NVIDIA NeMo Retriever
NVIDIA NeMo Retriever™ is an end-to-end, agent-ready stack—including NeMo Retriever Library, Nemotron Retriever open models, and NVIDIA NIM™ microservices — that transforms enterprise documents into a structured knowledge layer special agents can reason over, delivering grounded, accurate, and fast answers informed by your unique enterprise data.
NVIDIA NeMo Retriever Library is an open source, GPU-accelerated ingestion framework that processes terabytes of PDFs, tables, charts, and multimedia at scale — classifying, extracting, and structuring multimodal content into a format agents can directly consume.
NVIDIA Nemotron Retriever open models deliver best-in-class accuracy for extraction, embedding, and reranking. With open weights and fine-tuning recipes, you can adapt them to your specific domain — sharpening retrieval precision on the data that matters most to your business.
These tools are directly callable by AI agents. Use NeMo Retriever skills to give agents the workflow instructions they need to use NeMo Retriever tools — whether your agent is built with an AI agent harness or your own enterprise framework.
These technologies power the RAG Blueprint—a customizable, open starting point for building production-ready RAG applications connected to AI data platforms.
Documentation
Build world-class information retrieval pipelines with scalable data extraction and high-accuracy embedding and reranking starting with the RAG Blueprint.
Extraction
Rapidly ingest massive volumes of data and extract text, graphs, charts, and tables at the same time for highly accurate retrieval.
Embedding
Boost text question-and-answer retrieval performance, providing high-quality embeddings for many downstream natural language processing (NLP) tasks.
Reranking
Enhance retrieval performance further with a fine-tuned reranking model, finding the most relevant passages to provide as context when querying a large language model (LLM).
How NVIDIA NeMo Retriever Works
Build end-to-end data extraction and retrieval pipelines with modular, GPU-accelerated components.
Ingest: Extract text, tables, and charts from structured and unstructured documents, deduplicate and chunk the content.
Embed: Convert chunks into vector embeddings using an NVIDIA Nemotron™ embedding model stored in an NVIDIA cuVS-accelerated vector database for fast indexing and search.
Retrieve and Rerank: On query, perform vector similarity search and rerank results with a Nemotron reranking model for precision.
Generate: Pass top results to Nemotron LLM to produce grounded, contextually relevant responses.
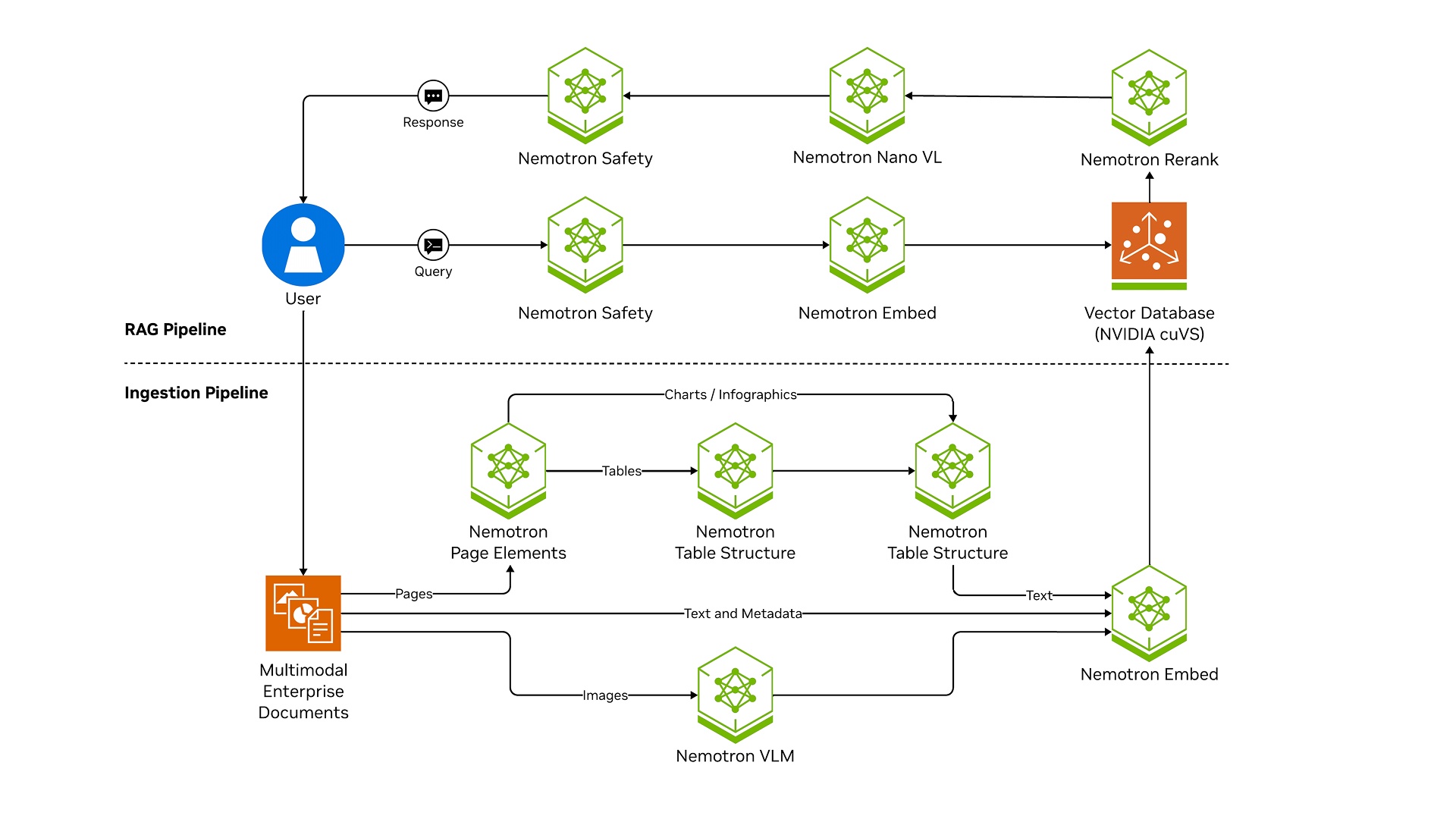
The NVIDIA NeMo Retriever is used to build optimized ingestion and retrieval pipelines for highly accurate information retrieval at scale.
Introductory Resources
Learn more about building an intelligent document processing pipeline with Nemotron.
Nemotron Labs Blog
Learn how AI agents built on NVIDIA Nemotron are transforming PDFs into live insights and NVIDIA’s partners are deploying the technology.
Tech Blog
Get the step-by-step guide on how to build a scalable foundation for multi-agent systems that understand the nuances of your data.
Tutorial Video
Follow a walkthrough in the video on building a scalable, data‑aware foundation for multi‑agent systems.
Hugging Face Blog
Learn how NVIDIA’s ColEmbed models top the ViDoRe V3 leaderboard, reinforcing NVIDIA leadership in retrieval technology—the foundation that powers world‑class intelligent document processing.
World-Class Information-Retrieval Performance
Nemotron accelerates multimodal document extraction and real-time retrieval with lower costs and higher accuracy. It supports reliable, multilingual, and cross-lingual retrieval, and optimizes storage, performance, and adaptability for AI data platforms—enabling efficient vector database expansion.
50% Fewer Incorrect Answers
NeMo Retriever Multimodal Extraction

NIM Off: Open source alternative: HW: 1xH100
NIM On: NeMo Retriever extraction microservices (nemoretriever-page-elements-v2, nemoretriever-table-structure-v1, nemoretriever-graphic-elements-v1, paddle-ocr).
3X Higher Embedding Throughput
Nemotron Embedding

NIM Off: Open source alternative: FP16.
NIM On: NeMo Retriever Llama 3.2 multilingual embedding microservice (llama-3.2-nv-embedqa-1b-v2), FP8.
15X Higher Multimodal Data Extraction Throughput
NeMo Retriever Extraction

NIM Off: Open source alternative.
NIM On: NeMo Retriever extraction microservices (nv-yolox-structured-image-v1, nemoretriever-page-elements-v1, nemoretriever-graphic-elements-v1, nemoretriever-table-structure-v1, PaddleOCR, nv-llama3.2-embedqa-1b-v2).
35x Improved Data Storage Efficiency
Nemotron Embedding
.svg)
Ways to Get Started With NVIDIA NeMo Retriever
Use the right tools and technologies to build and deploy generative AI applications that require secure and accurate information retrieval to generate real-time business insights for organizations across every industry.
Access
Experience Nemotron through a UI-based portal for exploring and prototyping with NVIDIA-managed endpoints, available for free through NVIDIA’s API catalog and deployed anywhere.

Try
Jump-start building your AI solutions with the NVIDIA RAG Blueprint, available on build.nvidia.com.
Starter Kits
Start building information retrieval pipelines and generative AI applications for multimodal data ingestion, embedding, reranking, retrieval-augmented generation, and agentic workflows by accessing NVIDIA Blueprints, tutorials, notebooks, blogs, forums, reference code, comprehensive documentation, and more.
AI Agent for Enterprise Research
Develop AI agents that continuously process and synthesize multimodal enterprise data, reason, plan, and refine to generate comprehensive reports.
Enterprise RAG
Connect secure, scalable, reliable AI applications to your company’s internal enterprise data using industry-leading embedding and reranking models for information retrieval at scale.
Streaming Data to RAG
Unlock dynamic, context-aware insights from streaming sources like radio signals and other sensor data.
Evaluating and Customizing RAG Pipelines
Evaluate pretrained embedding models on data and queries similar to your users’ needs using NVIDIA NeMo microservices to optimize RAG performance.
NVIDIA NeMo Retriever Learning Library
More Resources


Ethical AI
NVIDIA’s platforms and application frameworks enable developers to build a wide array of AI applications. Consider potential algorithmic bias when choosing or creating the models being deployed. Work with the model’s developer to ensure that it meets the requirements for the relevant industry and use case; that the necessary instruction and documentation are provided to understand error rates, confidence intervals, and results; and that the model is being used under the conditions and in the manner intended.