如果您使用 pandas,您可能已经撞到了墙壁。正是在这个时刻,您值得信赖的工作流程在处理较小的数据集时表现出色,在处理大型数据集时陷入停顿。曾经需要几秒钟的脚本现在会抓取几分钟。
后续步骤是可以预测的,令人沮丧。您可能会降低数据采样并失去保真度,重写逻辑以分块处理数据,或者面临将整个工作流程迁移到 Spark 等分布式框架的艰巨任务。
但是,如果你能用一面简单的旗帜冲破这堵墙呢?今天,我们将展示三种常见的 pandas 工作流,这些工作流通过切换 GPU 加速的 DataFrame 库 (称为 NVIDIA cuDF) 而得到显著加速。它允许您将 GPU 用于现有工作流程,而无需重写代码。
工作流程 1:使用基于时间窗口分析股价
一项常见的财务分析任务是探索大型时间序列数据集,以发现趋势。这通常涉及一系列 pandas 操作,例如 groupby().agg() 和创建新的日期特征。
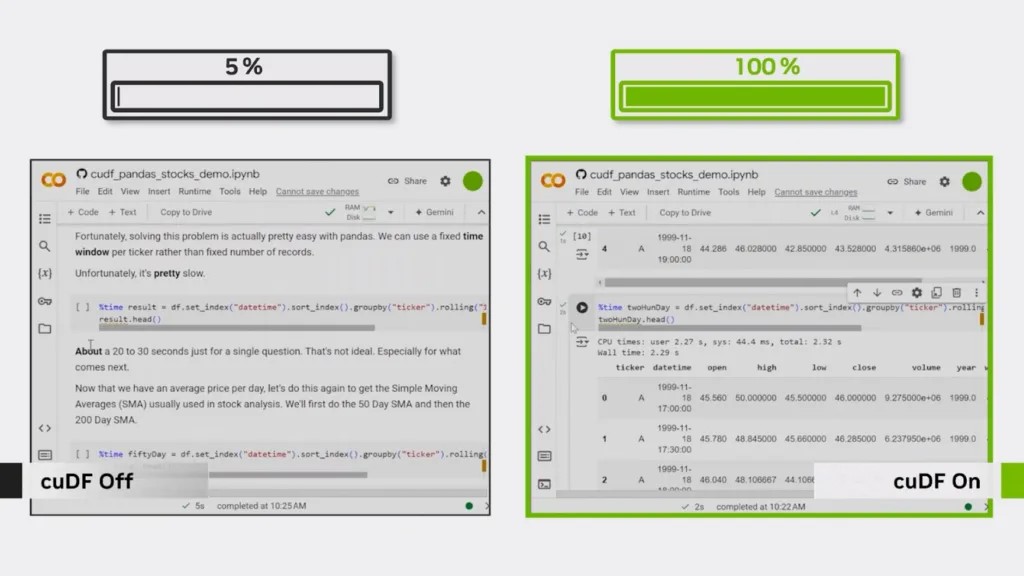
在计算滚动时间段内的指标时,经常会出现真正的瓶颈。使用 groupby () .rolling () 计算 CPU 上“50 天”或“200 天”窗口内的简单移动平均线 (SMA) 可能非常缓慢。
借助 GPU 加速,这些操作的速度最高可提升 20 倍。在 CPU 上花费数分钟的累积工作流在 GPU 上只需几秒钟即可完成。
亲眼见证其中的不同之处:
工作流程# 2:使用大字符串字段分析作业发布
商业智能通常需要分析文本密集型数据,这给 pandas 带来了重大挑战。大字符串列会消耗大量内存 (此工作流的 notebook 会加载 8GB 文件) ,并会导致标准操作非常缓慢。
读取文件 (read_csv) 、计算字符串长度 (.str.len()) 和合并 DataFrame (pd.merge) 等任务会严重拖累性能。然而,这些操作对于回答“哪些公司的工作摘要最长?”等业务问题至关重要
GPU 加速可实现大规模的端到端加速。观看并排对比:
工作流程# 3:构建包含 730 万个数据点的交互式仪表板
数据分析师的主要目标是构建交互式仪表板,以便利益相关者探索数据。任何控制面板的核心都是能够根据用户输入快速筛选数据。
使用 CPU 上的 pandas 时,实时过滤数百万行通常是不可能的。更改日期滑块或从下拉列表中选择值可能会导致延迟、无法使用。此工作流显示的是基于 730 万个手机信号塔位置构建的 panel 控制面板,其中 .between() 和 .isin() 等 pandas 操作由用户单击触发。
借助 GPU 加速,这些过滤操作几乎是瞬时的。因此,即使以交互方式查询数百万个地理空间数据点,仪表板也能提供流畅的体验。
查看控制面板的实际应用:
如果您的 pandas DataFrame 显存大于 GPU 显存,该怎么办?
我们经常会遇到这样的问题:“这太棒了,但如果我的数据集无法容纳 GPU 显存,该怎么办?”
从历史上看,这是一个主要的限制因素。如今,借助统一虚拟内存 (UVM) ,您可以处理比 GPU 的 VRAM ( GPU 的专用显存) 更大的数据集。UVM 可在系统 RAM 和 GPU 显存之间智能地分页数据,让您无需担心显存管理问题,即可处理大量 pandas DataFrame。
请查看此博客了解更多信息或观看下面的视频。
自行试用:相同的代码。速度更快。
正如这些工作流程所示,pandas 中的性能瓶颈不必强制您采用复杂的变通方案。只需激活您可能已有的 GPU,即可解决许多常见的性能问题。
最棒的部分是?借助 NVIDIA cuDF,您只需掌握现有的 pandas 知识即可。以下是有关如何开启它的快速指南。
准备好开始了吗?在我们的 GitHub 资源库中探索这些示例和更多内容。
您是 Polars 用户吗?
Polars 还配备由 NVIDIA cuDF 提供支持的内置 GPU 引擎。阅读由 RAPIDS 提供支持的 Polars GPU 引擎 cuDF 现已在公测版博客中推出,了解更多信息。






