能地从单个线程中压缩速度。由于过去大多数应用程序只需要一个线程, CPU 制造商有充分的理由开发架构来最大化单线程应用程序。
另一方面, GPU 供应商针对需要并行性的操作进行了优化。这源于三维图形处理的大规模并行需求。 GPUs 的设计使其成千上万的小内核在高度并行的应用程序中工作良好,包括矩阵乘法。
批处理是允许并行化 GPU 的概念。您将成批的数据和操作发送到 GPU ,它并行地处理它们并发送回。这是处理并发音频流的完美工具,如图 11 所示。
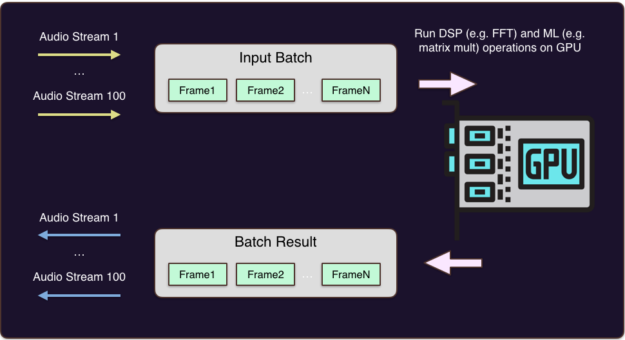
我们使用了 NVIDIA 的 CUDA 库 直接在 NVIDIA GPUs 上运行应用程序并执行批处理。下面的代码片段使用 CUDA 执行矩阵乘法。
void kernelVectorMul(RealPtr dst, ConstRealPtr src1, ConstRealPtr src2, const size_t n) { const size_t i = threadIdx.x + blockIdx.x * blockDim.x; if (i < n) dst[i] = src1[i] * src2[i]; } void Utils::vectorMul(RealPtr dst, ConstRealPtr src1, ConstRealPtr src2, const size_t n) { dim3 gridSize(n / getDeviceMaxThreadsX() + 1, 1, 1); dim3 blockSize(getDeviceMaxThreadsX(), 1, 1); kernelVectorMul <<< gridSize, blockSize >>> (dst, src1, src2, n); } void Utils::vectorMul(Vector& dst, const Vector& src1, const Vector& src2) { vectorMul(dst.getData(), src1.getData(), src2.getData(), dst.getSize()); } void Utils::matrixMulRowByRow(Matrix& dst, const Matrix& src1, const Matrix& src2) { vectorMul(dst.getData(), src1.getData(), src2.getData(), dst.getSize()); }
下面的代码使用 CUDA 执行 快速傅里叶变换 。
FFT::StatusType FFT::computeBackwardBatched(ComplexTypePtr src, RealTypePtr dst) { StatusType s = cufftExecC2R(backward_handle_, reinterpret_cast<cufftComplex*>(src), dst); dim3 gridSize((getBatchSize() * getForwardDataSize()) / thr_max_ + 1, 1, 1); dim3 blockSize(thr_max_, 1, 1); float val = getForwardDataSize(); kernelDivide <<< gridSize, blockSize >>> (dst, val, getBatchSize() * getForwardDataSize()); return s; } FFT::StatusType FFT::computeBackwardBatched(ComplexVector& src, Vector& dst) { return computeBackwardBatched(src.getData(), dst.getData()); }
下载用于 Mac 的 Krisp
如果你想在你的 Mac 上尝试基于深度学习的噪音抑制——你可以用 Crisp 应用程序 来做。
下一步是什么?
音频是一个令人兴奋的领域,而噪声抑制只是我们在太空中看到的问题之一。深度学习将带来新的音频体验,在 2Hz 频率下,我们坚信深度学习将改善我们的日常音频体验。在 修复语音中断 和 高清语音播放 的博客文章中可以找到这样的体验。