NVIDIA Dynamo
NVIDIA Dynamo is an open source, low-latency, modular inference framework for serving generative AI models in distributed environments. It enables seamless scaling of inference workloads across large GPU fleets with intelligent resource scheduling and request routing, optimized memory management, and seamless data transfer. It supports open source inference engines including SGLang, TensorRT™ LLM, and vLLM and simplifies the complexities of distributed serving by disaggregating the various phases of inference across different GPUs, intelligently routing requests to the appropriate GPU to avoid redundant computation, and extending GPU memory through data caching to cost-effective storage tiers.
Independent benchmarks show that GB300 NVL72 combined with NVIDIA Dynamo improves mixture-of-experts (MoE) model throughput by up to 50x compared to NVIDIA Hopper™-based systems.
The GB300 NVL72 connects 72 GPUs via high-speed NVIDIA NVLink™, enabling low-latency expert communication critical for MoE reasoning models. NVIDIA Dynamo enhances efficiency through disaggregated inference, splitting prefill and decode phases across nodes for independent optimization. Together, GB300 NVL72 and NVIDIA Dynamo form a high-performance stack optimized for large-scale MoE inference.
NVIDIA Dynamo builds on the successes of the NVIDIA Triton Inference Server™, an open-source software that standardizes AI model deployment and execution across every workload.
See NVIDIA Dynamo in Action
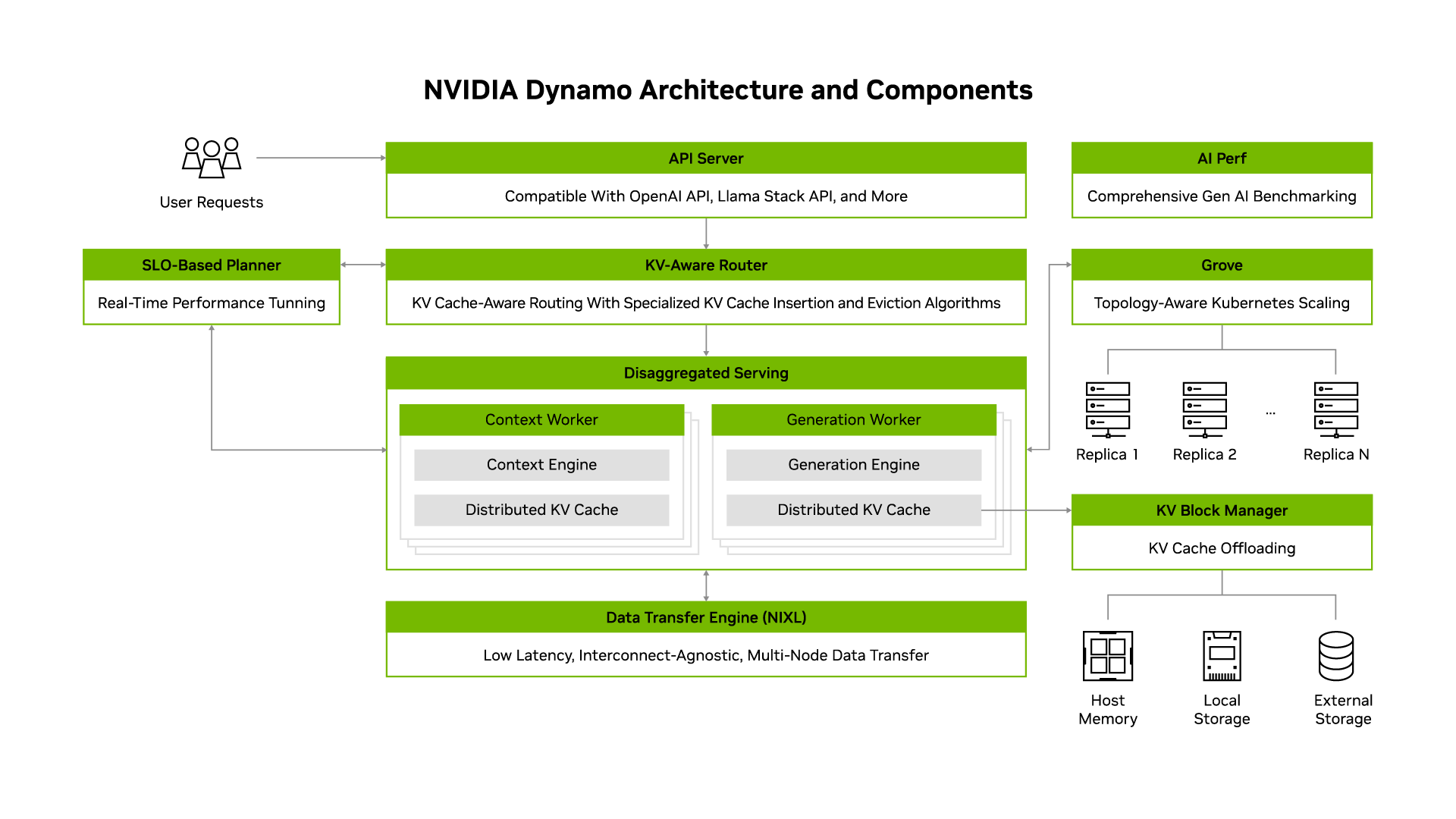
How NVIDIA Dynamo Works
Models are becoming larger and more integrated into AI workflows that require interaction with multiple models. Deploying these models at scale involves distributing them across multiple nodes, requiring careful coordination across GPUs. The complexity increases with inference optimization methods, like disaggregated serving, which splits responses across different GPUs, adding challenges in collaboration and data transfer.
NVIDIA Dynamo addresses the challenges of distributed and disaggregated inference serving. It includes the following key components:
SLO Planner: A planning and scheduling engine that monitors capacity and prefill activity in multi-node deployments adjusting GPU resources to consistently meet Service Level Objectives (SLO).
-
KV-aware Router: A KV-cache-aware routing engine that efficiently directs incoming traffic across large GPU fleets in multi-node deployments to minimize redundant KV Cache re-computations.
Low-Latency Communication Library (NIXL): low latency point-to-point inference data transfer library that accelerates the transfer of KV cache between GPUs and across heterogeneous memory and storage types.
KV Block Manager: A cost-aware KV caching engine that transfers KV cache across various memory hierarchies, freeing up GPU memory while maintaining user experience.
Grove: A modular component of Dynamo that simplifies deploying hierarchical gang-scheduled and topology‑aware AI workloads on Kubernetes
AI Perf: a comprehensive benchmarking tool that measures the performance of generative AI models served by SGLang, TensoRT-LLM and vLLM.

NVIDIA Dynamo Key Moments
A series of live NVIDIA Dynamo Office Hours sessions where developers can ask questions, share feedback, and learn directly from the team. Each episode covers topics related to Dynamo and inference, helping you build, optimize, and deploy AI models.
Watch Now
Get Started With NVIDIA Dynamo
Quick-Start Guide
Learn the basics for getting started with NVIDIA Dynamo, including how to deploy a model in a disaggregated server setup and how to launch the smart router.
Dynamo 1.0 Blog
This blog details how early adopters have integrated Dynamo into real-world inference workflows, the system level performance improvements achieved, and the latest features and optimizations added to the framework.
Deploy LLM Inference With NVIDIA Dynamo and vLLM
NVIDIA Dynamo supports all major backends, including vLLM. Check out the tutorial to learn how to deploy with vLLM.
Multi-Node Deployment With NVIDIA Dynamo and Grove on Kubernetes
Learn how to deploy multi-node models using NVIDIA Dynamo with Grove API, which enables efficient scaling and declarative startup ordering of interdependent AI inference components across multiple nodes.
Introductory Blog
Read about how NVIDIA Dynamo helps simplify AI inference in production, the tools that help with deployments, and ecosystem integrations.
Get Started With NVIDIA Dynamo
Find the right license to deploy, run, and scale AI inference for any application on any platform.
Download Code for Development
NVIDIA Dynamo is available as open source software on GitHub with end-to-end examples.
NVIDIA Dynamo is the successor to NVIDIA Triton Inference Server. The link to the earlier Triton Inference Server GitHub is here.
Purchase NVIDIA AI Enterprise
NVIDIA AI Enterprise will include NVIDIA Dynamo for production inference in a future release. Get a free license to try NVIDIA AI Enterprise in production for 90 days using your existing infrastructure.
Starter Kits
Access technical content on inference topics like prefill optimizations, decode optimizations, and multi-GPU inference.
Multi-GPU Inference
Models have grown in size and can no longer fit on a single GPU. Deploying these models involves distributing them across multiple GPUs and nodes. This kit shares key optimization techniques for multi-GPU inference.
Prefill Optimizations
When a user submits a request to a large language model, it generates a KV cache to compute a contextual understanding of the request. This process is computationally intensive and requires specialized optimizations. This kit presents essential KV cache optimization techniques for inference.
Decode Optimizations
Once the LLM generates the KV cache and the first token, it moves into the decode phase, where it autoregressively generates the remaining output tokens. This kit highlights key optimization techniques for the decoding process.
Topology-Optimized Serving on Kubernetes
AI workloads have evolved into complex multi-component systems spanning multiple nodes. Grove bridges AI inference frameworks and Kubernetes scheduling, enabling efficient scaling and declarative startup ordering of interdependent components through unified custom resources. This kit introduces Grove's capabilities and guides you through topology-optimized model deployment on Kubernetes.
NVIDIA Blackwell Ultra Delivers up to 50x Better Performance and 35x Lower Cost for Agentic AI
Built to accelerate the next generation of agentic AI, NVIDIA Blackwell Ultra delivers breakthrough inference performance with dramatically lower cost. Cloud providers such as Microsoft, CoreWeave, and Oracle Cloud Infrastructure are deploying NVIDIA GB300 NVL72 systems at scale for low-latency and long-context use cases, such as agentic coding and coding assistants.
This is enabled by deep co-design across NVIDIA Blackwell, NVLink™, and NVLink Switch for scale-out; NVFP4 for low-precision accuracy; and NVIDIA Dynamo and TensorRT™ LLM for speed and flexibility—as well as development with community frameworks SGLang, vLLM, and more.

More Resources


Ethical AI
NVIDIA believes trustworthy AI is a shared responsibility, and we have established policies and practices to support the development of AI across a wide array of applications. When downloading or using this model in accordance with our terms of service, developers should work with their supporting model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards. Please report security vulnerabilities or NVIDIA AI concerns here.