

機械学習 (ML) の活用により、コンピューター システムはアルゴリズムや統計モデルをもとに、大量のデータの中からパターンを見つけ出します。このようなパターンを認識できるモデルを活用することで、新しいデータの予測や説明が可能になります。
現在、小売、ヘルスケア、運輸、金融など、ほぼすべての業界で ML が活用されており、顧客満足度、生産性、運用効率を改善しています。しかし、新しいツールやテクノロジを試す環境は、簡単に利用できるものではありません。単にアクセスが難しいだけでなく、不可能な場合もあります。
今回は、順を追って、データ処理から、モデルのトレーニング、推論まで、RAPIDS を利用してエンドツーエンドの ML サービスを構築する方法を説明します。NGC カタログの新機能であるワンクリック デプロイにより、ユーザーがインフラストラクチャをスピン アップしてパッケージをインストールすることなく、ノートブックにアクセスしたり、ML パイプラインを試したりできます。
AI ソフトウェアとインフラストラクチャでアプリケーション開発を加速する
データ サイエンス アプリケーションを構築した経験がある方なら、RAPIDS の活用方法を 9 割ほど理解しているはずです。
RAPIDS: 機械学習の高速化
RAPIDS はオープンソースのソフトウェア ライブラリ スイートで、エンドツーエンドのデータ サイエンスおよび分析のパイプラインを完全に GPU 上で構築および実行できます。RAPIDS Python API は、pandas や scikit-learn など、馴染みのあるデータ サイエンス ツールと使用感が似ているため、最小限のコード変更のみでさまざまなメリットを得られます。
RAPIDS は、データを直接 GPU に取り込み、探索や特徴量エンジニアリング、モデルのトレーニングを行うことで、現代のデータ サイエンス ワークフローにおけるボトルネックを解消します。これにより ML ワークフローの初期段階をすばやく反復できるため、限られた時間内に GPU でより先進的な手法を試せるようになります。
RAPIDS は、XGBoost などの認知度の高いフレームワークとも統合されています。XGBoost は、勾配ブースティング決定木を使ってトレーニングや推論を実行する API を提供しています。
NGC カタログ: GPU に最適化されたソフトウェアのためのハブ
NVIDIA の NGC カタログは、GPU に最適化された AI や ML のフレームワーク、SDK、学習済みモデルを提供します。また、サンプルの Jupyter Notebooks をホストし、今回ご紹介するサンプルをはじめとするさまざまなアプリケーションをご用意しています。このたび、Vertex AI Workbench で一度クリックするだけで、ノートブックを簡単にデプロイできるようになりました。
Google Cloud Vertex AI: GPU アクセラレーテッド クラウド プラットフォーム
Google Cloud の Vertex AI Workbench はデータ サイエンス ワークフロー全体の単一開発環境です。データ エンジニアリングを高速化するために、必要なすべてのサービスを緊密に統合し、運用環境でのモデルの構築とデプロイをすばやく実行します。
NVIDIA と Google Cloud が共同で開発したワンクリック機能は、Vertex AI での 最適な JupyterLab インスタンスの立ち上げ、ソフトウェア依存関係の事前読み込み、NGC ノートブックのダウンロードなどをワンクリックで実行します。開発環境を設定する専門知識を持たないユーザーでも、すぐにコードを実行できます。
Google Cloud アカウントをお持ちでない場合は、サイン アップして無料クレジットを取得することで、アプリケーションを構築して実行できます。
構築方法
GPU アクセラレーション対応のデータ サイエンスを開始する手順を解説します。
環境にアクセスする
まず、以下の前提条件を満たしていることを確認しましょう。
- NGC アカウントに登録し、サイン インしている。
- Google Cloud Platform アカウントに登録し、サイン インしている。
NGC にサイン インすると、厳選されたコンテンツが表示されます。
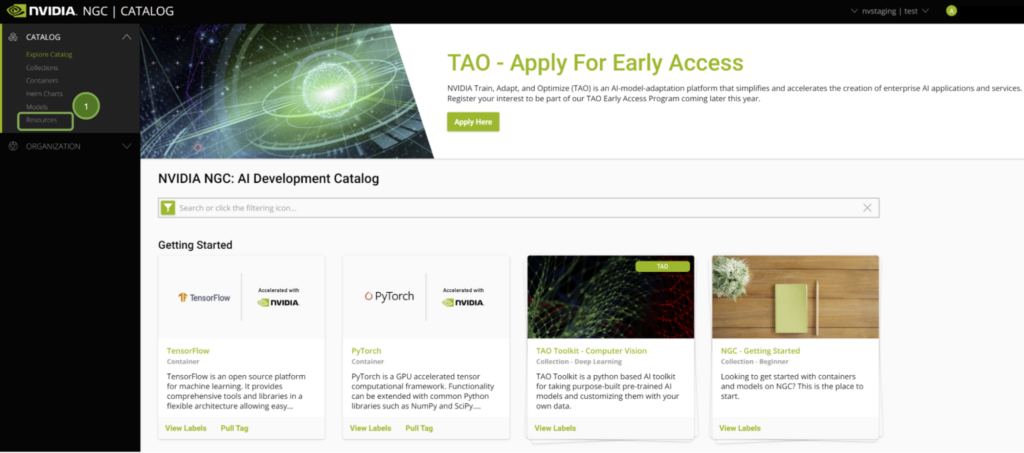
NGC の Jupyter Notebooks はすべて [Resources] タブからアクセスできます。Introduction to End-to-End RAPIDS Workflows をご参照ください。このページには、RAPIDS ライブラリについての情報や、ノートブックの概要が記載されています。
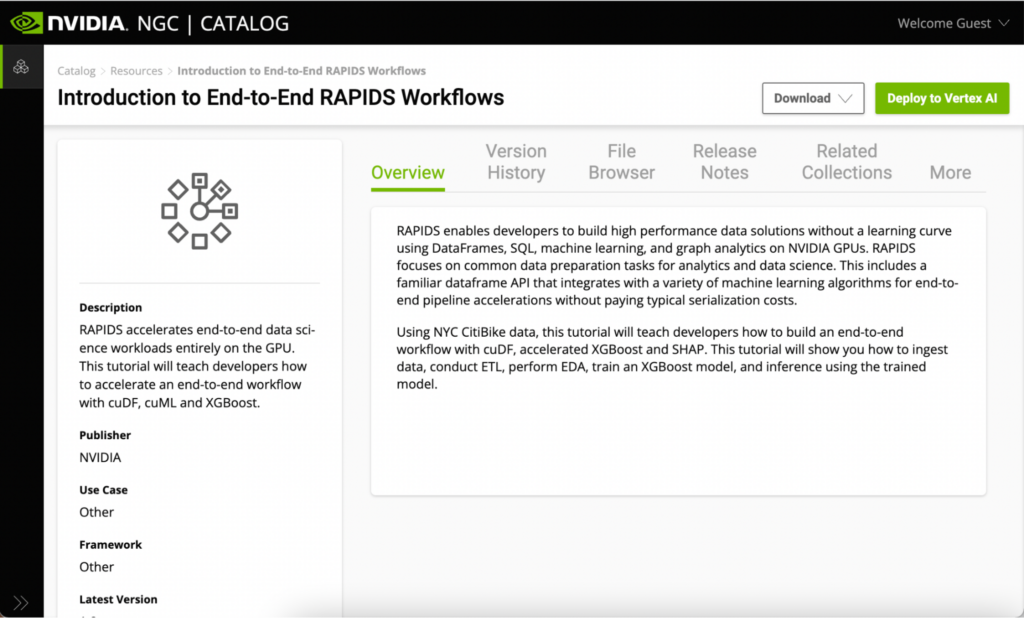
このリソースからサンプルの Jupyter Notebooks を使用する方法は 2 つあります。
- リソースをダウンロードする
- ワンクリックで Vertex AI にデプロイする
GPU を利用できるローカルまたはクラウド環境が既に整備されている場合は、お持ちのインフラストラクチャにリソースをダウンロードして実行できます。今回は、ワンクリック デプロイ機能を使って Vertex AI 上でノートブックを実行します。インフラストラクチャを手動でインストールする必要はありません。
ワンクリック デプロイ機能では、Jupyter Notebook の取得、GPU インスタンスの設定、依存関係のインストールなどを行ってから、JupyterLab インターフェイスを実行します。
管理ノートブックの設定
簡単なチュートリアルに従い、環境が正しく設定されていることを確認します。
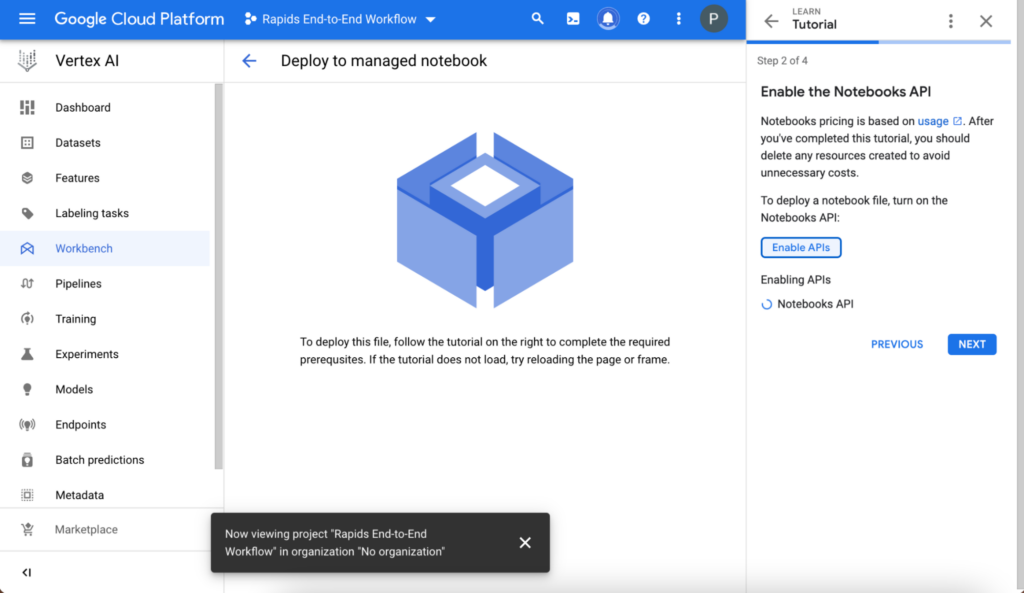
プロジェクトを作成して名前を付けます。プロジェクトの作成後、[Select a project] フィールドでそのプロジェクトを選択します。プロジェクト名の下に自動的に表示されるプロジェクト ID 値をメモしておきます。この ID 値は後で必要になります。
次に Notebooks API を有効化します。
ハードウェアの設定
[Create] を選択してノートブックをデプロイする前に、[Advanced settings] を選択します。以下の情報が事前に設定されていますが、リソースの要件に合わせてカスタマイズできます。
- ノートブック名
- 地域
- Docker コンテナの環境
- マシン タイプ、GPU タイプ、GPU 数
- ディスク タイプ、データ サイズ
デプロイ前に以下を確認してください。
- 事前に設定された対象の地域で GPU を利用できること。GPU を利用できない場合は警告画面が表示され、地域を変更する必要があります。
- [Install GPU driver for me automatically] ボタンがチェックされていること。
上記を満たしており、GPU とドライバの用意ができたら、画面の下部にある [Create] を選択します。GPU コンピュート インスタンスを作成し、JupyterLab 環境を設定するには、数分間かかります。
Jupyter を使用する
[Open] -> [Open JupyterLab] の順に選択して、インターフェイスを開きます。JupyterLab インターフェイスは、NGC からリソース (カスタム コンテナと Jupyter Notebooks) を取得します。カーネルの取得には時間がかかることがあります。
読み込みが完了すると、カーネルの選択画面で RAPIDS のカーネルを選択できるようになります。カーネルの読み込み後、左ペインでノートブック名をダブルクリックしてください。
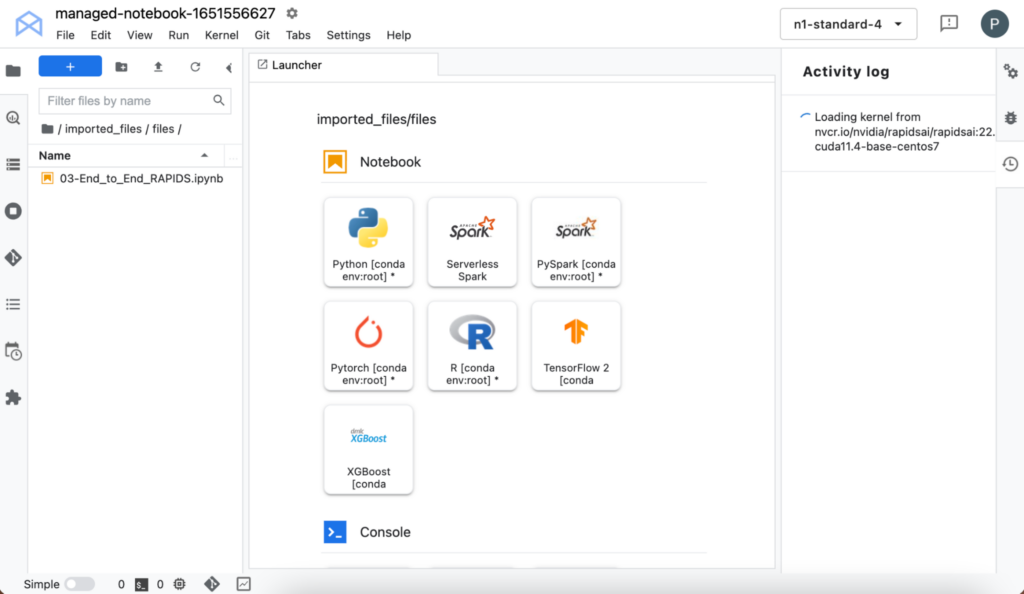
自分でインフラストラクチャを設定することなく、RAPIDS ライブラリがインストールされたノートブック環境にアクセスできるようになりました。ご自身で使用感をお試しいただけます。
ワークフローとの連携
今回のプロジェクトでは、ニューヨーク市の CitiBike シェア サイクル プログラムのデータを使用します。詳細はノートブックをご覧ください。
データ処理に進む前に、NVIDIA SMI コマンドを使って GPU の詳細情報を確認できます。VertexAI に、16 GB メモリの V100 や T4 GPU などが割り当てられていることがわかります。
Google BigQuery のデータを読み込むために、ライブラリを 2 つインストールする必要があります。このデータ セットは BigQuery でパブリックに公開されているため、読み込むための認証情報は必要ありません。Python API を使って、大きなクエリからデータを読み込みます。
次に、データを cuDF データ フレームに変換します。cuDF は、GPU 上でデータの変換、読み込み、集約などを効率的に実行するのに必要なものをすべて提供する RAPIDS GPU DataFrame ライブラリです。cuDF データ フレームは GPU に格納され、残りの作業もそこで行われます。これにより、GPU の処理速度を活かし、CPU と GPU の間でデータを行き来させることによるコストを低減することで、大幅なスピード アップを実現します。
ノートブックを実行する前に、コマンド os.environ.setdefault のコメントを解除し、プロジェクトの ID を 2 番目の引数に挿入します。設定時にプロジェクトに割り当てられた ID を忘れてしまった場合は、プロジェクトを選択した後に Workbench のメイン ページを確認します。使用するのは名前ではなく ID であることに注意してください。
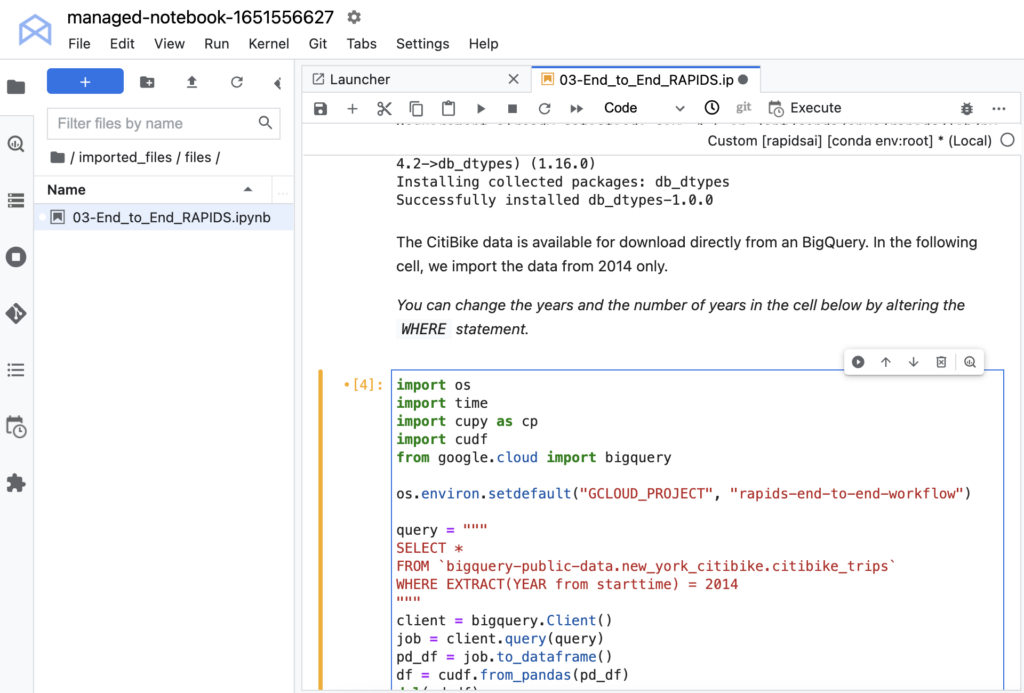
これでデータの読み込みは完了です。読み込まれたデータをチェックし、データ タイプや特徴量のサマリを確認できます。それぞれのエントリには、開始時間、終了時間、自転車を受け取るステーション ID、自転車を返却するステーション ID が表示されます。また、その他の自転車情報、受け取りと返却の場所、ユーザー属性なども確認できます。
データの処理
次のセルでは、データを処理して特徴ベクトルを作成します。これにより、重要な情報を取得して ML モデルをトレーニングできるようになります。
開始時間を処理して、自転車が貸し出された曜日や時間帯などの情報を抽出します。自転車の受け取りの時点で利用時間を予測することが目的であるため、利用終了に関する情報を含むデータの特徴はすべて削除します。
また、不具合ですぐに返却されたような極端に短い利用記録や、10 時間を超える極端に長い利用記録も削除します。CitiBike は市内での比較的短時間の利用を想定しており、長時間の利用には適していません。こうしたデータによってモデルの精度が損なわれないようにします。
cuDF に組み込まれた時間機能を使って、自転車のチェックアウト時間に関する詳細情報を取得します。そのほか、cuML を使って特定のテキスト変数のラベル エンコーディングの自動作成も実行します。
モデルのトレーニング
次に、XGBoost でモデルをトレーニングします。XGBoost は、勾配ブースティング決定木によって、トレーニングと推論を実行する API を提供します。
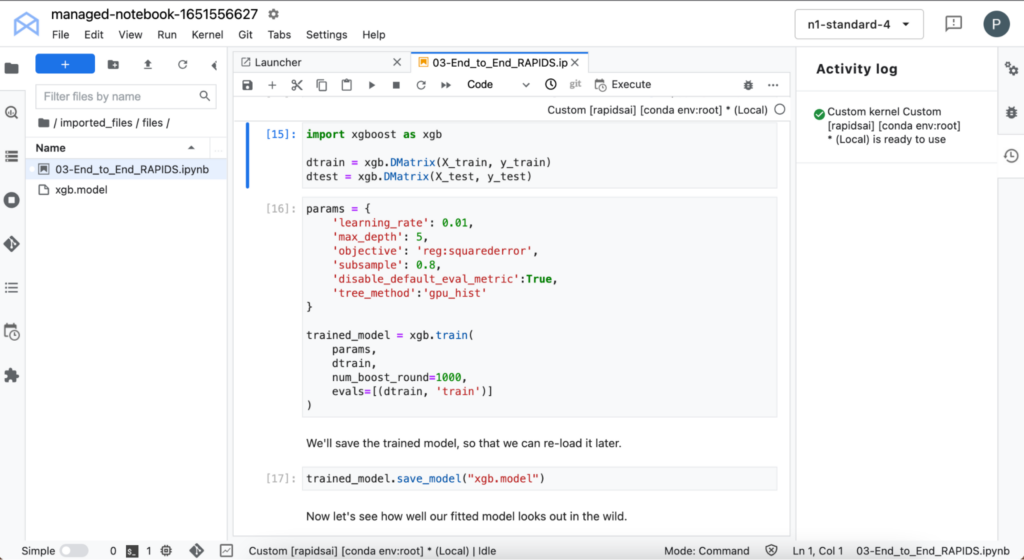
トレーニングは GPU 上で実行されるため、非常に高速です。データは cuDF から直接読み込めるため、フォーマットを変更する必要はありません。
これでモデルのトレーニングは完了です。このモデルを使って、トレーニングに使用されていないデータの乗車時間を予測し、グラウンド トゥルースと比較してみましょう。ハイパーパラメーターを調整しなくても、モデルは乗車時間を合理的に予測しているはずです。予測に改善の余地がある場合もありますが、現時点でモデルの予測に影響を与えている特徴量を確認しましょう。
モデルの説明
XGBoost のような複雑なモデルを使用している場合、モデルによる予測を簡単に理解できないこともあります。このセクションでは、SHapley Additive exPlanation (SHAP) 値を使って、ML モデルのインサイトを取得します。
SHAP 値の算出は計算負荷の高いプロセスですが、NVIDIA GPU 上で実行することで処理を高速化できます。さらに時間を節約するために、データのサブセット上で SHAP 値を算出します。
次に、個々の特徴量による影響や、特徴量の組み合わせについて確認しましょう。
推論の高速化
モデルのトレーニングなど、ワークフローの中でも計算負荷が高いとされている処理で、GPU は価値を発揮します。実際、その通りです。しかし、GPU は一部のモデルでの予測にかかる時間も大幅に短縮できます。
XGBoost は先ほどの予測をキャッシュしているため、モデルをリロードできます。CPU と GPU の両方で予測を行う場合は、時間を計測してください。
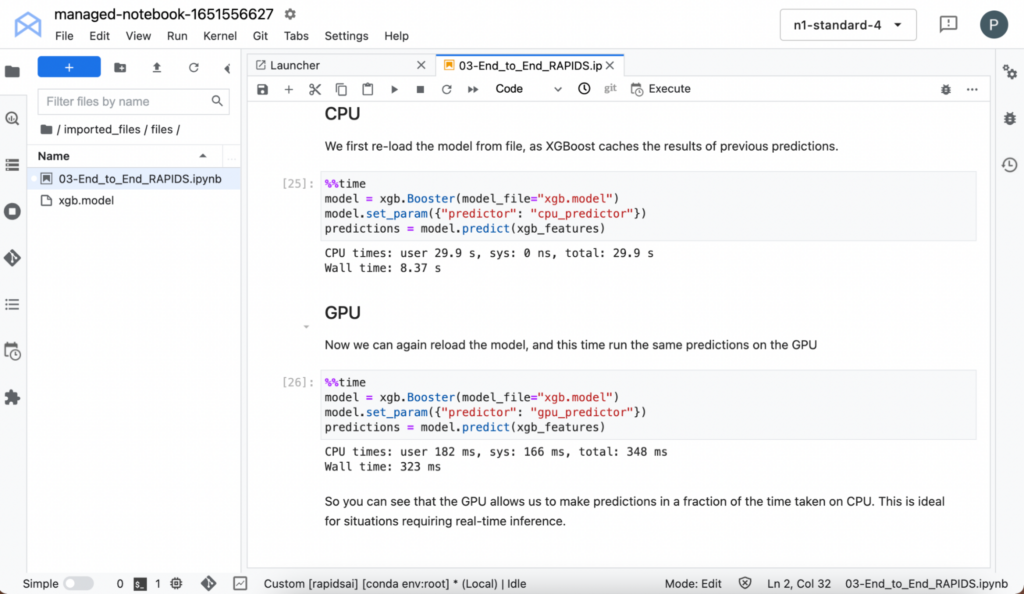
このように小さなデータとシンプルなモデルでも、GPU で実行すると推論時間が大幅に短縮されることがわかります。
まとめ
RAPIDS で GPU 上のエンドツーエンドのワークフローを実現すれば、より複雑な手法を検討したり、データに関するインサイトをすばやく入手したりできるようになります。
NGC カタログのワンクリック デプロイ機能を活用すれば、RAPIDS を備える環境に数分でアクセスして、ML のパイプラインを開発できます。インフラストラクチャをスピン アップしたり、ライブラリをインストールしたりする必要はありません。
RAPIDS は簡単に始められます。今回ご紹介した構築手順ならば、インフラストラクチャの設定要らずで、データ サイエンスにかかわるあらゆる作業をスピード アップできます。
RAPIDS の情報を入手するには Twitter で RAPIDS チームをフォローしてください。また、NGC カタログを検索して、簡単にデプロイできるモデルやサンプル情報を入手していただけます。