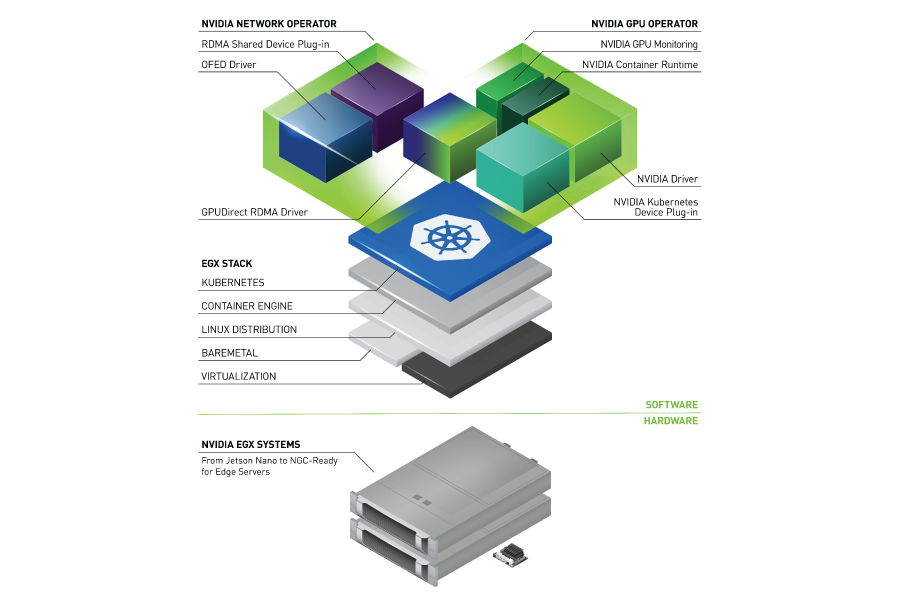
在 Kubernetes 中使用 GPU 可靠地配置服务器可能很快变得复杂,因为必须安装和管理多个组件才能使用 GPU。 GPU 运营商基于运营商框架,简化了 GPU 服务器的初始部署和管理。 NVIDIA , Red Hat 和社区中的其他人合作创建了 GPU 运营商。
要在 Kubernetes 群集中配置 GPU 工作节点,需要以下 NVIDIA 软件组件:
- NVIDIA driver
- NVIDIA 容器工具包
- Kubernetes 设备插件
- Monitoring
这些组件应该在 GPU 资源可用于集群之前进行配置,并在集群操作期间进行管理。
GPU 操作员通过将所有组件封装起来,简化了组件的初始部署和管理。它使用标准的 kubernetes api 来自动化和管理这些组件,包括版本控制和升级。 GPU 操作符是完全开源的。它在 NGC 上提供,并且是 NVIDIA EGX Stack 和 Red Hat OpenShift 的一部分。
最新的 GPU 操作员版本 1 . 6 和 1 . 7 包括几个新功能:
- 支持使用 NVIDIA 安培体系结构产品自动配置 MIG 几何图形
- 支持预安装的 NVIDIA 驱动程序和 NVIDIA 容器工具包
- 更新了对 Red Hat OpenShift 4 . 7 的支持
- 更新了 GPU 驱动程序版本,包括对 NVIDIA A40 、 A30 和 A10 的支持
- 使用 Containerd 支持 RuntimeClass
多实例 GPU 支持
多实例 GPU ( MIG )扩展了每个 NVIDIA A100 TensorCore GPU 的性能和价值。 MIG 可以将 A100 或 A30 GPU 划分为多达七个实例( A100 )或四个实例( A30 ),每个实例都用自己的高带宽内存、缓存和计算核心完全隔离。
如果没有 MIG ,在同一 GPU 上运行的不同作业(如不同的 AI 推断请求)将争夺相同的资源(如内存带宽)。使用 MIG ,作业在不同的实例上同时运行,每个实例都有专用的计算、内存和内存带宽资源。这将产生可预测的性能、服务质量和最大 GPU 利用率。因为同时作业可以操作, MIG 是边缘计算用例的理想选择。
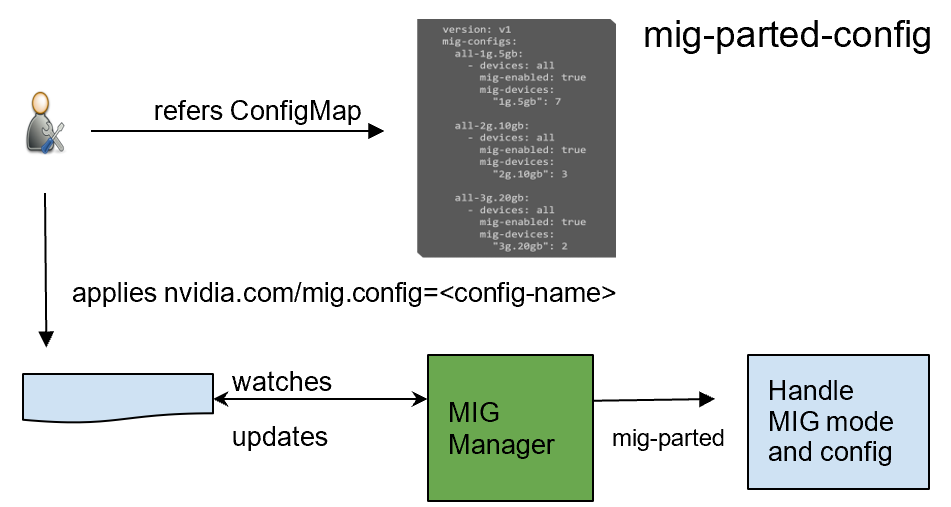
GPU Operator 1 . 7 添加了一个名为 NVIDIA MIG Kubernetes Manager, 的新组件,它作为守护程序运行,管理每个节点上的 MIG 模式和 MIG 配置更改。您可以在节点上应用 MIG 配置,方法是添加一个指示要应用的预定义配置名称的标签。应用 MIG 配置后, GPU 运算符自动验证是否按预期应用了 MIG 更改。有关详细信息,请参阅 GPU Operator 与 MIG 。
预装驱动程序和容器工具包
GPU Operator 1 . 7 现在支持有选择地安装 NVIDIA 驱动程序和容器工具包(容器配置)组件。这个新特性为预安装驱动程序或 nvidia-docker2 包的环境提供了极大的灵活性。这些环境现在可以使用 GPU 操作符简化对其他软件组件的管理,如设备插件、 GPU 功能发现插件、用于监视的 DCGM 导出器或用于 Kubernetes 的 MIG 管理器。
只预装驱动程序的 Install 命令:
helm install --wait --generate-name \ nvidia/gpu-operator \ --set driver.enabled=false
预装驱动程序和 nvidia-docker2 的 Install 命令:
helm install --wait --generate-name \ nvidia/gpu-operator \ --set driver.enabled=false --set toolkit.enabled=false
增加了对 Red Hat OpenShift 的支持
我们继续支持 Red Hat OpenShift ,
- GPU Operator 1 . 6 和 1 . 7 支持最新的 Red Hat OpenShift 4 . 7 版本。
- GPU 运算符 1 . 5 支持 Red Hat OpenShift 4 . 6 。
- GPU 操作符 1 . 4 和 1 . 3 分别支持 Red Hat OpenShift 4 . 5 和 4 . 4 。
GPU 操作员是经过 OpenShift 认证的操作员。通过 OpenShift web 控制台,只需单击几下鼠标即可安装并开始使用 GPU 操作符。作为一名经过认证的操作员,使用 NVIDIA GPU s 和 Red Hat OpenShift 非常容易。
GPU 对 NVIDIA A40 、 A30 和 A10 的驱动程序支持
我们更新了 GPU 驱动程序版本,包括对 NVIDIA A40 、 A30 和 A10 的支持。
NVIDIA A40
NVIDIA A40 提供了设计师、工程师、艺术家和科学家所需的基于数据中心的解决方案,以应对当今的挑战。 A40 基于 NVIDIA 安培架构,结合了最新一代 RT 核、张量核和 CUDA 核。它有 48 GB 的图形内存,用于前所未有的图形、渲染、计算和人工智能性能。从功能强大的虚拟工作站到专用的渲染和计算节点, A40 旨在处理来自数据中心的最苛刻的可视化计算工作负载。
有关详细信息,请参阅 NVIDIA A40 。
NVIDIA A30
NVIDIA A30 张量核 GPU 是用于人工智能推理和企业工作负载的最通用的主流计算机 GPU 。具有 MIG 的 Tensor 内核与 165W 低功耗外壳中的快速内存带宽结合在一起,所有这些都采用 PCIe 外形,是主流服务器的理想选择。
A30 是为大规模人工智能推理而构建的,它还可以使用 TF32 快速重新训练人工智能模型,并使用 FP64 张量核加速高性能计算的应用。 NVIDIA 安培体系结构张量内核和 MIG 的结合在不同的工作负载上提供了安全的加速,所有这些都由一个多功能的 GPU 提供动力,实现了弹性数据中心。多功能 A30 计算能力为主流企业提供最大价值。
有关详细信息,请参阅 NVIDIA A30 。
NVIDIA A10
NVIDIA A10 张量核 GPU 是具有人工智能的主流媒体和图形的理想 GPU 。第二代 RT 核和第三代 Tensor 核通过强大的 AI 丰富了图形和视频应用程序。 NVIDIA A10 为密集服务器提供了一个宽、全高、全长 PCIe 外形尺寸和 150W 电源外壳。
NVIDIA A10 Tensor Core GPU 专为具有强大 AI 功能的图形、媒体和云游戏应用程序而设计,可提供丰富的媒体体验。与 NVIDIA T4 张量内核 GPU 相比,它提供了高达 4k 的云游戏,图形性能是 NVIDIA T4 张量内核的 2 . 5 倍,推理性能是 GPU 的 3 倍以上。
有关详细信息,请参阅 NVIDIA A10 。
对 Containerd 的 RuntimeClass 支持
RuntimeClass 为您提供了选择每个 Pod 的容器运行时配置,然后为每个节点上的所有 Pod 应用默认运行时配置的灵活性。通过这种支持,您可以为运行 GPU – 加速工作负载的 pod 指定特定的运行时配置,并为通用工作负载选择其他运行时。
GPU Operator v1 . 7 . 0 现在支持在安装过程中将默认运行时选择为 containerd 时自动创建 nvidia RuntimeClass 。 运行使用 GPU 的应用程序时,可以显式指定此 RuntimeClass 名称。
apiVersion: node.k8s.io/v1beta1 handler: nvidia kind: RuntimeClass metadata: labels: app.kubernetes.io/component: gpu-operator name: nvidia
概括
要立即开始使用 NVIDIA GPU 操作符,请参阅以下参考资料: